Python爬虫进阶之Beautiful Soup库详解
一、Beautiful Soup库简介
BeautifulSoup4 是一个 HTML/XML 的解析器,主要的功能是解析和提取 HTML/XML 的数据。和 lxml 库一样。
lxml 只会局部遍历,而 BeautifulSoup4 是基于 HTML DOM 的,会加载整个文档,解析 整个 DOM 树,因此内存开销比较大,性能比较低。
BeautifulSoup4 用来解析 HTML 比较简单,API 使用非常人性化,支持 CSS 选择器,是 Python 标准库中的 HTML 解析器,也支持 lxml 解析器。
二、Beautiful Soup库安装
目前,Beautiful Soup 的最新版本是 4.x 版本,之前的版本已经停止开发,这里推荐使用 pip 来安装,安装命令如下:
pip install beautifulsoup4
查看 Beautiful Soup 安装是否成功
from bs4 import BeautifulSoup
soup = BeautifulSoup('<p>Hello</p>','html.parser')
print(soup.p.string)
注意:
□ 这里虽然安装的是 beautifulsoup4 这个包,但是引入的时候却是 bs4,因为这个包源 代码本身的库文件名称就是bs4,所以安装完成后,这个库文件就被移入到本机 Python3 的 lib 库里,识别到的库文件就叫作 bs4。
□ 因此,包本身的名称和我们使用时导入包名称并不一定是一致的。
三、Beautiful Soup 库解析器
Beautiful Soup 在解析时实际上依赖解析器,它除了支持 Python 标准库中的 HTML 解析器外,还支持一些第三方解析器(比如 lxml)。下表列出了 Beautiful Soup 支持的解析器。
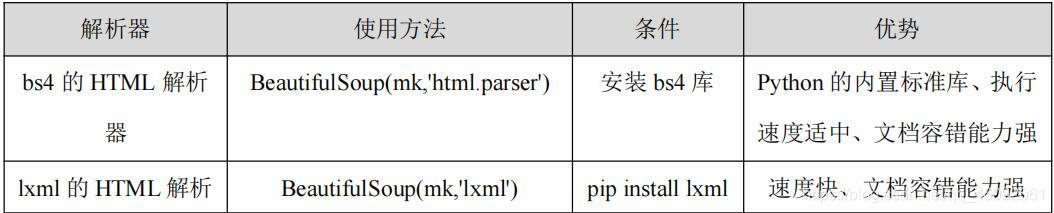

初始化 BeautifulSoup 使用 lxml,把第二个参数改为 lxml
from bs4 import BeautifulSoup
bs = BeautifulSoup('<p>Python</p>','lxml')
print(bs.p.string)
四、Beautiful Soup库基本用法

获取 title 节点,查看它的类型
from bs4 import BeautifulSoup
html = '''
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>
</html>
'''
# 获取bs4解析对象,使用解析器:lxml,html:解析内容
soup = BeautifulSoup(html, 'lxml')
print(soup.prettify())
print(soup.title.string)
执行结果如下所示:
The Dormouse's story
- 上述示例首先声明变量 html,它是一个 HTML 字符串。接着将它当作第一个参数传给 BeautifulSoup 对象,该对象的第二个参数为解析器的类型(这里使用 lxml),此时就完成了 BeaufulSoup 对象的初始化。
- 接着调用 soup 的各个方法和属性解析这串 HTML 代码了。
- 调用 prettify()方法。可以把要解析的字符串以标准的缩进格式输出。这里需要注意的是, 输出结果里面包含 body 和 html 节点,也就是说对于不标准的 HTML 字符串 BeautifulSoup, 可以自动更正格式。
- 调用 soup.title.string,输出 HTML 中 title 节点的文本内容。所以,soup.title 可以选出 HTML 中的 title 节点,再调用 string 属性就可以得到里面的文本了。
选择元素
# 获取bs4解析对象,使用解析器:lxml,html:解析内容 soup = BeautifulSoup(html, 'lxml') # 获取head标签 print(soup.head) # 获取p标签 print(soup.p)
运行结果:
<head><title>The Dormouse's story</title></head>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
- 从上述示例运行结果可以看到,获取 head 节点的结果是节点加其内部的所有内容。
- 最后,选择了 p 节点。不过这次情况比较特殊,我们发现结果是第一个 p 节点的内容,后面的几个 p 节点并没有选到。也就是说,当有多个节点时,这种选择方式只会选择到第一个匹配的节点,其他的后面节点都会忽略。
调用 name 属性获取节点的名称
# 获取bs4解析对象,使用解析器:lxml,html:解析内容 soup = BeautifulSoup(html, 'lxml') # 调用 name 属性获取节点的名称 print(soup.title.name)
运行结果:
title
调用 attrs 获取所有属性
# 调用 attrs 获取所有属性 print(soup.p.attrs) print(soup.p.attrs['name'])
运行结果:
{'class': ['title'], 'name': 'dromouse'}
dromouse
从上述运行结果可以看到,attrs 的返回结果是字典形式,它把选择节点的所有属性和属性值组合成一个字典。
如果要获取 name 属性,就相当于从字典中获取某个键值,只需要用中括号加属性名就可以了。例如,要获取 name 属性,就可以通过 attrs[‘name'] 来得到。
简单获取属性的方式
print(soup.p['name']) print(soup.p['class'])
这里需要注意的是,获取属性有的返回结果是字符串,有的返回结果是字符串组成的列表。
比如,name 属性的值是唯一的,返回的结果就是单个字符串。而对于 class,一个节点元素可能有多个 class,所以返回的是列表。
调用 string 属性获取节点元素包含的文本内容
print('调用 string 属性获取节点元素包含的文本内容')
print(soup.p.string)
嵌套选择
print('嵌套选择')
print(soup.head.title)
# 获取title的类型
print(type(soup.head.title))
# 获取标签内容
print(soup.head.title.string)
运行结果:
<title>The Dormouse's story</title>
<class 'bs4.element.Tag'>
The Dormouse's story
从上述示例运行结果可以看到,调用 head 之后再次调用 title 可以选择 title 节点元素。 输出了它的类型可以看到,它仍然是 bs4.element.Tag 类型。也就是说,我们在 Tag 类型的基础上再次选择得到的依然还是 Tag 类型,每次返回的结果都相同。
调用 children 属性,获取它的直接子节点
