详解R语言中生存分析模型与时间依赖性ROC曲线可视化
R语言简介
R是用于统计分析、绘图的语言和操作环境。R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
人们通常使用接收者操作特征曲线(ROC)进行二元结果逻辑回归。但是,流行病学研究中感兴趣的结果通常是事件发生时间。使用随时间变化的时间依赖性ROC可以更全面地描述这种情况下的预测模型。
时间依赖性ROC定义
令 Mi为用于死亡率预测的基线(时间0)标量标记。 当随时间推移观察到结果时,其预测性能取决于评估时间 t。直观地说,在零时间测量的标记值应该变得不那么相关。因此,ROC测得的预测性能(区分)是时间t的函数 。
累积病例
累积病例/动态ROC定义了在时间t 处的阈值c处的 灵敏度和特异性, 如下所示。
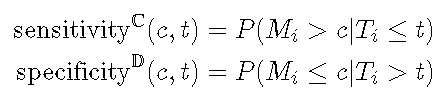
累积灵敏度将在时间t之前死亡的视为分母(疾病),而将标记值高于 c 的作为真实阳性(疾病阳性)。动态特异性将在时间t仍然活着作为分母(健康),并将标记值小于或等于 c 的那些作为真实阴性(健康中的阴性)。将阈值 c 从最小值更改为最大值会在时间t处显示整个ROC曲线 。
新发病例
新发病例ROC1在时间t 处以阈值 c定义灵敏度和特异性, 如下所示。

累积灵敏度将在时间t处死亡的人 视为分母(疾病),而将标记值高于 Ç 的人视为真实阳性(疾病阳性)。
数据准备
我们以数据 包中的dataset3survival为例。事件发生的时间就是死亡的时间。Kaplan-Meier图如下。
## 变成data_frame
data <- as_data_frame(data)
## 绘图
plot(survfit(Surv(futime, fustat) ~ 1,
data = data)
可视化结果:
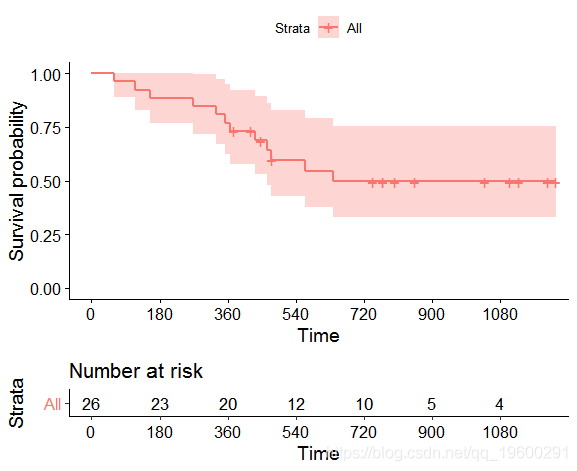
在数据集中超过720天没有发生任何事件。
## 拟合cox模型 coxph(formula = Surv(futime, fustat) ~ pspline(age, df = 4) + ##获得线性预测值 predict(coxph1, type = "lp")
累积病例
实现了累积病例
## 定义一个辅助函数,以在不同的时间进行评估
ROC_hlp <- function(t) {
survivalROC(Stime
status
marker
predict.time = t,
method = "NNE",
span = 0.25 * nrow(ovarian)^(-0.20))
}
## 每180天评估一次
ROC_data <- data_frame(t = 180 * c(1,2,3,4,5,6)) %>%
mutate(survivalROC = map(t, survivalROC_helper),
## 提取AUC
auc = map_dbl(survivalROC, magrittr::extract2, "AUC"),
## 在data_frame中放相关的值
df_survivalROC = map(survivalROC, function(obj) {
## 绘图
ggplot(mapping = aes(x = FP, y = TP)) +
