SpringBoot 如何使用sharding jdbc进行分库分表
目录
- 基于4.0版本,Springboot2.1
- 在pom里确保有如下引用
- 里面我profiles.active了另一个
- 之后手工把表都建好
- 写个测试代码
- 需要注意一个坑
基于4.0版本,Springboot2.1
之前写过一篇使用sharding-jdbc进行分库分表的文章,不过当时的版本还比较早,现在已经不能用了。这一篇是基于最新版来写的。
新版已经变成了shardingsphere了,https://shardingsphere.apache.org/。
有点不同的是,这一篇,我们是采用多数据源,仅对一个数据源进行分表。也就是说在网上那些jpa多数据源的配置,用sharding jdbc一样能完成。
也就是说我们有两个库,一个库是正常使用,另一个库其中的一个表进行分表。
老套路,我们还是使用Springboot进行集成,
在pom里确保有如下引用
<sharding-sphere.version>4.0.0-RC1</sharding-sphere.version>
<!-- 分库分表-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-core-common</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<!-- 分库分表 end-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
spring:
application:
name: t3cc
profiles:
active: sharding-databases-tables
# datasource:
# primary:
# jdbc-url: jdbc:mysql://${MYSQL_HOST:localhost}:${MYSQL_PORT:3306}/${DB_NAME:dmp_t3cc}?useUnicode=true&characterEncoding=UTF8&serverTimezone=Hongkong
# username: ${MYSQL_USER:root}
# password: ${MYSQL_PASS:root}
# secondary:
# jdbc-url: jdbc:mysql://xxxxxxxxxxxxx/xxxxxx?useUnicode=true&characterEncoding=UTF8&serverTimezone=Hongkong
# username: xxxxx
# password: xxxxxxx
jpa:
database: mysql
database-platform: org.hibernate.dialect.MySQL5InnoDBDialect #不加这句则默认为myisam引擎
hibernate:
ddl-auto: none
naming:
physical-strategy: org.springframework.boot.orm.jpa.hibernate.SpringPhysicalNamingStrategy
open-in-view: true
properties:
enable_lazy_load_no_trans: true
show-sql: true
yml里还是老套路,大家注意,我把之前的多数据源的配置给注释掉了,改成使用sharding来完成多数据源。
里面我profiles.active了另一个
sharding-databases-tables.yml
db:
one: primary
two: secondary
spring:
shardingsphere:
datasource:
names: ${db.one},${db.two}
primary:
type: com.zaxxer.hikari.HikariDataSource
jdbc-url: jdbc:mysql://${MYSQL_HOST:localhost}:${MYSQL_PORT:3306}/${DB_NAME:dmp_t3cc}?useUnicode=true&characterEncoding=UTF8&serverTimezone=Hongkong
username: ${MYSQL_USER:root}
password: ${MYSQL_USER:root}
max-active: 16
secondary:
type: com.zaxxer.hikari.HikariDataSource
jdbc-url: jdbc:mysql://xxxxxxx:3306/t3cc?useUnicode=true&characterEncoding=UTF8&serverTimezone=Hongkong
username: xxx
password: xxxxxx
max-active: 16
sharding:
tables:
pt_call_info:
actual-data-nodes: ${db.one}.pt_call_info_$->{1..14}
table-strategy:
inline:
sharding-column: today
algorithm-expression: pt_call_info_$->{today}
key-generator:
column: id
type: SNOWFLAKE