from bs4 import BeautifulSoup
html = '''
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story"> Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link3">Tillie</a> and they lived at the bottom of a well.
</p>
<p class="story">...</p>
'''
# 获取bs4解析对象,使用解析器:lxml,html:解析内容
soup = BeautifulSoup(html, 'lxml')
# 获取孩子结点
print(soup.p.children)
# 遍历孩子结点
# 将列表中元素与下标枚举为元组
# 获取p标签下的孩子标签
for i, child in enumerate(soup.p.children):
print(i, child)
执行结果:
<list_iterator object at 0x0CACF448>
0 Once upon a time there were three little sisters; and their names were
1 <a class="sister" href="http://example.com/elsie" id="link1">
<span>Elsie</span>
</a>
2
3 <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
4 and
5 <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
6 and they lived at the bottom of a well.
从上述示例运行结果可以看到,调用 children 属性,返回结果是生成器类型。用 for 循环输出相应的内容。
调用 parent 属性,获取某个节点元素的父节点
from bs4 import BeautifulSoup html = ''' <html> <head> <title>The Dormouse's story</title> </head> <body><p class="story"> Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link1"> <span>Elsie</span> </a> </p> <p class="story">...</p> ''' # 获取bs4解析对象,使用解析器:lxml,html:解析内容 soup = BeautifulSoup(html, 'lxml') # 获取父结点 print(soup.a.parent)
运行结果:
<p class="story"> Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
<span>Elsie</span>
</a>
</p>
从上述示例运行结果可以看到,我们选择的是第一个 a 节点的父节点元素,它的父节点 是 p 节点,输出结果便是 p 节点及其内部的内容。 需要注意的是,这里输出的仅仅是 a 节点的直接父节点,而没有再向外寻找父节点的祖 先节点。如果想获取所有的祖先节点,可以调用 parents 属性。
调用 parents 属性,获取某个节点元素的祖先节点
from bs4 import BeautifulSoup html = ''' <html> <body><p class="story"> <a href="http://example.com/elsie" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link1"> <span>Elsie</span> </a> </p> ''' # 获取bs4解析对象,使用解析器:lxml,html:解析内容 soup = BeautifulSoup(html, 'lxml') # 获取父结点 print(type(soup.a.parents)) # 获取类型 print(list(enumerate(soup.a.parents)))
运行结果:
[(0, <p class="story">
<a class="sister" href="http://example.com/elsie" id="link1">
<span>Elsie</span>
</a>
</p>), (1, <body><p class="story">
<a class="sister" href="http://example.com/elsie" id="link1">
<span>Elsie</span>
</a>
</p>
</body>), (2, <html>
<body><p class="story">
<a class="sister" href="http://example.com/elsie" id="link1">
<span>Elsie</span>
</a>
</p>
</body></html>), (3, <html>
<body><p class="story">
<a class="sister" href="http://example.com/elsie" id="link1">
<span>Elsie</span>
</a>
</p>
</body></html>)]
调用 next_sibling 和 previous_sibling 分别获取节点的下一个和上一个兄弟元素
from bs4 import BeautifulSoup
html = '''
<html>
<body>
<p class="story"> Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link1">
<span>Elsie</span>
</a> Hello
<a href="http://example.com/lacie" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" rel="external nofollow" rel="external nofollow" rel="external nofollow" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
'''
# 获取bs4解析对象,使用解析器:lxml,html:解析内容
soup = BeautifulSoup(html, 'lxml')
# 获取下一个结点的属性
print('Next Sibling', soup.a.next_sibling)
print('Previous Sibling', soup.a.previous_sibling)
运行结果:
Next Sibling Hello
Previous Sibling Once upon a time there were three little sisters; and their names were
