深入浅析Python数据分析的过程记录
目录
- 一、需求介绍
- 二、以第1、个为例进行数据分析
- 1、获取一天的数据
- 2、开始一天的数据的分析
- 3、循环日期进行多天的数据分析:
- 4、将数据写入Excel表格中
- 三、完整的代码展示:
- 总结
一、需求介绍
该需求主要是分析某一种数据的历史数据。
客户的需求是根据该数据的前两期的情况,如果存在某个斜着的两个数字相等,那么就买第三期的同一个位置处的彩票,
对于1、,如果相等的数字是:1-5,那就买6-10,如果相等的数字是:6-10,那就买1-5;
对于2、,如果相等的数字是:1-5,那就买1-5,如果相等的数字是:6-10,,那就买6-10。
然后,根据这个方案,有可能会买中,但是也有可能买不中,于是,客户希望我可以统计出来在100天中,按照这种方法,连续6次以及6次以上的购买彩票才能够命中一次奖的次数以及分别所对应的时间,对于这个案例,我们下面详细分析。
二、以第1、个为例进行数据分析
(在这里,我们先利用 Jupyter Notebook 来进行分析,然后,在得到成果以后,利用 Pycharm 来进行完整的程序设计。)
1、获取一天的数据
打开如下图所示的界面可以获取到网址以及请求头:
1、网址(历史数据的网址)
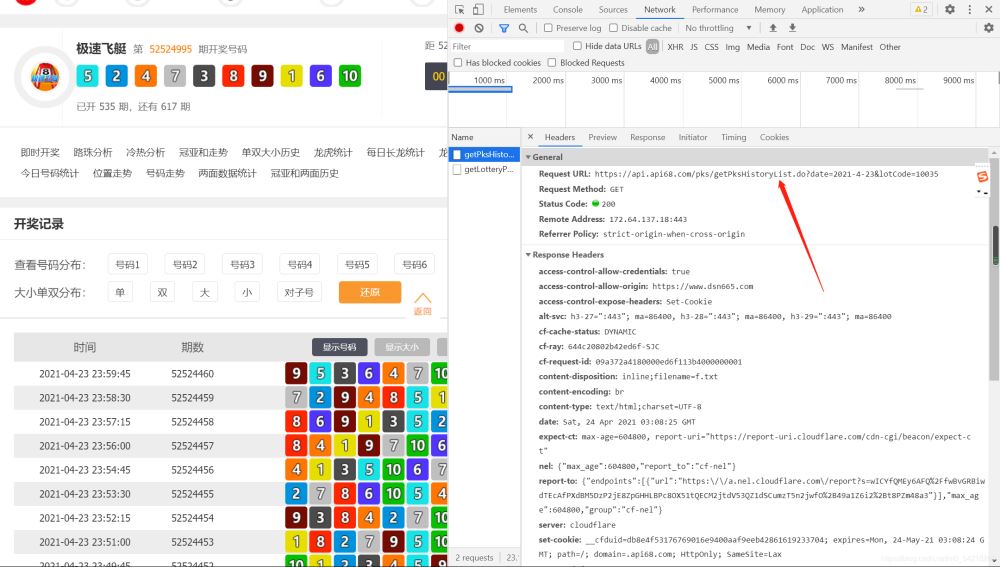
2、请求头

然后我们在程序中进行代码书写获取数据:
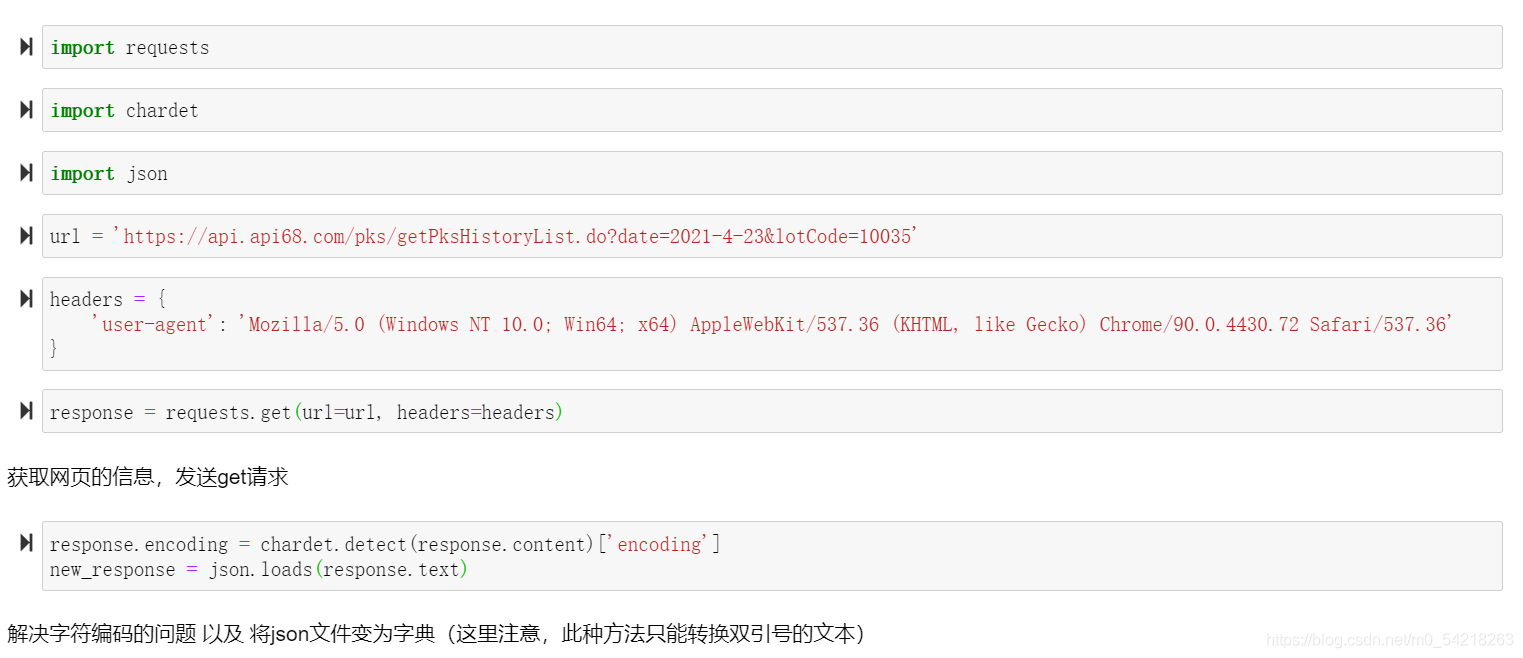

然后进行一定的预处理:

2、开始一天的数据的分析
这里我们直接展示代码:
def reverse_list(lst):
"""
准换列表的先后顺序
:param lst: 原始列表
:return: 新的列表
"""
return [ele for ele in reversed(lst)]
low_list = ["01", "02", "03", "04", "05"]
# 设置比较小的数字的列表
high_list = ["06", "07", "08", "09", "10"]
# 设置比较大的数字的列表
N = 0
# 设置一个数字N来记录一共有多少期可以购买
n = 0
# 设置一个数字n来记录命中了多少期彩票
record_number = 1