pre_cc_project:
actual-data-nodes: ${db.two}.pre_cc_project
pre_cc_biztrack:
actual-data-nodes: ${db.two}.pre_cc_biztrack
可以看到datasource里,定义了2个数据源,names=primary,secondary,这个名字随便起。之后分别对每个数据源配置了type、url等基本信息。
在sharding里,我针对要被分表的pt_call_info表做了配置,分为14个表pt_call_info_1到pt_call_info_14,分表的原则是根据today这个字段,today为1就分到pt_call_info_1这个表。这也是我这个数据源,唯一要做配置的表。
另外,secondary这个数据源里,也有两个表,但我不想分表,只是当成普通的数据源进行操作。所以,我只是单独列出来他们的表名,并指定actual-data-nodes为第二个数据源的表名。这里是必须要列出来所有表的,无论是否需要分表,不然对表操作时,会报错找不到表。所以需要手工指定。
配完这个yml就ok了,别的什么都不用配了。也不需要像之前的多数据源时,像如下的配置都不用了。不需要指定model和repository的包位置什么的。
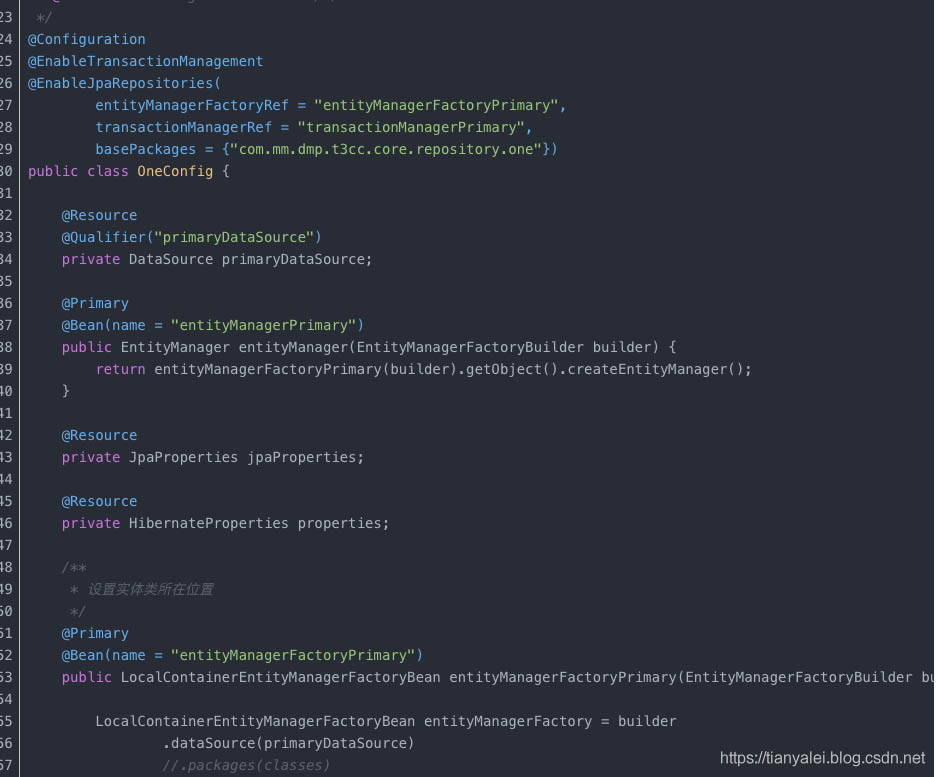
当yml配置好后,就可以把两个数据源的model和Repository放在任意的包下,不影响。
无论是对哪个表进行分表,都还是正常定义这个entity就行了。譬如下面就是我用来分表的model,就是个普通的entity。
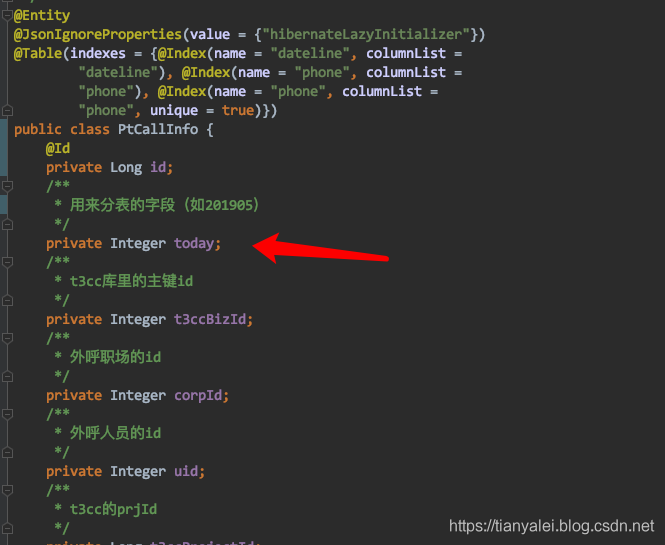
之后手工把表都建好
然后就可以像平时一样操作这个model类了。
@RunWith(SpringRunner.class)
@SpringBootTest
public class T3ccApplicationTests {
@Resource
private ProjectManager projectManager;
@Resource
private PtCallInfoManager ptCallInfoManager;
@Test
public void contextLoads() {
List<PreCcProject> preCcProjectList = projectManager.findAll();
System.out.println(preCcProjectList.size());
for (int i = 1; i <= 14; i++) {
PtCallInfo ptCallInfo = new PtCallInfo();
ptCallInfo.setId((Long) new SnowflakeShardingKeyGenerator().generateKey());
ptCallInfo.setToday(i);
ptCallInfoManager.add(ptCallInfo);
}
}
}
写个测试代码
分别从第二个数据源取值,从第一个数据源插入值,查看分表情况。
注意,id是使用特定的算法生成的,避免分表后的主键冲突。

运行后,可以看到分表成功。
需要注意一个坑
不要使用jpa的saveAll功能,在sharding-jdbc中,用单条去添加,如果你用了saveAll,则会失败,插入错误的数据。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Springboot2.x+ShardingSphere实现分库分表的示例代码
之前一篇文章中我们讲了基于Mysql8的读写分离(文末有链接),这次来说说分库分表的实现过程. 概念解析 垂直分片 按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用. 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务.而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库. 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案. 垂直分片往往需要对架构和设计进行调整.通常来讲,是来不及应对互联网业务需求快速变化
-

SpringBoot整合sharding-jdbc实现自定义分库分表的实践
目录 一.前言 二.简介 1.分片键 2.分片算法 三.程序实现 一.前言 SpringBoot整合sharding-jdbc实现分库分表与读写分离 本文将通过自定义算法来实现定制化的分库分表来扩展相应业务 二.简介 1.分片键 用于数据库/表拆分的关键字段 ex: 用户表根据user_id取模拆分到不同的数据库中 2.分片算法 可参考:https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere
-
SpringBoot整合sharding-jdbc实现分库分表与读写分离的示例
目录 一.前言 二.数据库表准备 三.整合 四.docker-compose部署mysql主从 五.本文案例demo源码 一.前言 本文将基于以下环境整合sharding-jdbc实现分库分表与读写分离 springboot2.4.0 mybatis-plus3.4.3.1 mysql5.7主从 https://github.com/apache/shardingsphere 二.数据库表准备 温馨小提示:此sql执行时,如果之前有存在相应库和表会进行自动删除后再创建! DROP DATABAS