五、方法选择器
上面所讲的选择方法都是通过属性来选择的,这种方法非常快,但是如果进行比较复杂的选择的话,它就比较烦琐,不够灵活了。
Beautiful Soup 还提供了一些查询方法,例如:find_all()和 find()等。
find_all 是查询所有符合条件的元素。给它传入一些属性或文本,就可以得到符合条件的元素,它的功能十分强大。
语法格式如下:
find_all(name , attrs , recursive , text , **kwargs)
find_all 方法传入 name 参数,根据节点名来查询元素
from bs4 import BeautifulSoup
html = '''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
# 获取bs4解析对象,使用解析器:lxml,html:解析内容
soup = BeautifulSoup(html, 'lxml')
for ul in soup.find_all(name='ul'):
print(ul.find_all(name='li'))
for li in ul.find_all(name='li'):
print(li.string)
结果如下:
[<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>]
Foo
Bar
Jay
[<li class="element">Foo</li>, <li class="element">Bar</li>]
Foo
Bar
从上述示例可以看到,调用 find_all()方法,name 参数值为 ul。返回结果是查询到的所有 ul 节点列表类型,长度为 2,每个元素依然都是 bs4.element.Tag 类型。因为都是 Tag 类型, 所以依然可以进行嵌套查询。再继续查询其内部的 li 节点,返回结果是 li 节点列表类型, 遍历列表中的每个 li,获取它的文本。
find_all 方法传入 attrs 参数,根据属性来查询
from bs4 import BeautifulSoup
html = '''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1" name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
# 获取bs4解析对象,使用解析器:lxml,html:解析内容
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(attrs={'id': 'list-1'}))
print(soup.find_all(attrs={'name': 'elements'}))
结果如下:
[<ul class="list" id="list-1" name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>]
[<ul class="list" id="list-1" name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>]
从上述示例可以看到,传入 attrs 参数,参数的类型是字典类型。比如,要查询 id 为 list-1 的节点,可以传入 attrs={‘id': ‘list-1'}的查询条件,得到的结果是列表形式,包含的内容就是符合 id 为 list-1 的所有节点。符合条件的元素个数是 1,长度为 1 的列表。
对于一些常用的属性,比如 id 和 class 等,可以不用 attrs 来传递。比如,要查询 id 为 list-1 的节点 ,可以直接传入 id 这个参数。
示例如下:
print(soup.find_all(id='list-1')) print(soup.find_all(class_='element'))
上述示例直接传入 id='list-1',就可以查询 id 为 list-1 的节点元素了。而对于 class 来 说,由于 class 在 Python 里是一个关键字,所以后面需要加一个下划线,即 class_='element', 返回的结果依然还是 Tag 组成的列表。
find_all 方法根据文本来查询
find_all 方法传入 text 参数可用来匹配节点的文本,传入的形式可以是字符串,可以是正则表达式对象。
from bs4 import BeautifulSoup
import re
html = '''
<div class="panel">
<div class="panel-body">
<a>Hello, this is a link</a>
<a>Hello, this is a link, too</a>
</div>
</div>
'''
# 获取bs4解析对象,使用解析器:lxml,html:解析内容
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(text=re.compile('link')))
运行结果
['Hello, this is a link', 'Hello, this is a link, too']
上述示例有两个 a 节点,其内部包含文本信息。这里在 find_all()方法中传入 text 参数, 该参数为正则表达式对象,结果返回所有匹配正则表达式的节点文本组成的列表。
除了 find_all()方法,还有 find()方法,不过后者返回的是单个元素,也就是第一个匹配的元素,而前者返回的是所有匹配的元素组成的列表。
find 方法查询第一个匹配的元素
from bs4 import BeautifulSoup
import re
html = '''
<<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
# 获取bs4解析对象,使用解析器:lxml,html:解析内容
soup = BeautifulSoup(html, 'lxml')
# 获取标签名为ul的标签体内容
print(soup.find(name='ul'))
# 获取返回结果的列表
print(type(soup.find(name='ul')))
# 查找标签中class是'list'
print(soup.find(class_='list'))
结果如下
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<class 'bs4.element.Tag'>
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
上述示例使用 find 方法返回结果不再是列表形式,而是第一个匹配的节点元素,类型依然是 Tag 类型。
六、CSS 选择器
Beautiful Soup 还提供了另外一种选择器,那就是 CSS 选择器。使用 CSS 选择器时,只 需要调用 select()方法,传入相应的 CSS 选择器即可。
CSS相关知识:
#element: id选择器.