# 设置记录数据的一个判断值
list_data_number = []
# 设置一个空的列表来存储一天之中的连续挂掉的期数
dict_time_record = {}
# 设置一个空的字典来存储连挂掉的期数满足所列条件的时间节点
for k in range(1152):
# 循环遍历所有的数据点
if k < 1150:
new_result1 = reverse_list(new_response["result"]["data"])[k]
# 第一期数据
new_result2 = reverse_list(new_response["result"]["data"])[k + 1]
# 第二期数据
new_result3 = reverse_list(new_response["result"]["data"])[k + 2]
# 第三期数据
data1 = new_result1['preDrawCode'].split(',')
# 第一期数据
data2 = new_result2['preDrawCode'].split(',')
# 第二期数据
data3 = new_result3['preDrawCode'].split(',')
# 第三期数据
for m in range(10):
# 通过循环来判断是否满足购买的条件,并且实现一定的功能
if m == 0:
if data2[0] == data1[1]:
# 如果相等就要结束循环
N += 1
# 可以购买的期数应该要自加一
if (data2[0] in low_list and data3[0] in low_list) or (data2[0] in high_list and data3[0] in high_list):
n += 1
# 命中的期数应该要自加一
# 如果命中了的话,本轮结束,开启下一轮
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
# 如果已经有了这个键,那么值添加时间点
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
# 如果没有这个键,那么添加一个键值对,值为一个列表,而且初始化为当前的时间
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
