redis序列化及各种序列化情况划分
目录
- 序列化基本
- 序列化各种情况区分
- 情况一:类没有序列化,直接存储一个javabean对象 结果:报错
- 情况二:类序列化,直接存储一个javebean对象 结果:控制台正常显示,黑窗口乱码
- 情况三 使用jackon序列化(自定义的序列化) 内容正常输出。
- 情况四 正常使用时,我们通常把我们的对象转换成json存储,并不会直接存储某一个java对象。
序列化基本
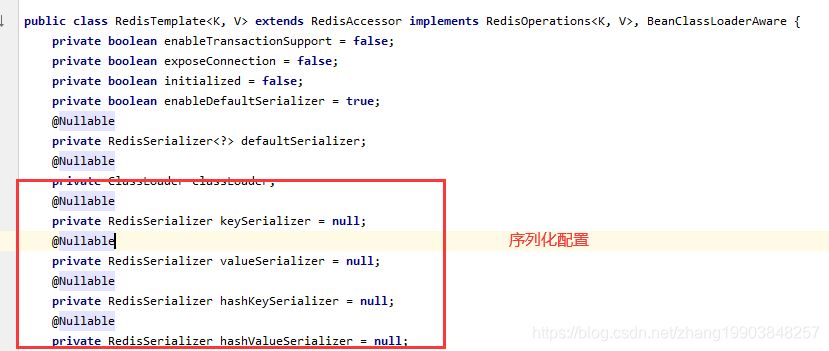
默认使用的是jdk序列化 会使字符串转义
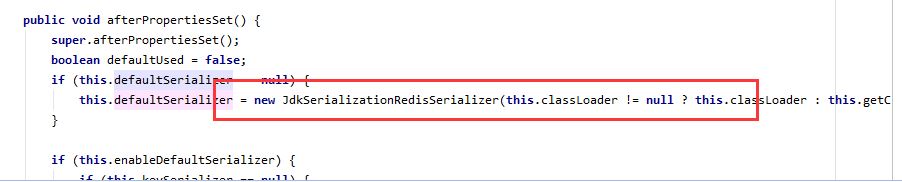
在实际开发中,当我们要往redis中存对象时,都要进行序列化的。
- 当然,如果我们把对象给转换json字符串,此时存储的相当于是字符串。不序列化并不影响正常运行
- 但是,通常我们都要把我们创建的对象给序列化。
- 假如我们不序列化,存储对象
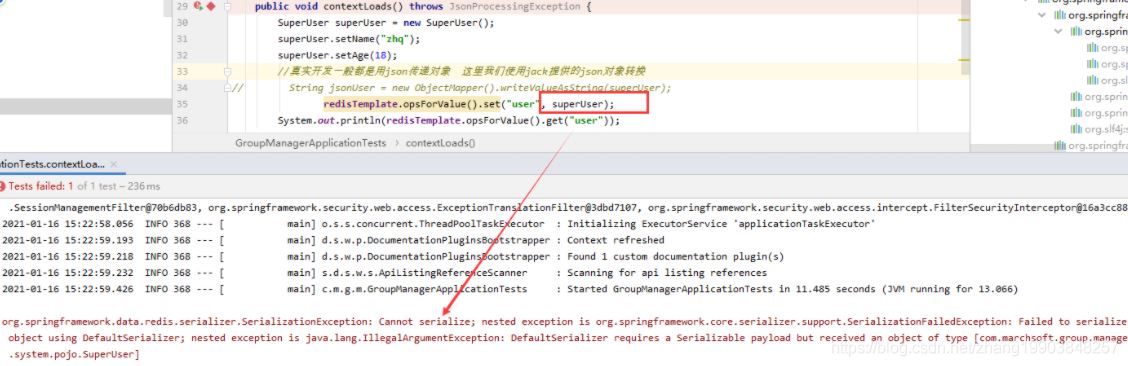
