国产开源数据库openGauss容器部署过程详解
目录
- 前言
- ️ 1.openGauss介绍
- ️ 2.容器部署
- ️ 3.opengauss操作
- ️ 4.常用信息选项
前言
openGauss是一款开源的关系型数据库管理系统,融合了华为在数据库领域多年的内核经验
️ 1.openGauss介绍
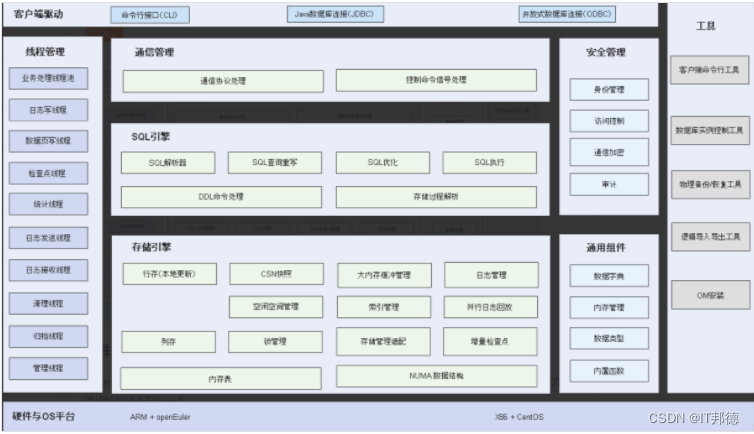
openGauss是一款开源的关系型数据库管理系统,它具有多核高性能、全链路安全性、智能运维等企业级特性。 openGauss内核早期源自开源数据库PostgreSQL,融合了华为在数据库领域多年的内核经验,在架构、事务、存储引擎、优化器及ARM架构上进行了适配与优化。作为一个开源数据库,期望与广泛的开发者共同构建一个多元化技术的开源数据库社区。
官网:https://opengauss.org/zh/
开源社区:https://gitee.com/opengauss/openGauss-server

## 产品特点
openGauss是一款开源的关系型数据库,采用客户端/服务器、单进程多线程架构,支持单机和一主多备部署方式,备机只读,支持双机高可用和读扩展。
openGauss相比于其他开源数据库主要有以下几个主要特点
1.高性能
提供了面向多核架构的并发控制技术结合鲲鹏硬件优化,在两路鲲鹏下TPCC Benchmark达成性能150万tpmc。
针对当前硬件多核numa的架构趋势, 在内核关键结构上采用了Numa-Aware的数据结构。
提供Sql-bypass智能快速引擎、融合引擎技术。
2.高可用
支持主备同步、异步和级联备机多种部署模式。
数据页CRC校验,损坏数据页通过备机自动修复。
备机并行恢复,10秒内可升主提供服务。
3.高安全
支持全密态计算、访问控制、加密认证、数据库审计和动态数据脱敏等安全特性,提供全方位端到端的数据安全保护。
4.易运维
基于AI的智能参数调优和索引推荐,提供AI自动参数推荐。
慢SQL诊断,多维性能自监控视图,实时掌控系统的性能表现。
提供在线自学习的SQL时间预测。
5.全开放
采用木兰宽松许可证协议,允许对代码自由修改、使用和引用。
数据库内核能力全开放。
提供丰富的伙伴认证,培训体系和高校课程
️ 2.容器部署
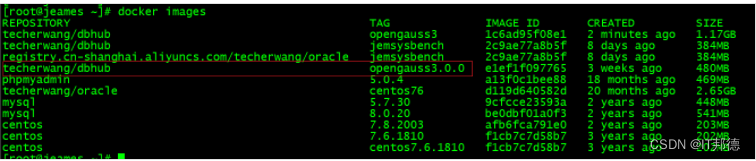
# 获取镜像 docker pull techerwang/dbhub:opengauss3 ## 查看镜像 [root@jeames ~]# docker images
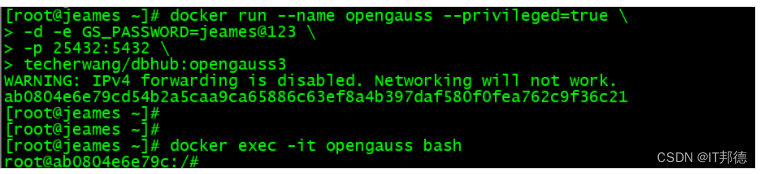
## 容器创建 docker run --name opengauss --privileged=true \ -d -e GS_PASSWORD=jeames@123 \ -p 25432:5432 \ techerwang/dbhub:opengauss3 ## 开机自启动 docker update --restart=always opengauss ## 进入容器 docker exec -it opengauss bash
️ 3.opengauss操作
[root@jeames ~]# docker exec -it opengauss bash
root@ab0804e6e79c:/#
root@ab0804e6e79c:/#
root@ab0804e6e79c:/#
root@ab0804e6e79c:/# su - omm
omm@ab0804e6e79c:~$ gsql
gsql ((openGauss 3.0.0 build 02c14696) compiled at 2022-04-01 18:12:34 commit 0 last mr )
Non-SSL connection (SSL connection is recommended when requiring high-security)
Type "help" for help.