record_number = 1
# 初始化下一轮的开始
else:
record_number += 1
# 如果没有命中的话,次数就应该要自加一
break
# 如果满足相等的条件就要结束循环
elif m == 9:
# 与上面差不多的算法
if data2[9] == data1[8]:
# 如果相等
N += 1
if (data2[9] in low_list and data3[9] in low_list) or (data2[9] in high_list and data3[9] in high_list):
n += 1
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
record_number = 1
else:
record_number += 1
break
else:
# 与上面差不多的算法
if data2[m] == data1[m + 1] or data2[m] == data1[m - 1]:
# 如果相等
N += 1
if (data2[m] in low_list and data3[m] in low_list) or (data2[m] in high_list and data3[m] in high_list):
n += 1
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
record_number = 1
else:
record_number += 1
break
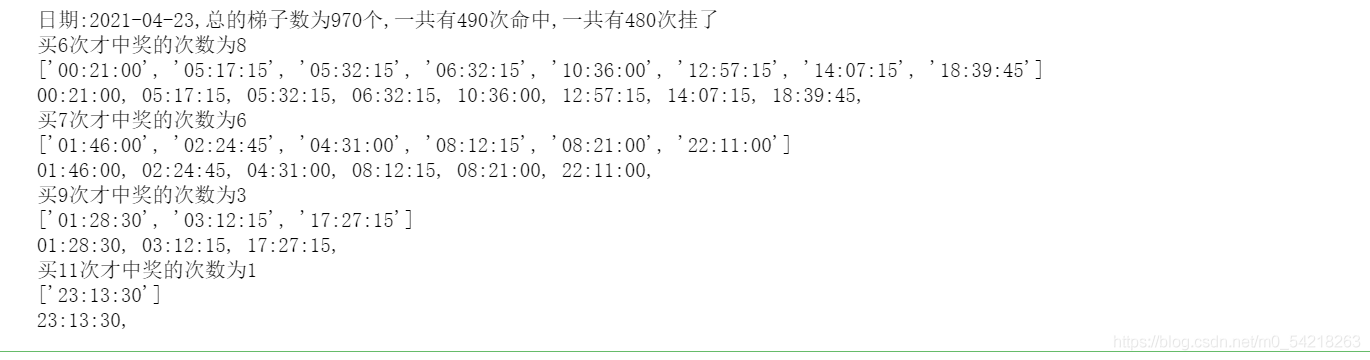
print(f"日期:{new_response['result']['data'][0]['preDrawTime'][:10]},总的梯子数为{N}个,一共有{n}次命中,一共有{N - n}次挂了")
# 打印时间,以及,可以购买的期数,命中的期数,没有命中的期数
list_data_number.sort()
# 按照大小顺序来进行排序
dict_record = {}
# 设置空字典进行记录
for i in list_data_number:
if f"{i}" in dict_record.keys(): # 判断是否已经有了这个数字?