在实际开发中我们可能使用json去转换,我们还不想使用jdk序列化(默认的是jdk序列化) 。 此时我们就需要使用配置类了。
我们创建一个redisTemplate对象,覆盖bean容器中原有的redis template对象。
序列化各种情况区分
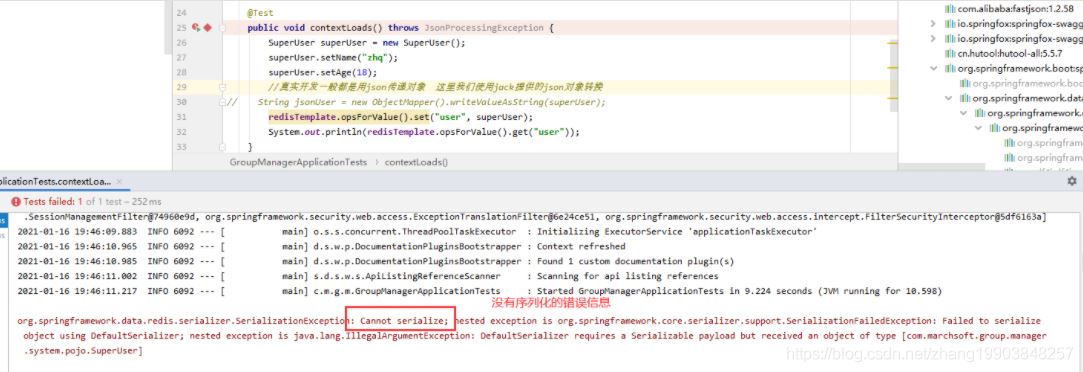
情况一:类没有序列化,直接存储一个javabean对象 结果:报错
a.
b.

c.
d. 没有序列化,转换为json对象存储。 控制台正常,黑窗口乱码
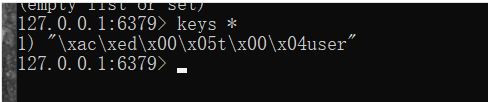
e. 序列化,转换为json对象存储。 黑窗口乱码。
情况二:类序列化,直接存储一个javebean对象 结果:控制台正常显示,黑窗口乱码
a.

b.


c.

情况三 使用jackon序列化(自定义的序列化) 内容正常输出。
a.
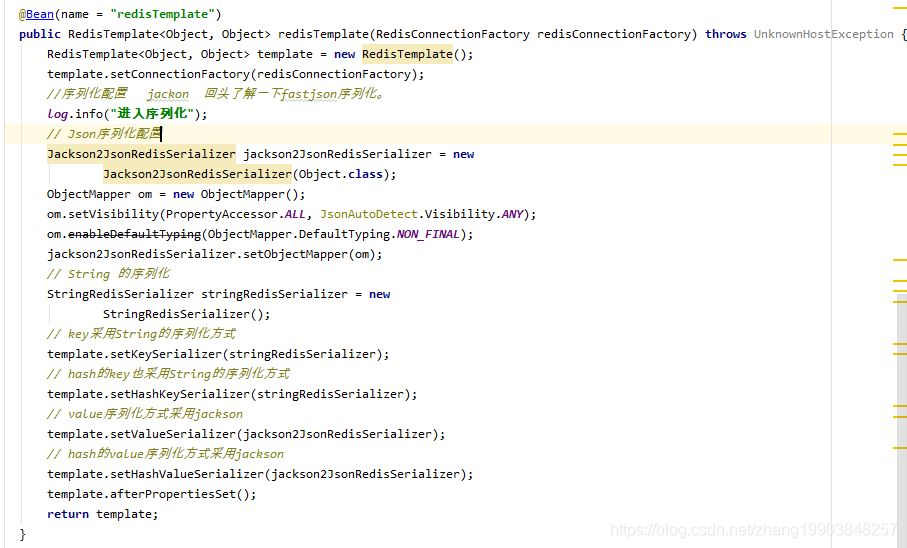
b.