-
SpringBoot 如何使用sharding jdbc进行分库分表
目录 基于4.0版本,Springboot2.1 在pom里确保有如下引用 里面我profiles.active了另一个 之后手工把表都建好 写个测试代码 需要注意一个坑 基于4.0版本,Springboot2.1 之前写过一篇使用sharding-jdbc进行分库分表的文章,不过当时的版本还比较早,现在已经不能用了.这一篇是基于最新版来写的. 新版已经变成了shardingsphere了,https://shardingsphere.apache.org/. 有点不同的是,这一篇,我们是采用多
-
SpringBoot+MybatisPlus+Mysql+Sharding-JDBC分库分表
目录 一.序言 1.组件及版本选择 2.预期目标 二.代码实现 (一)素材准备 1.实体类 2.Mapper类 3.全局配置文件 (二)增删查改 1.保存数据 2.查询列表数据 3.分页查询数据 4.查询详情 5.删除数据 6.修改数据 三.理论分析 1.选择分片列 2.扩容 一.序言 在实际业务中,单表数据增长较快,很容易达到数据瓶颈,比如单表百万级别数据量.当数据量继续增长时,数据的查询性能即使有索引的帮助下也不尽如意,这时可以引入数据分库分表技术. 本文将基于SpringBoot+Myba
-
springboot jpa分库分表项目实现过程详解
这篇文章主要介绍了springboot jpa分库分表项目实现过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 分库分表场景 关系型数据库本身比较容易成为系统瓶颈,单机存储容量.连接数.处理能力都有限.当单表的数据量达到1000W或100G以后,由于查询维度较多,即使添加从库.优化索引,做很多操作时性能仍下降严重.此时就要考虑对其进行切分了,切分的目的就在于减少数据库的负担,缩短查询时间. 分库分表用于应对当前互联网常见的两个场景--大数
-
springboot整合shardingjdbc实现分库分表最简单demo
一.概览 1.1 简介 ShardingSphere-JDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务. 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架. 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC. 支持任何第三方的数据库连接池,如:DBCP,
-
SpringBoot 2.0 整合sharding-jdbc中间件实现数据分库分表
一.水平分割 1.水平分库 1).概念: 以字段为依据,按照一定策略,将一个库中的数据拆分到多个库中. 2).结果 每个库的结构都一样:数据都不一样: 所有库的并集是全量数据: 2.水平分表 1).概念 以字段为依据,按照一定策略,将一个表中的数据拆分到多个表中. 2).结果 每个表的结构都一样:数据都不一样: 所有表的并集是全量数据: 二.Shard-jdbc 中间件 1.架构图 2.特点 1).Sharding-JDBC直接封装JDBC API,旧代码迁移成本几乎为零. 2).适
-
SpringBoot实现分库分表
目录 一.statementHandler对象的定义 二.prepare方法 1.首先prepare方法是用来编译SQL 2.那就是之前说的那几个具体的StatementHandler对象 3.parameterize方法 4.query/update方法 方案:可以使用拦截器拦截mybatis框架,在执行SQL前对SQL语句根据路由字段进行分库分表操作,下例只做分表功能 @Intercepts:申明需要拦截的方法 拦截StatementHandler对象 一.statementHandler对
-
Java使用Sharding-JDBC分库分表进行操作
目录 主从库搭建 Compose File Master 配置 Slave 配置 主从配置 创建分库分表 Order 1 库 Order 2 库 User 库 Sharding-JDBC 引入 Sharding-JDBC 配置 可选配置 数据源配置 主从复制配置 数据节点配置 Demo 程序 Sharding-JDBC 是无侵入式的 MySQL 分库分表操作工具,所有库表设置仅需要在配置文件中配置即可,无须修改任何代码. 本文写了一个 Demo,使用的是 SpringBoot 框架,通过 Doc
-
浅谈订单重构之 MySQL 分库分表实战篇
目录 一.目标 二.环境准备 1.基本信息 2.数据库环境准备 3.建库 & 导入分表 三.配置&实践 1.pom文件 2.常量配置 3.yml 配置 4.分库分表策略 5.dao层编写 6.单元测试 四.总结 一.目标 本文将完成如下目标: 分表数量: 256 分库数量: 4 以用户ID(user_id) 为数据库分片Key 最后测试订单创建,更新,删除, 单订单号查询,根据user_id查询列表操作. 架构图: 表结构如下: CREATE TABLE `order_XXX` (