详解节点监控相对准确的计算FMP
目录
- 引言
- 如何监控节点
- 监控变化
- 节点标记
- 什么时间计算?
- 为什么?
- 怎么筛选元素?
- 计算权重得分
- 基础节点
- 父节点
- 排除干扰项
- 不可见元素
- 处理方案
- 滚动偏移
- 处理方案
- 不同元素 FMP 算法不同
- 普通元素
- 资源元素
引言
上篇讲到,权重值定位性能指标 FMP,至于怎么算权重讲的不是很清楚,此篇将就如何「相对准确」算出权重值以及怎样筛选出我们想要的 FMP 值。
以下内容「择重略轻」
如何监控节点
监控变化
MutationObserver
一句话解释
「MutationObserver 给予我们获取 DOM 渲染「切面」的能力」。
「MDN 解释」MutationObserver 接口提供了监视对 DOM 树所做更改的能力。它被设计为旧的 Mutation Events 功能的替代品,该功能是 DOM3 Events 规范的一部分。
更多使用细节详见 https://developer.mozilla.org/zh-CN/docs/Web/API/MutationObserver
节点标记
有了以上能力,既可以对节点进行监听和 「标记」
像这样
// 伪代码
new MutationObserver(() => {
let timestamp = performance.now() || (Date.now() - START_TIME),
doTag(document.body, global.paintTag++);
global.ptCollector.push(timestamp);
});
名词解释: - paintTag:对应 dom 的打点标记「_pi」,标记着第几次配渲染的产物。

- ptCollector:paintTag 对应的时间节点集合。可以用 paintTag 检索到某次渲染时刻的时间节点。
什么时间计算?
window.load 开始计算
为什么?
我们认为,通常情况下,在 window 触发 load 事件的时刻,意味着主要业务的 90% 的资源和 dom 都已经准备就绪。此时算出的高权重得分的 dom 就是我们想要找的 FMP 关键节点。
我不关心你是怎么渲染的,异步也好直出也好,殊途同归,我只关心结果
怎么筛选元素?
计算权重得分
基础节点
一个基础节点(无子节点)的权重得分计算方法:
// 伪代码
const TAG_WEIGHT_MAP = {
SVG: 2,
IMG: 2,
CANVAS: 2,
VIDEO: 4
};
node => {
let weight = TAG_WEIGHT_MAP[node.tagName],
areaPercent = global.calculateShowPercent(node);
let score = width * height * weight * areaPercent;
return score;
}
关于 calculateShowPercent 用下图解释

父节点
这是一个算法我把它叫做「代父竞选」
父节点自身的权重得分计算方法同基础节点相同,不同的是,如果其子节点的得分和大于或等于了自身的得分,将由子节点组代替父节点参与更高级的竞选,同时,子节点的权重得分和作为父节点的得分,另外,如果子节点是有孙子节点代表的,孙子节点将会同步升级。
怎么理解呢?
如下两种情况:
- 一

父元素得分 = 400 * 100 = 40000 子元素得分和 = 300 * 60 + 60 * 60 = 21600 父元素得分 > 子元素得分和
此情况下,该组元素以 40000 的得分进入下一级竞选。参选的元素列表为父元素本身。
数据结构如下:
{
deeplink: [{…}],
elements: [{
node: parent#id_search,
...
}],
node: parent#id_search,
paintIndex: 1,
score: 40000
}
- 二
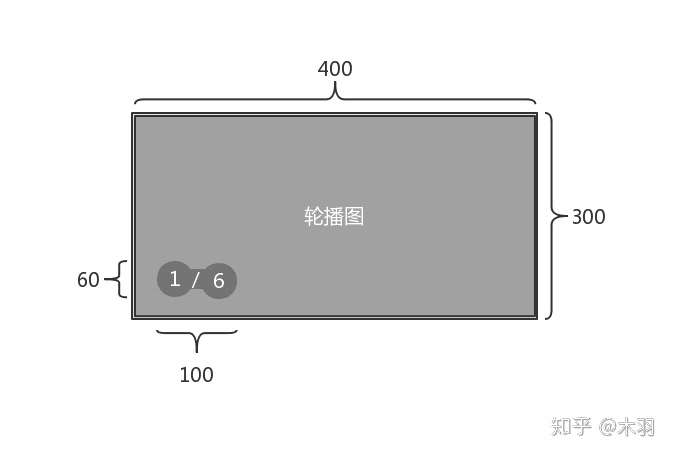
父元素得分 = 400 * 300 = 120000 子元素得分和 = 400 * 300 + 60 * 100 = 126000 父元素得分 < 子元素得分和
此情况下,该组元素应以 126000 的得分进入下一级竞选。参选的元素列表为子元素组,「代父竞选」。