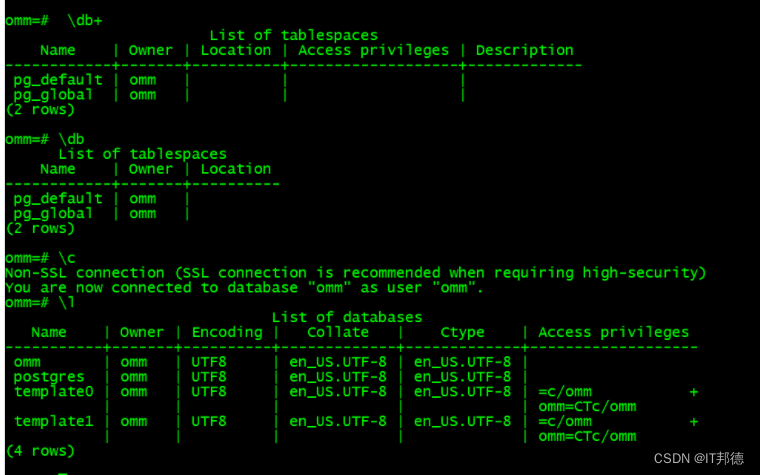
omm=# \d
No relations found.
omm=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+-------+----------+-------------+-------------+-------------------
omm | omm | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
postgres | omm | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | omm | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/omm +
| | | | | omm=CTc/omm
template1 | omm | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/omm +
| | | | | omm=CTc/omm
(4 rows)
️ 4.常用信息选项
\d [名字] 描述表, 索引, 序列, 或者视图
\d{t|i|s|v|S} [模式] (加 "+" 获取更多信息)
列出表/索引/序列/视图/系统表
\da [模式] 列出聚集函数
\db [模式] 列出表空间 (加 "+" 获取更多的信息)
\dc [模式] 列出编码转换
\dC 列出类型转换
\dd [模式] 显示目标的注释
\dD [模式] 列出域
\df [模式] 列出函数 (加 "+" 获取更多的信息)
\dg [模式] 列出组
\dn [模式] 列出模式 (加 "+" 获取更多的信息)
\do [名字] 列出操作符
\dl 列出大对象, 和 lo_list 一样
\dp [模式] 列出表, 视图, 序列的访问权限
\dT [模式] 列出数据类型 (加 "+" 获取更多的信息)
\du [模式] 列出用户
\l 列出所有数据库 (加 "+" 获取更多的信息)
\z [模式] 列出表, 视图, 序列的访问权限 (和 dp 一样)
到此这篇关于国产开源数据库openGauss容器部署的文章就介绍到这了,更多相关openGauss容器部署内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

使用虚拟机在VirtualBox+openEuler上安装部署openGauss数据库
目录 1.虚拟机VirtualBox下载及安装 步骤 1 进入官方网站下载页面. 步骤 2下载完成后,双击执行文件进行安装. 2.openEuler-20.03-LTS镜像文件下载 步骤 1 进入华为开源镜像站的下载页面. 步骤 2 点击” openEuler-20.03-LTS-x86_64-dvd.iso”,进行相应ISO镜像文件下载. 3.VirtualBox下安装openEuler-20.03-LTS操作系统 步骤 1 新建虚拟电脑. 步骤 2 设置虚拟电脑并安装. 步骤 3 确认网络
-
openGauss数据库JDBC环境连接配置的详细过程(Eclipse)
目录 1.测试环境 2.准备 2.1 PC端安装配置JDK11 2.2下载JDBC驱动并解压 3 进行eclipse配置 1.测试环境 客户端系统:Windows 10 客户端软件:eclipse 2020-09 Server操作系统:openEuler 20.03 64bit with ARM 数据库版本:openGauss 2.0.0 2.准备 2.1 PC端安装配置JDK11 DOS窗口输入“java -version”,查看JDK版本,确认为JDK11版本.如果未安装JDK,请 从官方网
-
python将Dataframe格式的数据写入opengauss数据库并查询
目录 一.将数据写入opengauss 二.python条件查询opengauss数据库中文列名的数据 一.将数据写入opengauss 前提准备: 成功opengauss数据库,并创建用户jack,创建数据库datasets. 数据准备: 所用数据以csv格式存在本地,编码格式为GB2312. 数据存入: 开始hello表未存在,那么执行程序后,系统会自动创建一个hello表(这里指定了名字为hello): 若hello表已经存在,那么会增加数据到hello表.列名需要与hello表一一对应.