geom_point() +
geom_line() +
facet_wrap( ~ t) +
可视化结果:
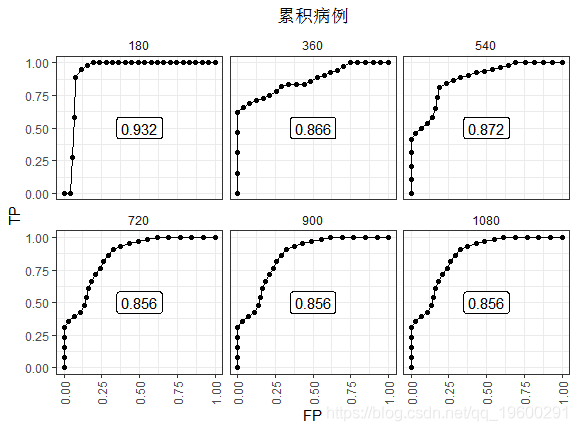
180天的ROC看起来是最好的。因为到此刻为止几乎没有事件。在最后观察到的事件(t≥720)之后,AUC稳定在0.856。这种表现并没有衰退,因为高风险分数的人死了。
新发病例
实现新发病例
## 定义一个辅助函数,以在不同的时间进行评估
## 每180天评估一次
## 提取AUC
auc = map_dbl(risksetROC, magrittr::extract2, "AUC"),
## 在data_frame中放相关的值
df_risksetROC = map(risksetROC, function(obj) {
## 标记栏
marker <- c(-Inf, obj[["marker"]], Inf)
## 绘图
ggplot(mapping = aes(x = FP, y = TP)) +
geom_point() +
geom_line() +
geom_label(data = risksetROC_data %>% dplyr::select(t,auc) %>% unique,
facet_wrap( ~ t) +
可视化结果:
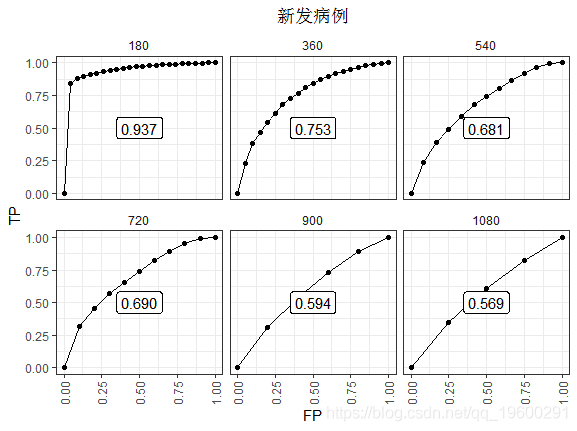
这种差异在后期更为明显。最值得注意的是,只有在每个时间点处于风险集中的个体才能提供数据。所以数据点少了。表现的衰退更为明显,也许是因为在那些存活时间足够长的人中,时间零点的风险分没有那么重要。一旦没有事件,ROC基本上就会趋于平缓。
结论
总之,我们研究了时间依赖的ROC及其R实现。累积病例ROC可能与风险 (累积发生率)预测模型的概念更兼容 。新发病例ROC可用于检查时间零标记在预测后续事件时的相关性。
参考
Heagerty,Patrick J. and Zheng,Yingye, Survival Model Predictive Accuracy and ROC Curves,Biometrics,61(1),92-105(2005). doi:10.1111 / j.0006-341X.2005.030814.x.
到此这篇关于详解R语言中生存分析模型与时间依赖性ROC曲线可视化的文章就介绍到这了,更多相关R语言生存分析曲线可视化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

简述:我为什么选择Python而不是Matlab和R语言
做数据分析.科学计算等离不开工具.语言的使用,目前最流行的数据语言,无非是MATLAB,R语言,Python这三种语言,但今天小编简单总结了python语言的一些特点及平常使用的工具等. 为什么Python比MATLAB.R语言好呢? 其实,这三种语言都很多数据分析师在用,但更推荐python,主要是有以下几点: 1.python易学.易读.易维护,处理速度也比R语言要快,无需把数据库切割: 2.python势头猛,众多大公司需要,市场前景广阔:而MATLAB语言比较局限,专注于工程和科学计算方
-
R语言 vs Python对比:数据分析哪家强?