element:类选择器
tag tag:派生选择器
通过依据元素在其位置的上下文关系来定义样式,你可以使标记更加简洁。
from bs4 import BeautifulSoup
import re
html = '''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
# 获取bs4解析对象,使用解析器:lxml,html:解析内容
soup = BeautifulSoup(html, 'lxml')
# 获取class=panel标签下panel_heading,类选择器
print(soup.select('.panel .panel-heading'))
# 派生选择器
print(soup.select('ul li'))
# id选择器+类选择器
lis = soup.select('#list-2 .element')
for l in lis:
print('GET TEXT', l.get_text())
print('String:', l.string)
结果如下
[<div class="panel-heading">
<h4>Hello</h4>
</div>]
[<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>, <li class="element">Foo</li>, <li class="element">Bar</li>]
GET TEXT Foo
String: Foo
GET TEXT Bar
String: Bar
上述示例,用了 3 次 CSS 选择器,返回的结果均是符合 CSS 选择器的节点组成的列表。 例如,select(‘ul li')则是选择所有 ul 节点下面的所有 li 节点,结果便是所有的 li 节点组成的列表。要获取文本,当然也可以用前面所讲的 string 属性。此外,还有一个方法,那就是 get_text()。
到此这篇关于Python爬虫进阶之Beautiful Soup库详解的文章就介绍到这了,更多相关Python Beautiful Soup库详解内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python BeautifulSoup库的安装与使用
1.BeautifulSoup简介 BeautifulSoup4和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据. BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐使用lxml 解析器. Beautiful Soup自动将输入文档转换为Unicode编码,
-
Python使用BeautifulSoup库解析HTML基本使用教程
BeautifulSoup是Python的一个第三方库,可用于帮助解析html/XML等内容,以抓取特定的网页信息.目前最新的是v4版本,这里主要总结一下我使用的v3版本解析html的一些常用方法. 准备 1.Beautiful Soup安装 为了能够对页面中的内容进行解析,本文使用Beautiful Soup.当然,本文的例子需求较简单,完全可以使用分析字符串的方式. 执行 sudo easy_install beautifulsoup4 即可安装. 2.requests模块的安装 reque
-

Python中使用Beautiful Soup库的超详细教程
1. Beautiful Soup的简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能.它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序. Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码.你不需要考虑编码方式,除非文档没有指
-
使用python BeautifulSoup库抓取58手机维修信息
直接上代码: 复制代码 代码如下: #!/usr/bin/python# -*- coding: utf-8 -*- import urllib import os,datetime,string import sys from bs4 import BeautifulSoup reload(sys) sys.setdefaultencoding('utf-8') __BASEURL__ = 'http://bj.58.com/' __INITURL__ = "http://bj.58.com/
-
Python获取基金网站网页内容、使用BeautifulSoup库分析html操作示例
本文实例讲述了Python获取基金网站网页内容.使用BeautifulSoup库分析html操作.分享给大家供大家参考,具体如下: 利用 urllib包 获取网页内容 #引入包 from urllib.request import urlopen response = urlopen("http://fund.eastmoney.com/fund.html") html = response.read(); #这个网页编码是gb2312 #print(html.decode("
-
python爬虫beautifulsoup库使用操作教程全解(python爬虫基础入门)
[python爬虫基础入门]系列是对python爬虫的一个入门练习实践,旨在用最浅显易懂的语言,总结最明了,最适合自己的方法,本人一直坚信,总结才会使人提高 1. BeautifulSoup库简介 BeautifulSoup库在python中被美其名为"靓汤",它和和 lxml 一样也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据.BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,若在没用安装此库的情况下
-
python用BeautifulSoup库简单爬虫实例分析