-
国产开源数据库openGauss容器部署过程详解
目录 前言 ️ 1.openGauss介绍 ️ 2.容器部署 ️ 3.opengauss操作 ️ 4.常用信息选项 前言 openGauss是一款开源的关系型数据库管理系统,融合了华为在数据库领域多年的内核经验 ️ 1.openGauss介绍 openGauss是一款开源的关系型数据库管理系统,它具有多核高性能.全链路安全性.智能运维等企业级特性. openGauss内核早期源自开源数据库PostgreSQL,融合了华为在数据库领域多年的内核经验,在架构.事务.存储引擎.优化器及ARM架构上进行
-
JDBC连接MySQL数据库批量插入数据过程详解
这篇文章主要介绍了JDBC连接MySQL数据库批量插入数据过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.读取本地json数据 2.jdbc理解数据库 3.批量插入 maven 引入jar包: <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2
-
MySQL数据库主从同步实战过程详解
本文实例讲述了MySQL数据库主从同步实战过程.分享给大家供大家参考,具体如下: 接上一篇:MySQL数据库入门之备份数据库 安装环境说明 系统环境: [root@~]# cat /etc/redhat-release CentOS release 6.5 (Final) [root@~]# uname -r 2.6.32-431.el6.x86_64 数据库: 由于是模拟环境,主从库在同一台服务器上,服务器IP地址192.168.1.7 主库使用3306端口 从库使用3307端口 数据库数据目
-
源码安装apache脚本部署过程详解
目录 源码安装apache脚本部署 源码安装apache脚本部署 [root@localhost ~]# ls anaconda-ks.cfg httpd.tar.xz [root@localhost ~]# tar xf httpd.tar.xz 解压存放脚本的压缩包 [root@localhost ~]# ls anaconda-ks.cfg httpd httpd.tar.xz [root@localhost ~]# cd httpd/ [root@localhost httpd]# ls
-
开源数据库postgreSQL13在麒麟v10sp1源码安装过程详解
一.中标麒麟v10sp1在飞腾2000+系统安装略 二.系统依赖包安装 [root@ft2000db opt]# yum install bzip* [root@ft2000db opt]# nkvers ############## Kylin Linux Version ################# Release: Kylin Linux Advanced Server release V10 (Tercel) Kernel: 4.19.90-17.ky10.aarch64 Buil
-
SEATA事务服务DOCKER部署的过程详解
1.创库授权语句 > create database seata: > grant all on seata.* to seata_user@'%' identified by '123455' 2.数据库建表语句 cat create_seata_table.sql -- -------------------------------- The script used when storeMode is 'db' -------------------------------- -- the
-
DBA_Oracle Startup / Shutdown启动和关闭过程详解(概念)(对数据库进行各种维护操作)
一.摘要 Oracle数据库的完整启动过程是分步骤完成的,包含以下3个步骤: 启动实例-->加载数据库-->打开数据库 因为Oracle数据库启动过程中不同的阶段可以对数据库进行不同的维护操作,对应我们不同的需求,所以就需不同的模式启动数据库. 1. Oracle启动需要经历四个状态:SHUTDOWN .NOMOUNT .MOUNT .OPEN 2. Oracle关闭的四种方式:Normal, Immediate, Transactional, Abort 3. 启动和关闭过程详解 二.数
-
基于docker 搭建Prometheus+Grafana的过程详解
一.介绍Prometheus Prometheus(普罗米修斯)是一套开源的监控&报警&时间序列数据库的组合,起始是由SoundCloud公司开发的.随着发展,越来越多公司和组织接受采用Prometheus,社会也十分活跃,他们便将它独立成开源项目,并且有公司来运作.Google SRE的书内也曾提到跟他们BorgMon监控系统相似的实现是Prometheus.现在最常见的Kubernetes容器管理系统中,通常会搭配Prometheus进行监控. Prometheus基本原理是通过HTT
-
pm2与Verdaccio搭建私有npm库过程详解
目录 前言 一般私有化的npm仓库有以下几种方法实现: 下面对各个方案进行一个粗浅的对比: 为什么选用Verdaccio? 安装 修改配置 配置文件 权限把控 部署 docker部署 pm2部署 管理npm仓库源 npm包发布 注册 登录 发布 删除 前言 最近开会的时候讨论到前端组件库搭建,因为需要多人协作,使用npm link等都比较麻烦,且当业务规模较大了之后,我们一般会有自己的脚手架,自己的全局工具包等等.其中可能包含了自身的业务代码不能公开,因此我们都需要一个私有化的npm仓库. 一般
-
springboot jpa分库分表项目实现过程详解
这篇文章主要介绍了springboot jpa分库分表项目实现过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 分库分表场景 关系型数据库本身比较容易成为系统瓶颈,单机存储容量.连接数.处理能力都有限.当单表的数据量达到1000W或100G以后,由于查询维度较多,即使添加从库.优化索引,做很多操作时性能仍下降严重.此时就要考虑对其进行切分了,切分的目的就在于减少数据库的负担,缩短查询时间. 分库分表用于应对当前互联网常见的两个场景--大数