深入理解堆排序及其分析
记得在学习数据结构的时候一味的想用代码实现算法,重视的是写出来的代码有一个正确的输入,然后有一个正确的输出,那么就很满足了。从网上看了许多的代码,看了之后貌似懂了,自己写完之后也正确了,但是不久之后就忘了,因为大脑在回忆的时候,只依稀记得代码中的部分,那么的模糊,根本不能再次写出正确的代码,也许在第一次写的时候是因为参考了别人的代码,看过之后大脑可以进行短暂的高清晰记忆,于是欺骗了我,以为自己写出来的,满足了成就感。可是代码是计算机识别的,而我们更喜欢文字,图像。所以我们在学习算法的时候要注重算法的原理以及算法的分析,用文字,图像表达出来,然后当需要用的时候再将文字转换为代码。记忆分为三个步骤:编码,存储和检索,就以学习为例,先理解知识,再归纳知识,最后巩固知识,为了以后的应用而方便检索知识。
堆排序过程
堆分为大根堆和小根堆,是完全二叉树。大根堆的要求是每个节点的值都不大于其父节点的值,即A[PARENT[i]] >= A[i]。在数组的非降序排序中,需要使用的就是大根堆,因为根据大根堆的要求可知,最大的值一定在堆顶。
既然是堆排序,自然需要先建立一个堆,而建堆的核心内容是调整堆,使二叉树满足堆的定义(每个节点的值都不大于其父节点的值)。调堆的过程应该从最后一个非叶子节点开始,假设有数组A = {1, 3, 4, 5, 7, 2, 6, 8, 0}。那么调堆的过程如下图,数组下标从0开始,A[3] = 5开始。分别与左孩子和右孩子比较大小,如果A[3]最大,则不用调整,否则和孩子中的值最大的一个交换位置,在图1中是A[7] > A[3] > A[8],所以A[3]与A[7]对换,从图1.1转到图1.2。
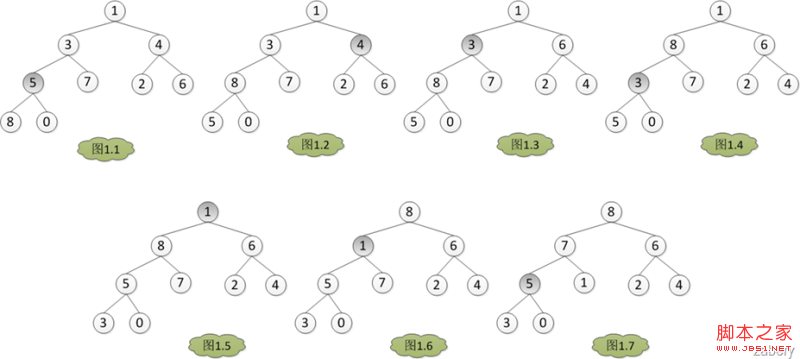
for ( i = headLen/2; i >= 0; i++)
do AdjustHeap(A, heapLen, i)
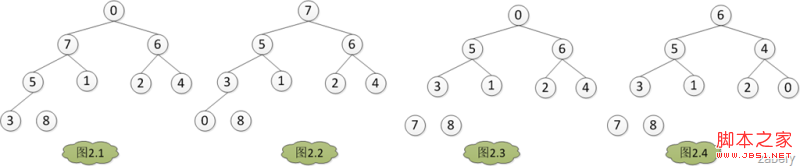
建堆完成之后,堆如图1.7是个大根堆。将A[0] = 8 与 A[heapLen-1]交换,然后heapLen减一,如图2.1,然后AdjustHeap(A, heapLen-1, 0),如图2.2。如此交换堆的第一个元
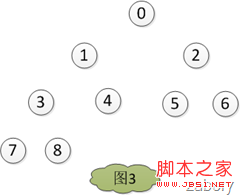
素和堆的最后一个元素,然后堆的大小heapLen减一,对堆的大小为heapLen的堆进行调堆,如此循环,直到heapLen == 1时停止,最后得出结果如图3。
/*
输入:数组A,堆的长度hLen,以及需要调整的节点i
功能:调堆
*/
void AdjustHeap(int A[], int hLen, int i)
{
int left = LeftChild(i); //节点i的左孩子
int right = RightChild(i); //节点i的右孩子节点
int largest = i;
int temp;
while(left < hLen || right < hLen)
{
if (left < hLen && A[largest] < A[left])
{
largest = left;
}
if (right < hLen && A[largest] < A[right])
{
largest = right;
}
if (i != largest) //如果最大值不是父节点
{
temp = A[largest]; //交换父节点和和拥有最大值的子节点交换