情况四 正常使用时,我们通常把我们的对象转换成json存储,并不会直接存储某一个java对象。
a. 我们同上使用情况三的使用方式
b. 所有的对象,都要进行序列化,即实现
到此这篇关于redis序列化及各种序列化情况划分的文章就介绍到这了,更多相关redis序列化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

深入理解 Redis Template及4种序列化方式
概述 使用Spring 提供的 Spring Data Redis 操作redis 必然要使用Spring提供的模板类 RedisTemplate, 今天我们好好的看看这个模板类 . RedisTemplate 看看4个序列化相关的属性 ,主要是 用于 KEY 和 VALUE 的序列化 . 举个例子,比如说我们经常会将POJO 对象存储到 Redis 中,一般情况下会使用 JSON 方式序列化成字符串,存储到 Redis 中 . Spring提供的Redis数据结构的操作类 ValueOpera
-
解决RedisTemplate的key默认序列化器的问题
redis的客户端换成了spring-boot-starter-data-redis,碰到了一个奇怪的问题, 在同一个方法中 1.先hset,再hget,正常获得数据. 在不同的方法中 先hset,再hget获取不到数据,通过redis的monitor监控发现了命令的问题: 实际我的key为JK_HASH:csrk,hashkey为user,但是根据上图所示,实际执行的命令多了好多其他字符,这是什么原因呢? 在服务器端先确认发现实际有这个Hash,通过hset可以得到正确的数据,所以第一次执行h
-
Redis缓存-序列化对象存储乱码问题的解决
使用Redis缓存对象会出现下图现象: 键值对都是乱码形式. 解决以上问题: 如果是xml配置的 我们直接注入官方给定的keySerializer,valueSerializer,hashKeySerializer即可: <bean id="apiRedisTemplate" class="org.springframework.data.redis.core.RedisTemplate" p:connection-factory-ref="apiC
-
关于redisson缓存序列化几枚大坑说明
redisson缓存序列化几枚坑 1.返回值为Map<T, K> 的方法增加@Cacheable后,T和K被类型擦出了,为啥? redisson结合Spring使用时,会有RedissonSpringCacheManager,将redissonClient自动注入,另外还有codec的概念,即序列化和反序列化,可以查看实现类,就几种实现,假设我们使用org.redisson.codec.JsonJacksonCodec,可以看到,decode中,仅一个Object.class,即范型信息并未带
-
Redis之RedisTemplate配置方式(序列和反序列化)
RedisTemplate配置 序列和反序列化 对于redis操作,springboot进行了很好的封装,那就是spring data redis.提供了一个高度封装的RedisTemplate类来进行一系列redis操作,连接池自动管理:同时将事务封装操作,交由容器进行处理. 针对数据的“序列化和反序列化”,提供了多种策略(RedisSerializer) 默认为使用JdkSerializationRedisSerializer,同时还有StringRedisSerializer,Jackso
-
redis序列化及各种序列化情况划分
目录 序列化基本 序列化各种情况区分 情况一:类没有序列化,直接存储一个javabean对象 结果:报错 情况二:类序列化,直接存储一个javebean对象 结果:控制台正常显示,黑窗口乱码 情况三 使用jackon序列化(自定义的序列化) 内容正常输出. 情况四 正常使用时,我们通常把我们的对象转换成json存储,并不会直接存储某一个java对象. 序列化基本 默认使用的是jdk序列化 会使字符串转义 在实际开发中,当我们要往redis中存对象时,都要进行序列化的. 当然,如果我们把对象给转换
-
SpringBoot整合redis中的JSON序列化文件夹操作小结
目录 前言 快速配置 JSON序列化 jackson序列化 Fastjson序列化 分析参考对比 更多问题参考 redis数据库操作 前言 最近在开发项目,用到了redis作为缓存,来提高系统访问速度和缓解系统压力,提高用户响应和访问速度,这里遇到几个问题做一下总结和整理 快速配置 SpringBoot整合redis有专门的场景启动器整合起来还是非常方便的 <dependency> <groupId>org.springframework.boot</groupId>
-
SpringBoot Redis配置Fastjson进行序列化和反序列化实现