会用到的功能的简单介绍 1.from bs4 import BeautifulSoup #导入库 2.请求头herders headers={'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.110 Safari/537.36','referer':"www.mmjpg.com" } all_url = 'http://ww
-
Python爬虫进阶之Beautiful Soup库详解
一.Beautiful Soup库简介 BeautifulSoup4 是一个 HTML/XML 的解析器,主要的功能是解析和提取 HTML/XML 的数据.和 lxml 库一样. lxml 只会局部遍历,而 BeautifulSoup4 是基于 HTML DOM 的,会加载整个文档,解析 整个 DOM 树,因此内存开销比较大,性能比较低. BeautifulSoup4 用来解析 HTML 比较简单,API 使用非常人性化,支持 CSS 选择器,是 Python 标准库中的 HTML 解析器,也支
-
python爬虫之BeautifulSoup 使用select方法详解
本文介绍了python爬虫之BeautifulSoup 使用select方法详解 ,分享给大家.具体如下: <html><head><title>The Dormouse's story</title></head> <body> <p class="title" name="dromouse"><b>The Dormouse's story</b></
-
Python高级文件操作之shutil库详解
前言 什么算是高层的文件操作呢? 普通的文件操作,我们一般只涉及创建文件,文件夹以及写入文件等等.假如我现在需要复制一个文件的内容到另一个文件之中,用pathlib等都只能先打开复制文件,然后进行将其读出来保存,然后再写入新的文件,这种普通的复制操作,无形之中增加了许多步骤. 而shutil库可以直接完成复制符间的操作,同时还支持归档.本篇,将详细介绍文件的高层次操作. 一.copyfile() copyfile()函数用于将一个文件的内容复制到另一个文件之中,准备的来说,它不是copy内容,而
-
Python爬虫urllib和requests的区别详解
我们讲了requests的用法以及利用requests简单爬取.保存网页的方法,这节课我们主要讲urllib和requests的区别. 1.获取网页数据 第一步,引入模块. 两者引入的模块是不一样的,这一点显而易见. 第二步,简单网页发起的请求. urllib是通过urlopen方法获取数据. requests需要通过网页的响应类型获取数据. 第三步,数据封装. 对于复杂的数据请求,我们只是简单的通过urlopen方法肯定是不行的.最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕
-
python爬虫开发之Beautiful Soup模块从安装到详细使用方法与实例
python爬虫模块Beautiful Soup简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能.它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序.Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码.你不需要考虑编码方式,除非
-
python 爬虫出现403禁止访问错误详解
python 爬虫解决403禁止访问错误 在Python写爬虫的时候,html.getcode()会遇到403禁止访问的问题,这是网站对自动化爬虫的禁止,要解决这个问题,需要用到python的模块urllib2模块 urllib2模块是属于一个进阶的爬虫抓取模块,有非常多的方法,比方说连接url=http://blog.csdn.NET/qysh123对于这个连接就有可能出现403禁止访问的问题 解决这个问题,需要以下几步骤: <span style="font-size:18px;&q
-
python爬虫爬取微博评论案例详解
前几天,杨超越编程大赛火了,大家都在报名参加,而我也是其中的一员. 在我们的项目中,我负责的是数据爬取这块,我主要是把对于杨超越 的每一条评论的相关信息. 数据格式:{"name":评论人姓名,"comment_time":评论时间,"comment_info":评论内容,"comment_url":评论人的主页} 以上就是我们需要的信息. 爬虫前的分析: 以上是杨超越的微博主页,这是我们首先需要获取到的内容. 因为我们需要等
-
Python爬虫之正则表达式的使用教程详解
正则表达式的使用 re.match(pattern,string,flags=0) re.match尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none 参数介绍: pattern:正则表达式 string:匹配的目标字符串 flags:匹配模式 正则表达式的匹配模式: 最常规的匹配 import re content ='hello 123456 World_This is a Regex Demo' print(len(content)) resul
-
Python爬虫JSON及JSONPath运行原理详解
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.适用于进行数据交互的场景,比如网站前台与后台之间的数据交互. JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python, PHP 和 Java. JsonPath 对于 JSON 来说,相当于 XPATH 对于 XML. JsonPath与XPath语法对
-
Python爬虫爬取新闻资讯案例详解
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 一个简单的Python资讯采集案例,列表页到详情页,到数据保存,保存为txt文档,网站网页结构算是比较规整,简单清晰明了,资讯新闻内容的采集和保存! 应用到的库 requests,time,re,UserAgent,etree import requests,time,re from fake_useragent import UserAgent from lxml im