A[largest] = A[i];
A[i] = temp;
i = largest; //新的父节点,以备迭代调堆
left = LeftChild(i); //新的子节点
right = RightChild(i);
}
else
{
break;
}
}
}
/*
输入:数组A,堆的大小hLen
功能:建堆
*/
void BuildHeap(int A[], int hLen)
{
int i;
int begin = hLen/2 - 1; //最后一个非叶子节点
for (i = begin; i >= 0; i--)
{
AdjustHeap(A, hLen, i);
}
}
/*
输入:数组A,待排序数组的大小aLen
功能:堆排序
*/
void HeapSort(int A[], int aLen)
{
int hLen = aLen;
int temp;
BuildHeap(A, hLen); //建堆
while (hLen > 1)
{
temp = A[hLen-1]; //交换堆的第一个元素和堆的最后一个元素
A[hLen-1] = A[0];
A[0] = temp;
hLen--; //堆的大小减一
AdjustHeap(A, hLen, 0); //调堆
}
}
性能分析
•调堆:上面已经分析了,调堆的运行时间为O(h)。
•建堆:每一层最多的节点个数为n1 = ceil(n/(2^(h+1))),

因此,建堆的运行时间是O(n)。
•循环调堆(代码67-74),因为需要调堆的是堆顶元素,所以运行时间是O(h) = O(floor(logn))。所以循环调堆的运行时间为O(nlogn)。
总运行时间T(n) = O(nlogn) + O(n) = O(nlogn)。对于堆排序的最好情况与最坏情况的运行时间,因为最坏与最好的输入都只是影响建堆的运行时间O(1)或者O(n),而在总体时间中占重要比例的是循环调堆的过程,即O(nlogn) + O(1) =O(nlogn) + O(n) = O(nlogn)。因此最好或者最坏情况下,堆排序的运行时间都是O(nlogn)。而且堆排序还是原地算法(in-place algorithm)。
相关推荐
-
python 实现堆排序算法代码
复制代码 代码如下: #!/usr/bin/python import sys def left_child(node): return node * 2 + 1 def right_child(node): return node * 2 + 2 def parent(node): if (node % 2): return (i - 1) / 2 else: return (i - 2) / 2 def max_heapify(array, i, heap_size): l = left_c
-
堆排序算法(选择排序改进)
首先要理解堆的含义:要么所有节点都不大于其子孩子节点数据,要么都不小于其子孩子节点数据 堆排序的核心思想:就是要满足所有节点都满足上面两点,如何完成,看下面 堆排序的步骤: 1.首先要建成一个大顶堆或者小顶堆,在建的过程中其实就是调整节点的位置,首先要从最后最后一个节点的母亲节点开始,按照堆的含义调整.为什么不是最后一个或者其他?因为要保证完整性和不必要性,所以只需从最后一个的母亲节点开始即可(下面的堆默认存在顺序结构,从索引0开始的,所以有些二叉树的特性请查阅二叉树),直至索引节点为0的节点.