FastJson是阿里开源的一个高性能的JSON框架,FastJson数据处理速度快,无论序列化(把JavaBean对象转化成Json格式的字符串)和反序列化(把JSON格式的字符串转化为Java Bean对象),都是当之无愧的fast:功能强大(支持普通JDK类,包括javaBean, Collection, Date 或者enum):零依赖(没有依赖其他的任何类库). 1.写一个自定义序列化类 /** * 自定义序列化类 * @param <T> */ public class FastJ
-
java原生序列化和Kryo序列化性能实例对比分析
简介 最近几年,各种新的高效序列化方式层出不穷,不断刷新序列化性能的上限,最典型的包括: 专门针对Java语言的:Kryo,FST等等 跨语言的:Protostuff,ProtoBuf,Thrift,Avro,MsgPack等等 这些序列化方式的性能多数都显著优于hessian2(甚至包括尚未成熟的dubbo序列化).有鉴于此,我们为dubbo引入Kryo和FST这 两种高效Java序列化实现,来逐步取代hessian2.其中,Kryo是一种非常成熟的序列化实现,已经在Twitter.Group
-
浅谈Java序列化和hessian序列化的差异
在远程调用中,需要把参数和返回值通过网络传输,这个使用就要用到序列化将对象转变成字节流,从一端到另一端之后再反序列化回来变成对象. 既然前面有一篇提到了hessian,这里就简单讲讲Java序列化和hessian序列化的区别. 首先,hessian序列化比Java序列化高效很多,而且生成的字节流也要短很多.但相对来说没有Java序列化可靠,而且也不如Java序列化支持的全面.而之所以会出现这样的区别,则要从它们的实现方式来看. 先说Java序列化,具体工作原理就不说了,Java序列化会把要序列化
-
Python常用标准库详解(pickle序列化和JSON序列化)
目录 常用的标准库 序列化模块 序列化和反序列化 使用场景 dumps & loads dump & load JSON序列化模块 使用场景 支持的数据类型 JSON和pickle的区别 序列化函数 json和pickle实际使用过程中的一些问题 pickle和json的区别总结 常用的标准库 序列化模块 import pickle 序列化和反序列化 把不能直接存储的数据变得可存储,这个过程叫做序列化.把文件中的数据拿出来,回复称原来的数据类型,这个过程叫做反序列化. 在文件中存储的数据只
-
浅谈Redis阻塞的9种情况
目录 命令阻塞 SAVE 阻塞 同步持久化 AOF 重写 AOF 日志 大 Key 问题 查找大 key 删除大 key 清空数据库 集群扩容 前两天去美团面试的陈同学回来了,看他满脸泄气的样子,准是没拿到 Offer. 听了他面试的经过,真替他感到惋惜.究其原因,是被一道面试题拦住了去路:看你简历上写着精通 Redis,请你总结一下 Redis 中存在的阻塞问题吧. 正好阿Q这几天正在研究 Redis,就顺便在这儿给大家做个总结. 命令阻塞 使用不当的命令造成客户端阻塞: keys * :获取
-
.NET Core中使用Redis与Memcached的序列化问题详析
前言 在使用分布式缓存的时候,都不可避免的要做这样一步操作,将数据序列化后再存储到缓存中去. 序列化这一操作,或许是显式的,或许是隐式的,这个取决于使用的package是否有帮我们做这样一件事. 本文会拿在.NET Core环境下使用Redis和Memcached来当例子说明,其中,Redis主要是用StackExchange.Redis,Memcached主要是用EnyimMemcachedCore. 先来看看一些我们常用的序列化方法. 常见的序列化方法 或许,比较常见的做法就是将一个对象序列
-
SpringBoot集成Redis,并自定义对象序列化操作
SpringBoot项目使用redis非常简单,pom里面引入redis的场景启动器,在启动类上加@EnableCaching注解,项目启动会自动匹配上redis,这样项目中就可以愉快地使用了, 使用方法:要么使用@Cacheable一类的注解自动缓存,要么使用RedisTemplate手动缓存. (前提是你的本机或者是远程主机要先搭好redis环境) 虽然SpringBoot好用,但这里也有好多坑,SpringBoot和MySQL一样,易学难精,阳哥说的对,练武不练功,到老一场空. 下面,我将
-
springBoot集成redis的key,value序列化的相关问题
使用的是maven工程 springBoot集成redis默认使用的是注解,在官方文档中只需要2步; 1.在pom文件中引入即可 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-redis</artifactId> </dependency> 2.编写一个CacheService接口,使用redisCach