什么是R语言? R语言,一种自由软件编程语言与操作环境,主要用于统计分析.绘图.数据挖掘.R本来是由来自新西兰奥克兰大学的罗斯·伊哈卡和罗伯特·杰特曼开发(也因此称为R),现在由"R开发核心团队"负责开发.R基于S语言的一个GNU计划项目,所以也可以当作S语言的一种实现,通常用S语言编写的代码都可以不作修改的在R环境下运行.R的语法是来自Scheme. R的源代码可自由下载使用,亦有已编译的可执行文件版本可以下载,可在多种平台下运行,包括UNIX(也包括FreeBSD和Linux).W
-
Python与R语言的简要对比
数据挖掘技术日趋成熟和复杂,随着互联网发展以及大批海量数据的到来,之前传统的依靠spss.SAS等可视化工具实现数据挖掘建模已经越来越不能满足日常需求,依据美国对数据科学家(data scientist)的要求,想成为一名真正的数据科学家,编程实现算法以及编程实现建模已经是必要条件:目前很多从事数据挖掘工作的人,大多都是出身非计算机专业,本身对编程基础比较低,所以找到一门快速上手而又高效的编程语言是至关重要的,好的工具和编程语言可以起到事半功倍的效果. 目前在数据挖掘算法方面用的最多的编程语言有
-
R语言利用loess如何去除某个变量对数据的影响详解
R语言介绍 R语言是用于统计分析,图形表示和报告的编程语言和软件环境. R语言由Ross Ihaka和Robert Gentleman在新西兰奥克兰大学创建,目前由R语言开发核心团队开发. R语言的核心是解释计算机语言,其允许分支和循环以及使用函数的模块化编程. R语言允许与以C,C ++,.Net,Python或FORTRAN语言编写的过程集成以提高效率. R语言在GNU通用公共许可证下免费提供,并为各种操作系统(如Linux,Windows和Mac)提供预编译的二进制版本. R是一个在GNU
-
详解R语言中生存分析模型与时间依赖性ROC曲线可视化
R语言简介 R是用于统计分析.绘图的语言和操作环境.R是属于GNU系统的一个自由.免费.源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具. 人们通常使用接收者操作特征曲线(ROC)进行二元结果逻辑回归.但是,流行病学研究中感兴趣的结果通常是事件发生时间.使用随时间变化的时间依赖性ROC可以更全面地描述这种情况下的预测模型. 时间依赖性ROC定义 令 Mi为用于死亡率预测的基线(时间0)标量标记. 当随时间推移观察到结果时,其预测性能取决于评估时间 t.直观地说,在零时间测量的标记值应该
-
详解R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
在标准线性模型中,我们假设 .当线性假设无法满足时,可以考虑使用其他方法. 多项式回归 扩展可能是假设某些多项式函数, 同样,在标准线性模型方法(使用GLM的条件正态分布)中,参数 可以使用最小二乘法获得,其中 在 . 即使此多项式模型不是真正的多项式模型,也可能仍然是一个很好的近似值 .实际上,根据 Stone-Weierstrass定理,如果 在某个区间上是连续的,则有一个统一的近似值 ,通过多项式函数. 仅作说明,请考虑以下数据集 db = data.frame(x=xr,y=y
-
详解R语言中的表达式、数学公式、特殊符号
在R语言的绘图函数中,如果文本参数是合法的R语言表达式,那么这个表达式就被用Tex类似的规则进行文本格式化. y <- function(x) (exp(-(x^2)/2))/sqrt(2*pi) plot(y, -5, 5, main = expression(f(x) == frac(1,sqrt(2*pi))*e^(-frac(x^2,2))), lwd = 3, col = "blue") library(ggplot2) x <- seq(0, 2*pi, b
-
详解R语言数据合并一行代码搞定