-

C# 排序算法之堆排序
一.基本概念 堆:这里是指一种数据结构,而不是我们在C#中提到的用于存储引用类型对象的地方.它可以被当成一棵完全二叉树. 为了将堆用数组来存放,这里对每个节点标上顺序.事实上,我们可以用简单的计算公式得出父节点,左孩子,右孩子的索引: parent(i) = left(i) = 2i right(i)=2i + 1 最大堆和最小堆: 最大堆是指所有父节点的值都大于其孩子节点的堆,即满足以下公式: A[parent[i]]A[i](A是指存放该堆的数组) 最小堆相反. 最大堆和最小堆是堆排序的关
-
内部排序之堆排序的实现详解
堆排序(Heap Sort)只需要一个记录大小的辅助空间,每个待排序的记录仅占有一个存储空间.(1)基本概念a)堆:设有n个元素的序列:{k1, k2, ..., kn}对所有的i=1,2,...,(int)(n/2),当满足下面关系: ki≤k2i,ki≤k2i+1 或
-
Java实现堆排序(Heapsort)实例代码
复制代码 代码如下: import java.util.Arrays; public class HeapSort { public static void heapSort(DataWraper[] data){ System.out.println("开始排序"); int arrayLength=data.length; //循环建堆 for(int i=0;i<arrayLength-1;i++){
-
php堆排序(heapsort)练习
复制代码 代码如下: <?//堆排序应用class heapsort { var $a; function setarray($a)//取得数组 { $this->a=$a; } function runvalue($b,$c)//$a 代表数组,$b代表排序堆,$c代表结束点, { while($b<$c) { $h1=2*$b; $h2=(2*$
-
深入理解堆排序及其分析
记得在学习数据结构的时候一味的想用代码实现算法,重视的是写出来的代码有一个正确的输入,然后有一个正确的输出,那么就很满足了.从网上看了许多的代码,看了之后貌似懂了,自己写完之后也正确了,但是不久之后就忘了,因为大脑在回忆的时候,只依稀记得代码中的部分,那么的模糊,根本不能再次写出正确的代码,也许在第一次写的时候是因为参考了别人的代码,看过之后大脑可以进行短暂的高清晰记忆,于是欺骗了我,以为自己写出来的,满足了成就感.可是代码是计算机识别的,而我们更喜欢文字,图像.所以我们在学习算法的时候要注重算
-
C语言数据结构中堆排序的分析总结
目录 一.本章重点 二.堆 2.1堆的介绍(三点) 2.2向上调整 2.3向下调整 2.4建堆(两种方式) 三.堆排序 一.本章重点 堆 向上调整 向下调整 堆排序 二.堆 2.1堆的介绍(三点) 1.物理结构是数组 2.逻辑结构是完全二叉树 3.大堆:所有的父亲节点都大于等于孩子节点,小堆:所有的父亲节点都小于等于孩子节点. 2.2向上调整 概念:有一个小/大堆,在数组最后插入一个元素,通过向上调整,使得该堆还是小/大堆. 使用条件:数组前n-1个元素构成一个堆. 以大堆为例: 逻辑实现: 将
-
C语言数据结构之堆、堆排序的分析及实现
目录 1.堆的概念结构及分类 1.2堆的分类 1.2.1 大堆 1.2.2 小堆 2. 堆的主要接口 3.堆的实现 3.1 堆的初始化 HeapInit 3.2 堆的销毁 HeapDestory 3.3 堆的打印 HeapPrint 3.4 堆的插入元素 HeapPush * 3.5 堆的删除元素 HeapPop * 4.堆的应用:堆排序 *** 4.1 堆排序实现过程分析 4.3 堆排序结果演示 5.堆(小堆)的完整代码 总结 1.堆的概念结构及分类 以上这段概念描述看起来十分复杂
-
javascript回调函数的概念理解与用法分析
本文实例讲述了javascript回调函数的概念理解与用法.分享给大家供大家参考,具体如下: 一. 回调函数的作用 js代码会至上而下一条线执行下去,但是有时候我们需要等到一个操作结束之后再进行下一个操作,这时候就需要用到回调函数. 二. 回调函数的解释 因为函数实际上是一种对象,它可以存储在变量中,通过参数传递给另一个函数,在函数内部创建,从函数中返回结果值",因为函数是内置对象,我们可以将它作为参数传递给另一个函数,到函数中执行,甚至执行后将它返回,它一直被"专业的程序员"