数据结构如下:
{
deeplink: [{…}],
elements: [
{node: child#id_slides_pics, ...},
{node: child#id_slides_index, ...}
],
node: parent#id_slides,
paintIndex: 2,
score: 126000
}
由以上两种情况可推
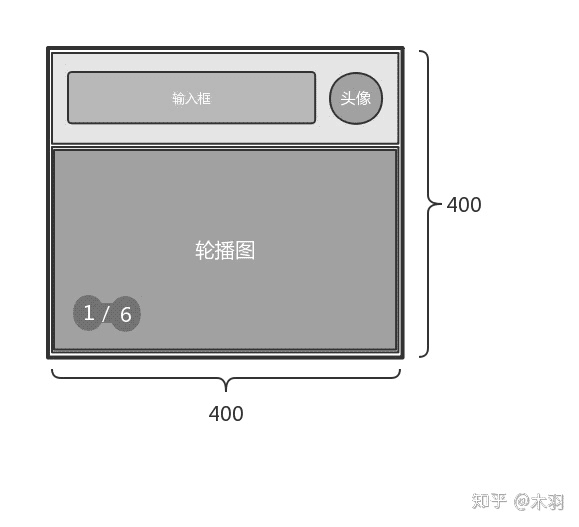
父元素得分 = 400 * 400 = 160000 子元素得分和 = 40000 + 126000 = 166000 父元素得分 < 子元素得分和 其中一个子节点由孙子节点们代表
==>
{
deeplink: [{…}],
elements: [
{node: child#id_search, ...},
{node: child#id_slides_pics, ...},
{node: child#id_slides_index, ...}
],
node: parent#id_body,
paintIndex: 1,
score: 166000
}
所以,以下组合与拆分就不难理解了。
排除干扰项
在我们对 document 深度遍历计算的过程中,总会遇到一些干扰因素使我们的脚本计算出错,以下两种就是最常见的
不可见元素

这种元素虽然用户无感知,但会严重影响最后的竞选结果。
处理方案
const isIgnoreDom = node => {
return getStyle(node, 'opacity') < 0.1 ||
getStyle(node, 'visibility') === 'hidden' ||
getStyle(node, 'display') === 'none' ||
node.children.length === 0 &&
getStyle(node, 'background-image') === 'none' &&
getStyle(node, 'background-color') === 'rgba(0, 0, 0, 0)';
}
首先我们认为opacity < 0.1 visibility === 'hidden' 和 display === 'none' 的元素为不可见元素,应忽略,另外,无子节点,且无背景无颜色的元素也归属于不可见元素,忽略。
滚动偏移
由于我们的脚本在 window load 后才执行,绝大情况下此时浏览器的滚动条已经发生了偏移。精选结果会发生误差。如下图:
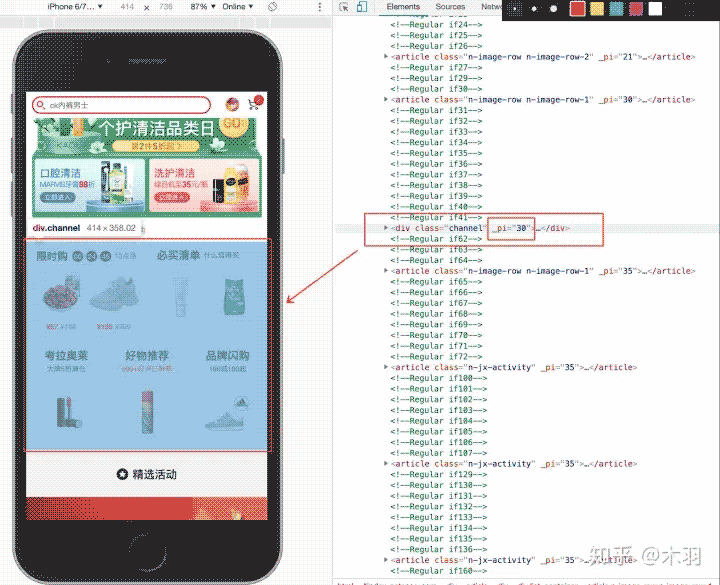
此时精选结果为
<div class="channel" _pi="30">...</div>
_pi 走到了 30,「第 30 次渲染」,无论有多快,这个值始终会远大于实际的 FMP。
导致「滚动偏移」的情况有两种
- 在
load触发前用户主动翻阅 这种情况再常见不过,用户不可能每次都等到 load 后才进行操作。而且如果存在pending的资源,load 的时间会非常迟。 load浏览器触发前执行了「scrollRestore (英文描述,并不存在此事件)」
对于第二种情况,还是很好解的,因为并不是所有的浏览器都有 History.scrollRestoration 的特效,所以,我们只要关掉即可,但情况一我们是无论如何不能控制的。
所以,只能另辟蹊径「划定计算区域」,且此区域应避开滚动条位置的影响。
处理方案
当然,我们也是有方法的,其实也挺简单。
这得益于「document 对象的宽高是固定的,且偏移量同步于滚动条」
const getDomBounding = dom => {
const { x, y } = document.body.getBoundingClientRect();
const { left, right, top, bottom, width, height } = dom.getBoundingClientRect();
return {
left: left - x,
right: right - x,
top: top - y,
bottom: bottom - y,
height, width
}
}
如果以上有遗漏情况,还请不吝赐教,不胜感激!