dict_record[f"{i}"] += 1
# 如果有的话,那么就会自加一
else: # 如果没有的话,那么就会创建并且赋值等于 1
dict_record[f"{i}"] = 1
# 创建一个新的字典元素,然后进行赋值为 1
for j in dict_record.keys():
if (int(j) >= 6) and (int(j) < 15):
# 实际的结果表明,我们需要的是大于等于6期的数据,而没有出现大于15的数据,因此有这样的一个关系式
print(f"买{j}次才中奖的次数为{dict_record[j]}")
# 打印相关信息
print(dict_time_record[j])
str0 = ""
for letter in dict_time_record[j]:
str0 += letter
str0 += ", "
print(str0)
# 打印相关信息
运行结果的展示如下图所示:
3、循环日期进行多天的数据分析:
首先设置一个事件列表来记录需要统计哪些天的数据:
代码:
data_list = []
for h in range(31):
data_list.append(f'1-{h + 1}')
for h in range(28):
data_list.append(f'2-{h + 1}')
for h in range(31):
data_list.append(f'3-{h + 1}')
for h in range(20):
data_list.append(f'4-{h + 1}')
通过上述的代码,我们即实现了时间列表的设置,然后我们循环遍历这个列表访问不同日期的彩票数据即就是得到了不同时间的数据,然后再利用上述的分析方法来进行数据分析,即就是可以得到了多天的彩票数据分析的结果了。
4、将数据写入Excel表格中
这里我们可以采用xlwt 模块来进行excel表格的写入操作啦,具体的写入就不必过多赘述了。
三、完整的代码展示:
一下是完整的代码:
import requests
import chardet
import json
import xlwt # excel 表格数据处理的对应模块
def reverse_list(lst):
"""
准换列表的先后顺序
:param lst: 原始列表
:return: 新的列表
"""
return [ele for ele in reversed(lst)]
data_list = []
for h in range(31):
data_list.append(f'1-{h + 1}')
for h in range(28):
data_list.append(f'2-{h + 1}')
for h in range(31):
data_list.append(f'3-{h + 1}')
for h in range(20):
data_list.append(f'4-{h + 1}')
wb = xlwt.Workbook() # 创建 excel 表格
sh = wb.add_sheet('彩票分析数据处理') # 创建一个 表单
sh.write(0, 0, "日期")
sh.write(0, 1, "梯子数目")
sh.write(0, 2, "命中数目")
sh.write(0, 3, "挂的数目")
sh.write(0, 4, "6次中的数目")
sh.write(0, 5, "6次中的时间")
sh.write(0, 6, "7次中的数目")
sh.write(0, 7, "7次中的时间")
sh.write(0, 8, "8次中的数目")
sh.write(0, 9, "8次中的时间")
sh.write(0, 10, "9次中的数目")
sh.write(0, 11, "9次中的时间")
sh.write(0, 12, "10次中的数目")
sh.write(0, 13, "10次中的时间")
sh.write(0, 14, "11次中的数目")
sh.write(0, 15, "11次中的时间")
sh.write(0, 16, "12次中的数目")
sh.write(0, 17, "12次中的时间")
sh.write(0, 18, "13次中的数目")
sh.write(0, 19, "13次中的时间")
sh.write(0, 20, "14次中的数目")
sh.write(0, 21, "14次中的时间")
# wb.save('test4.xls')
sheet_seek_position = 1
# 设置表格的初始位置为 1
for data in data_list:
low_list = ["01", "02", "03", "04", "05"]
high_list = ["06", "07", "08", "09", "10"]
N = 0
n = 0
url = f'https://api.api68.com/pks/getPksHistoryList.do?date=2021-{data}&lotCode=10037'
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/90.0.4430.72 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
response.encoding = chardet.detect(response.content)['encoding']
new_response = json.loads(response.text)
sh.write(sheet_seek_position, 0, new_response['result']['data'][0]['preDrawTime'][:10])
# 在表格的第一个位置处写入时间,意即:data
record_number = 1 # 记录数据的一个判断值,设置为第一次,应该是要放在最外面的啦
list_data_number = []