-
PHP 观察者模式深入理解与应用分析
本文实例讲述了PHP 观察者模式.分享给大家供大家参考,具体如下: 用模式开发的优点是,能让我们的逻辑结构以及代码更加清晰,便于维护! 而我们为什么要用 "观察者模式"?这就需要从实际运用中来理解才能更好的运用!用如下的情境来说明吧. 事例,开始时我被安排做项目的登录,很快我就完成了.然后产品提出了另一个需求,用户登录后,给他们推送一条实时消息!然后我在登录成功的逻辑后加了一段代码,完成了登录后的实时消息推送.然而事情还没有完,产品又给加了个需求,需要给新登录的用户10块钱红包奖励,这
-
服务器Apache与Tomcat和Nginx的理解和对比分析详解
1 问题 公司服务器用的Apache,后台是php语言,然后服务端用的linux C/C++,会经常听到Apache服务器,然后之前实习的公司服务端用的java,然后依稀记得使用了nginx反向代理服务器和tomcat,请求先经过nginx然后再去通过tomcat转发请求,然后对Apache服务器和tomcat和nginx理解就有点模糊了,然后今天查阅相关资料对使用场景和进行对比 2 Apache.Tomcat .Nginx名词解释 1 ) Apache Apache HTTP服务器是一个模块化
-
javascript 原型与原型链的理解及实例分析
本文实例讲述了javascript 原型与原型链的理解.分享给大家供大家参考,具体如下: javascript中一切皆对象,但是由于没有Class类的概念,所以就无法很好的表达对象与对象之间的关系了. 比如对象A与对象B之间,它们两个是相对独立的个体,互不干扰,对象A修改自身的属性不会影响到对象B. 虽然这很好,但是有一个问题,如果对象A与对象B都有一个方法 run() ,并且代码也一样,那对象A与对象B各自都独立拥有一份 run() 方法的完整代码,这是需要资源去保存的. 一旦我们程序中应用的
-
PHP call_user_func和call_user_func_array函数的简单理解与应用分析
本文实例讲述了PHP call_user_func和call_user_func_array函数的简单理解与应用.分享给大家供大家参考,具体如下: call_user_func():调用一个回调函数处理字符串, 可以用匿名函数,可以用有名函数,可以传递类的方法, 用有名函数时,只需传函数的名称 用类的方法时,要传类的名称和方法名 传递的第一个参数必须为函数名,或者匿名函数,或者方法 其他参数,可传一个参数,或者多个参数,这些参数会自动传递到回调函数中 而回调函数,可以通过传参,获取这些参数 返回
-
es6中class类静态方法,静态属性,实例属性,实例方法的理解与应用分析
本文实例讲述了es6中class类静态方法,静态属性,实例属性,实例方法.分享给大家供大家参考,具体如下: es6新增了一种定义对象实例的方法,使用class关键字定义类,与class相关的知识点也逐步火热起来,但是部分理解起来相对抽象,简单对class相关的知识点进行总结,更好的使用class.对于基本概念,请参见阮一峰老师的es6入门教程.本文主要总结class静态相关. 关于类有两个概念,1,类自身,:2,类的实例对象 总的来说:静态的是指向类自身,而不是指向实例对象,主要是归属不同,这是
-
mysql 悲观锁与乐观锁的理解及应用分析
本文实例讲述了mysql 悲观锁与乐观锁.分享给大家供大家参考,具体如下: 悲观锁与乐观锁是人们定义出来的概念,你可以理解为一种思想,是处理并发资源的常用手段. 不要把他们与mysql中提供的锁机制(表锁,行锁,排他锁,共享锁)混为一谈. 一.悲观锁 顾名思义,就是对于数据的处理持悲观态度,总认为会发生并发冲突,获取和修改数据时,别人会修改数据.所以在整个数据处理过程中,需要将数据锁定. 悲观锁的实现,通常依靠数据库提供的锁机制实现,比如mysql的排他锁,select .... for upd