数据的合并 需要的函数 cbind(),rbind(),bind_rows(),merge() 准备数据 我们先构造一组数据,以便下面的演示 > data1<-data.frame( + namea=c("海波","立波","秀波"), + value=c("一波","接","一波") + ) > data1 namea value 1 海波 一波 2 立波 接 3 秀
-
详解R语言实现前向逐步回归(前向选择模型)
目录 前向逐步回归原理 数据导入并分组 导入数据 特征与标签分开存放 前向逐步回归构建输出特征集合 从空开始一次创建属性列表 模型效果评估 前向逐步回归原理 前向逐步回归的过程是:遍历属性的一列子集,选择使模型效果最好的那一列属性.接着寻找与其组合效果最好的第二列属性,而不是遍历所有的两列子集.以此类推,每次遍历时,子集都包含上一次遍历得到的最优子集.这样,每次遍历都会选择一个新的属性添加到特征集合中,直至特征集合中特征个数不能再增加. 数据导入并分组 导入数据,将数据集抽取70%作为训练集,剩
-
详解C语言中二分查找的运用技巧
目录 基础的二分查 查找左侧边界 查找右侧边界 二分查找问题分析 实例1: 爱吃香蕉的珂珂 实例2:运送包裹 前篇文章聊到了二分查找的基础以及细节的处理问题,主要介绍了 查找和目标值相等的元素.查找第一个和目标值相等的元素.查找最后一个和目标值相等的元素 三种情况. 这些情况都适用于有序数组中查找指定元素 这个基本的场景,但实际应用中可能不会这么直接,甚至看了题目之后,都不会想到可以用二分查找算法来解决 . 本文就来分析下二分查找在实际中的应用,通过分析几个应用二分查找的实例,总结下能使用二分查
-
详解Go语言中泛型的实现原理与使用
目录 前言 问题 解决方法 类型约束 重获类型安全 泛型使用场景 性能 虚拟方法表 单态化 Go 的实现 结论 前言 原文:A gentle introduction to generics in Go byDominik Braun 万俊峰Kevin:我看了觉得文章非常简单易懂,就征求了作者同意,翻译出来给大家分享一下. 本文是对泛型的基本思想及其在 Go 中的实现的一个比较容易理解的介绍,同时也是对围绕泛型的各种性能讨论的简单总结.首先,我们来看看泛型所解决的核心问题. 问题 假设我们想实现
-
一文详解C语言中文件相关函数的使用
目录 一.文件和流 1.程序文件 2.数据文件 3.流 二.文件组成 三.文件的打开和关闭 1.文件的打开fopen 2.文件关闭fclose 四.文件的顺序读写 1.使用fputc和fgetc写入/读取单个字符 2.使用fputs和fgets写入/读取一串字符 3.使用fprintf和fscanf按照指定的格式写入/读取 4.使用fwrite和fread按照二进制的方式写入/读取 5.使用sprintf和sscanf将格式化数据和字符串互相转换(文件无关) 五.文件的随机读写 1.fseek(
-
详解Go语言中关于包导入必学的 8 个知识点
1. 单行导入与多行导入 在 Go 语言中,一个包可包含多个 .go 文件(这些文件必须得在同一级文件夹中),只要这些 .go 文件的头部都使用 package 关键字声明了同一个包. 导入包主要可分为两种方式: 单行导入 import "fmt" import "sync" 多行导入 import( "fmt" "sync" ) 如你所见,Go 语言中 导入的包,必须得用双引号包含,在这里吐槽一下. 2. 使用别名 在一些场
-
详解C语言中不同类型的数据转换规则
不同类型数据间的混合运算与类型转换 1.自动类型转换 在C语言中,自动类型转换遵循以下规则: ①若参与运算量的类型不同,则先转换成同一类型,然后进行运算 ②转换按数据长度增加的方向进行,以保证精度不降低.如int型和long型运算时,先把int量转成long型后再进行运算 a.若两种类型的字节数不同,转换成字节数高的类型 b.若两种类型的字节数相同,且一种有符号,一种无符号,则转换成无符号类型 ③所有的浮点运算都是以双精度进行的,即使是两个float单精度量运算的表达式,也要先转换成double