不同元素 FMP 算法不同
普通元素
像 <DIV/>、<SPAN/>、<P/>、<INPUT/> 这些普通元素,标注的 _pi 值索引到的渲染时刻的时间节点 ptCollector 还记得吗?该时间即可作为 FMP 值。
有特殊情况,如果普通元素带有背景图片,则会升级为 <IMG/> 类资源元素
资源元素
如 <IMG/>、<VIDEO/>,该元素的 resource 的 responseEnd 的时间节点将作为 FMP 值
不过,我们可以针对不同的项目对全局权重配置 TAG_WEIGHT_MAP 做「合理化」调整。当然也可以忽略「图片」和「视频」等资源元素资源加载时间,一切以实际项目而定
以上就是详解节点监控相对准确的计算FMP的详细内容,更多关于节点监控FMP计算的资料请关注我们其它相关文章!
相关推荐
-
JS前端性能指标定位FMP使用详解
目录 什么是FMP? 权重定位 权重计算 节点标记 计算权重值 第一步:简单粗暴,按大小计算 第二步:根据权重值推导主角元素 第三步:根据元素类型取时间 回归验证 什么是FMP? 可能大家对「白屏时间」这个名词并不陌生,他是「刀耕火种」年代,我们收集的页面性能指标之一,随着前端工程的复杂化,白屏时间已经没有什么实质性的意义了,取而代之的就是 FMP. 先来介绍几个与之相关的名词. FP(First Paint):首次绘制,标记浏览器渲染任何在视觉上不同于导航前屏幕内容的时间点 FCP(First
-
Druid基本配置及内置监控使用_动力节点Java学院整理
1. 使用方法 首先从http://repo1.maven.org/maven2/com/alibaba/druid/ 下载最新的jar包.如果想使用最新的源码编译,可以从https://github.com/alibaba/druid 下载源码,然后使用maven命令行,或者导入到eclipse中进行编译. 和dbcp类似,druid的配置项如下: 配置 缺省值 说明 name 配置这个属性的意义在于,如果存在多个数据源,监控的时候 可以通过名字来区分开来.如果没有配置,将会生成一个名字,
-

监控Linux系统节点和服务性能的方法
1.获取信息 #!/bin/bash #描述: # 把top信息输入到一个文件内部 #作者:孤舟点点 #版本:1.0 #创建时间:2017-11-09 03:04:28 PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin export PATH p=`pwd` Day=`date +"%Y%m%d"` HOST=`hostname` for((i=0; i<1440; i=i+1)) do
-
redislive监控redis服务的图文教程_动力节点Java 学院整理
一:安装 首先我们去官网看看:http://www.nkrode.com/article/real-time-dashboard-for-redis,从官网上可以看到,这是python写的,不过开心的是centos上面默认是装有python环境的,比如这里的centos7: 1.安装pip 学过python的朋友应该知道,pip就是一个安装和管理python包的工具,现在我们可以去官网看一看,通过wget这个链接就可以了. 下载之后,我们手工解压一下,然后进入到pip-8.1.2的根目录,执行:
-
prometheus监控节点程序的安装及卸载命令
目录 安装监控服务 卸载监控程序 本教程基于AlpineLinux,请注意将apk相关命令替换为对应系统的包命令,比如apt.yum等. 安装监控服务 apk add prometheus-node-exporter rc-update add node-exporter default # 配置节点 ARGS="--collector.processes --web.listen-address=:2910 --web.config=/etc/prometheus/web-config.yml
-
详解节点监控相对准确的计算FMP
目录 引言 如何监控节点 监控变化 节点标记 什么时间计算? 为什么? 怎么筛选元素? 计算权重得分 基础节点 父节点 排除干扰项 不可见元素 处理方案 滚动偏移 处理方案 不同元素 FMP 算法不同 普通元素 资源元素 引言 上篇讲到,权重值定位性能指标 FMP,至于怎么算权重讲的不是很清楚,此篇将就如何「相对准确」算出权重值以及怎样筛选出我们想要的 FMP 值. 以下内容「择重略轻」 如何监控节点 监控变化 MutationObserver 一句话解释 「MutationObserver 给
-
详解prometheus监控golang服务实践记录
一.prometheus基本原理介绍 prometheus是基于metric采样的监控,可以自定义监控指标,如:服务每秒请求数.请求失败数.请求执行时间等,每经过一个时间间隔,数据都会从运行的服务中流出,存储到一个时间序列数据库中,之后可通过PromQL语法查询. 主要特点: 多维数据模型,时间序列数据通过metric名以key.value的形式标识: 使用PromQL语法灵活地查询数据: 不需要依赖分布式存储,各服务器节点是独立自治的: 时间序列的收集,通过 HTTP 调用,基于pull 模型
-
详解metricbeat监控nginx情况
本文介绍了详解metricbeat 监控 nginx 情况,分享给大家,具体如下: 1.version os: centos 7.2 nginx: nginx-1.13.9 metricbeat: metricbeat-6.2.4 2.download #wget https://artifacts.elastic.co/downloads/beats/metricbeat/metricbeat-6.2.4-x86_64.rpm 3.install #rpm -ivh metricbeat-6.