# 设置一个空列表来存储一天之中的连续挂的期数
dict_time_record = {}
for k in range(1152):
# record_number = 1,应该要放外面
# 记录数据的一个判断值,设置为第一次
if k < 1150:
new_result1 = reverse_list(new_response["result"]["data"])[k]
new_result2 = reverse_list(new_response["result"]["data"])[k + 1]
new_result3 = reverse_list(new_response["result"]["data"])[k + 2]
data1 = new_result1['preDrawCode'].split(',')
data2 = new_result2['preDrawCode'].split(',')
data3 = new_result3['preDrawCode'].split(',')
for m in range(10):
if m == 0:
if data2[0] == data1[1]:
N += 1
if (data2[0] in low_list and data3[0] in high_list) or (data2[0] in high_list and data3[0] in low_list):
n += 1
# 如果命中了的话,本轮结束,开启下一轮
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
# print(record_number)
record_number = 1 # 初始化
else:
record_number += 1 # 没中,次数加一
# 自加一
break
elif m == 9:
if data2[9] == data1[8]:
N += 1
if (data2[9] in low_list and data3[9] in high_list) or (data2[9] in high_list and data3[9] in low_list):
n += 1
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
# print(record_number)
record_number = 1
else:
record_number += 1
break
else:
if data2[m] == data1[m + 1] or data2[m] == data1[m - 1]:
N += 1
if (data2[m] in low_list and data3[m] in high_list) or (data2[m] in high_list and data3[m] in low_list):
n += 1
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
# print(record_number)
record_number = 1
else:
record_number += 1
break
print(f"日期:{new_response['result']['data'][0]['preDrawTime'][:10]},总的梯子数为{N}个,一共有{n}次命中,一共有{N - n}次挂了")
sh.write(sheet_seek_position, 1, N)
sh.write(sheet_seek_position, 2, n)
sh.write(sheet_seek_position, 3, N - n)
# new_list_data_number = list_data_number.sort()
list_data_number.sort()
# 进行排序
dict_record = {}
# 设置空字典
for i in list_data_number:
if f"{i}" in dict_record.keys(): # 判断是否已经有了这个数字?
dict_record[f"{i}"] += 1
# 如果有的话,那么就会自加一
else: # 如果没有的话,那么就会创建并且赋值等于 1
dict_record[f"{i}"] = 1
# 创建一个新的字典元素,然后进行赋值为 1
# print(dict_record)
# print(f"买彩票第几次才中奖?")
# print(f"按照我们的规律买彩票的情况:")
for j in dict_record.keys():
if (int(j) >= 6) and (int(j) < 15):
print(f"买{j}次才中奖的次数为{dict_record[j]}")
print(dict_time_record[j])
str0 = ""
for letter in dict_time_record[j]:
str0 += letter
str0 += ", "
print(str0)
sh.write(sheet_seek_position, 4 + (int(j) - 6) * 2, dict_record[j])
# 写入几次
sh.write(sheet_seek_position, 4 + (int(j) - 6) * 2 + 1, str0[:-2])
# 注意这里应该要改为 -2
# 写入几次对应的时间
# print(j)
sheet_seek_position += 1
# 每次写完了以后,要对位置进行换行,换到下一行,从而方便下一行的写入
# 保存
wb.save('极速飞艇彩票分析结果.xls')
运行结果展示:
展示1、

展示2、

从而,我们便解决了极速飞艇的彩票的数据分析
然后,我们只需要稍稍改变一点点算法,其他的部分是完全一样的啦,从而即就是可以实现极速赛车的数据分析了啦。
修改的代码在下面列出来了:
for m in range(10):
if m == 0:
if data2[0] == data1[1]:
N += 1
if (data2[0] in low_list and data3[0] in low_list) or (data2[0] in high_list and data3[0] in high_list):
n += 1
# 如果命中了的话,本轮结束,开启下一轮
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
# print(record_number)
record_number = 1 # 初始化
else:
record_number += 1 # 没中,次数加一
# 自加一
break
elif m == 9:
if data2[9] == data1[8]:
N += 1
if (data2[9] in low_list and data3[9] in low_list) or (data2[9] in high_list and data3[9] in high_list):
n += 1
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
# print(record_number)
record_number = 1
else:
record_number += 1
break
else:
if data2[m] == data1[m + 1] or data2[m] == data1[m - 1]:
N += 1
if (data2[m] in low_list and data3[m] in low_list) or (data2[m] in high_list and data3[m] in high_list):
n += 1
list_data_number.append(record_number)
if f"{record_number}" in dict_time_record.keys():
dict_time_record[f"{record_number}"].append(new_result3['preDrawTime'][11:])
else:
dict_time_record[f"{record_number}"] = [new_result3['preDrawTime'][11:]]
# print(record_number)
record_number = 1
else:
record_number += 1
break
总结
总而言之,这个就是我学习 Python 到现在为止所接的第一单啦,这个需求不得不说确实是比较简单的啦,但是,我在完成这个任务的过程中,的确是学到了以前一些我并不太注意的东西,同时呢,也熟练的掌握了一些编程的技巧,虽然说这种比较简单的活报酬不会太高,但是,我认为在这个过程中我确实学到了不少东西,同时也成长了不少,因此,无论怎么说,其实也都还是挺不错的啦。
最后呢如果想了解我的第一次接单的程序运行实例,可以参见我的资源里面的“第一次接单案例”视频啦。。
最后感谢阅读啦
到此这篇关于Python数据分析的过程记录的文章就介绍到这了,更多相关Python数据分析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python数据分析基础之文件的读取
目录 一·Numpy库中操作文件 1.操作csv文件 2.在pycharm中操作csv文件 3.其他情况(.npy类型文件) 二·Pandas库中操作文件 1.操作csv文件 2.从剪贴板上复制数据 3.读取excel或xlsx文件 三·补充 1.常用 2.pandas中读取文件的函数 总结 前言:如果你使用的是Anaconda中的Jupyter,则不需要下载Pands和Numpy库:如果你使用的是pycharm或其他集成环境,则需要Pands和Numpy库 一·Numpy库中操作文件 1.操作
-
python数据分析Numpy库的常用操作
numpy库的引入: import numpy as np 1.numpy对象基础属性的查询 lst = [[1, 2, 3], [4, 5, 6]] def numpy_type(): print(type(lst)) data = np.array(lst, dtype=np.float64) # array将数组转为numpy的数组 # bool,int,int8,int16,int32,int64,int128,uint8,uint32, # uint64,uint128,float16
-
python数据分析之文件读取详解
目录 前言: 一·Numpy库中操作文件 二·Pandas库中操作文件 三·补充 总结 前言: 如果你使用的是Anaconda中的Jupyter,则不需要下载Pands和Numpy库:如果你使用的是pycharm或其他集成环境,则需要Pands和Numpy库 一·Numpy库中操作文件 1.操作csv文件 import numpy as np a=np.random.randint(0,10,size=(3,4)) np.savetext("score.csv",a,deliminte
-

Python数据分析之Matplotlib的常用操作总结
目录 使用准备 1.简单的绘制图像 2.视图面板的常用操作 3.样式及各类常用修饰属性 4.legend图例的使用 5.添加文字等描述 6.不同类型图像的绘制 总结 使用准备 使用matplotlib需引入: import matplotlib.pyplot as plt 通常2会配合着numpy使用,numpy引入: import numpy as np 1.简单的绘制图像 def matplotlib_draw(): # 从-1到1生成100个点,包括最后一个点,默认为不包括最后一个点 x
-
深入浅析Python数据分析的过程记录
目录 一.需求介绍 二.以第1.个为例进行数据分析 1.获取一天的数据 2.开始一天的数据的分析 3.循环日期进行多天的数据分析: 4.将数据写入Excel表格中 三.完整的代码展示: 总结 一.需求介绍 该需求主要是分析某一种数据的历史数据. 客户的需求是根据该数据的前两期的情况,如果存在某个斜着的两个数字相等,那么就买第三期的同一个位置处的彩票,对于1.,如果相等的数字是:1-5,那就买6-10,如果相等的数字是:6-10,那就买1-5:对于2.,如果相等的数字是:1-5,那就买1-5,如果
-
Python接单的过程记录分享
一.需求介绍 该需求主要是分析彩票的历史数据,彩票的名称为: 1.极速飞艇 链接:https://www.dsn665.com/view/jisuft/pk10kai_history.html 2.极速赛车 链接:https://www.dsn665.com/view/jisusaiche/pk10kai.html 客户的需求是根据彩票的前两期的情况,如果存在某个斜着的两个数字相等,那么就买第三期的同一个位置处的彩票, 对于1.,如果相等的数字是:1-5,那就买6-10,如果相等的数字是:6-1
-
浅析Windows 嵌入python解释器的过程
这次主要记录在windows下嵌入 python 解释器的过程,程序没有多少,主要是头文件与库文件的提取. 程序平台:windows10 64 bit. Qt 5.5.1 MSVC 2013 32 bit . python 3.7.4 32 bit 在ubuntu和 windows 下使用 C/C++ 嵌入 Python 是有些不同的, ubuntu 下可以使用对应命令来获取 python 配置信息, windows 下直接链接对应库文件与头文件即可. 通过对python解释器的嵌入,
-
深入浅析python中的多进程、多线程、协程
进程与线程的历史 我们都知道计算机是由硬件和软件组成的.硬件中的CPU是计算机的核心,它承担计算机的所有任务. 操作系统是运行在硬件之上的软件,是计算机的管理者,它负责资源的管理和分配.任务的调度. 程序是运行在系统上的具有某种功能的软件,比如说浏览器,音乐播放器等. 每次执行程序的时候,都会完成一定的功能,比如说浏览器帮我们打开网页,为了保证其独立性,就需要一个专门的管理和控制执行程序的数据结构--进程控制块. 进程就是一个程序在一个数据集上的一次动态执行过程. 进程一般由程序.数据集.进程控
-
详解Python数据分析--Pandas知识点
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘 1. 重复值的处理 利用drop_duplicates()函数删除数据表中重复多余的记录, 比如删除重复多余的ID. import pandas as pd df = pd.DataFrame({"ID": ["A1000","A1001","A1002", "A1002"], "departmentId":
-
浅析python 通⽤爬⾍和聚焦爬⾍
一.爬虫的简单理解 1. 什么是爬虫? 网络爬虫也叫网络蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去的蜘蛛,爬虫程序通过请求url地址,根据响应的内容进行解析采集数据, 比如:如果响应内容是html,分析dom结构,进行dom解析.或者正则匹配,如果响应内容是xml/json数据,就可以转数据对象,然后对数据进行解析. 2. 爬虫有什么作用? 通过有效的爬虫手段批量采集数据,可以降低人工成本,提高有效数据量,给予运营/销售的数据支撑,加快产品发展. 3. 爬虫业界的情况 目前互
-
Python数据分析之彩票的历史数据
一.需求介绍 该需求主要是分析彩票的历史数据 客户的需求是根据彩票的前两期的情况,如果存在某个斜着的两个数字相等,那么就买第三期的同一个位置处的彩票 对于1.,如果相等的数字是:1-5,那就买6-10,如果相等的数字是:6-10,那就买1-5: 对于2.,如果相等的数字是:1-5,那就买1-5,如果相等的数字是:6-10,,那就买6-10. 然后,根据这个方案,有可能会买中,但是也有可能买不中,于是,客户希望我可以统计出来在100天中,按照这种方法,连续6次以及6次以上的购买彩票才能够命中一次奖
-
Python数据分析之使用scikit-learn构建模型
一.使用sklearn转换器处理 sklearn提供了model_selection模型选择模块.preprocessing数据预处理模块.decompisition特征分解模块,通过这三个模块能够实现数据的预处理和模型构建前的数据标准化.二值化.数据集的分割.交叉验证和PCA降维处理等工作. 1.加载datasets中的数据集 sklearn库的datasets模块集成了部分数据分析的经典数据集,可以选用进行数据预处理.建模的操作. 常见的数据集加载函数(器): 数据集加载函数(器) 数据集任
-
浅析Python语言自带的数据结构有哪些
Python作为一种脚本语言,其要求强制缩进,使其易读.美观,它的数据类型可以实现自动转换,而不需要像C.Java那样给变量定义数据类型,使其编写非常方便简单,所以广受大家的欢迎. 现如今,Python已经广泛的应用于数据分析.数据挖掘.机器学习等众多科学计算领域.所以既然涉及到科学计算,深入了解Python原生提供的数据结构是很有必要的,这样才能在数据的海洋中游刃有余.得心应手.本文便以此展开,做一个归纳整理,方便收藏. Python 一.序列结构 首先介绍的数据结构是序列结构,所谓序列,也就
-
Python连接字符串过程详解
这篇文章主要介绍了python连接字符串过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在python中,如果有多个字符串,想要连接在一起,或者说想要拼接在一起该如何操作,在此记录下. 1.通过 + 这个加号操作符,将字符串拼接在一起 >>> "First" + "Python" + "Lesson" 'FirstPythonLesson' >>> &