-
Spring Boot Admin的使用详解(Actuator监控接口)
第一部分 Spring Boot Admin 简介 Spring Boot Admin用来管理和监控Spring Boot应用程序. 应用程序向我们的Spring Boot Admin Client注册(通过HTTP)或使用SpringCloud®(例如Eureka,Consul)发现. UI是Spring Boot Actuator端点上的Vue.js应用程序. Spring Boot Admin 是一个管理和监控Spring Boot 应用程序的开源软件.每个应用都认为是一个客户端,通过HT
-
FTP服务器详解之监控ftp服务器、上传文件到ftp服务器、ftp文件监控的方法
现在FTP文件服务器的使用极为普遍,可以方便地将文件实时存储在FTP文件服务器上,那么如何搭建FTP文件服务器呢,以及如何监控FTP文件服务器文件访问操作日志情况呢?详细如下: 第1页:FTP服务器的作用 FTP服务器(File Transfer Protocol Server)是在互联网上提供文件存储和访问服务的计算机,它们依照FTP协议提供服务.FTP服务器常常被用来进行文件共享和传输,是互联网领域必不可少的一环. FTP服务器的作用 FTP服务器是为了解决文件传输障碍问题而产生的.那么FT
-
详解Linux监控重要进程的实现方法
不管后台服务程序写的多么健壮,还是可能会出现core dump等程序异常退出的情况,但是一般情况下需要在无 人为干预情况下,能够自动重新启动,保证服务进程能够服务用户.这时就需要一个监控程序来实现能够让服务进程自动重新启动.查阅相关资料及尝试一些方法之后,总结linux系统监控重要进程的实现方法:脚本检测和子进程替换. 1.脚本检测 (1) 基本思路: 通过shell命令(ps -e | grep "$1" | grep -v "grep" | wc -l) 获取
-
详解ZABBIX监控ESXI主机的问题
目录 一.环境 二.配置zabbix服務端 三.配置ESXI 四.添加主机监控 一.环境 Zabbix5.2 Centos8.2 ESXI6.5 二.配置zabbix服務端 1.编译安装Zabbix-server的应加上 –with-libxml2 和 –with-libcurl 编译选项 2.yum安装zabbix的是默认安装的 3.修改zabbix配置文件: vim /etc/zabbix/zabbix_server.conf # 找到以下参数取消注释并配置相应数值 StartVMwareC
-
linux top命令详解
top 命令主要用于查看进程的相关信息,同时它也会提供系统平均负载,cpu 信息和内存信息.下面的截图展示了 top 命令默认提供的信息: 系统平均负载 top 命令输出中的第一行是系统的平均负载,这和 uptime 命令的输出是一样的: 13:05:49 表示系统当前时间. up 7 days 表示系统最后一次启动后总的运行时间. 1 user 表示当前系统中只有一个登录用户. load average: 0.01, 0.04, 0.00 表示系统的平均负载,最后的三个数字分别表示最后一分钟的
-
linux top命令详解与输出结果说明
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,常用于服务端性能分析. top命令说明 [www.jb51.net@jb51 ~]$ top top - 16:07:37 up 241 days, 20:11, 1 user, load average: 0.96, 1.13, 1.25 Tasks: 231 total, 1 running, 230 sleeping, 0 stopped, 0 zombie Cpu(s): 12.7%us, 8.4%sy
-
Java BigDecimal详解_动力节点Java学院整理
1.引言 借用<Effactive Java>这本书中的话,float和double类型的主要设计目标是为了科学计算和工程计算.他们执行二进制浮点运算,这是为了在广域数值范围上提供较为精确的快速近似计算而精心设计的.然而,它们没有提供完全精确的结果,所以不应该被用于要求精确结果的场合.但是,商业计算往往要求结果精确,例如银行存款数额,这时候BigDecimal就派上大用场啦. 2.BigDecimal简介 BigDecimal 由任意精度的整数非标度值 和32 位的整数标度 (scale) 组