Python机器学习pytorch模型选择及欠拟合和过拟合详解
目录
- 训练误差和泛化误差
- 模型复杂性
- 模型选择
- 验证集
- K折交叉验证
- 欠拟合还是过拟合?
- 模型复杂性
- 数据集大小
训练误差和泛化误差
训练误差是指,我们的模型在训练数据集上计算得到的误差。
泛化误差是指,我们将模型应用在同样从原始样本的分布中抽取的无限多的数据样本时,我们模型误差的期望。
在实际中,我们只能通过将模型应用于一个独立的测试集来估计泛化误差,该测试集由随机选取的、未曾在训练集中出现的数据样本构成。
模型复杂性
在本节中将重点介绍几个倾向于影响模型泛化的因素:
可调整参数的数量。当可调整参数的数量(有时称为自由度)很大时,模型往往更容易过拟合。参数采用的值。当权重的取值范围较大时,模型可能更容易过拟合。训练样本的数量。即使模型非常简单,也很容易过拟合只包含一两个样本的数据集。而过拟合一个有数百万个样本的数据集则需要一个极其灵活的模型。
模型选择
在机器学习中,我们通常在评估几个候选模型后选择最终的模型。这个过程叫做模型的选择。有时,需要进行比较的模型在本质上是完全不同的(比如,决策树与线性模型)。又有时,我们需要比较不同的超参数设置下的同一类模型。
例如,训练多层感知机模型时,我们可能希望比较具有不同数量的隐藏层、不同数量的隐藏单元以及不同的激活函数组合的模型。为了确定候选模型的最佳模型,我们通常会使用验证集。
验证集
原则上,在我们确定所有的超参数之前,我们不应该用到测试集。如果我们在模型选择过程中使用了测试数据,可能会有过拟合测试数据的风险。
如果我们过拟合了训练数据,还有在测试数据上的评估来判断过拟合。
但是如果我们过拟合了测试数据,我们又应该怎么知道呢?
我们不能依靠测试数据进行模型选择。也不能仅仅依靠训练数据来选择模型,因为我们无法估计训练数据的泛化误差。
解决此问题的常见做法是将我们的数据分成三份,除了训练和测试数据集之外,还增加一个验证数据集(validation dataset),也叫验证集(validation set)。
但现实是,验证数据和测试数据之间的界限非常模糊。在之后实际上是使用应该被正确地称为训练数据和验证数据的东西,并没有真正的测试数据集。因此,之后的准确度都是验证集准确度,而不是测试集准确度。
K折交叉验证
当训练数据稀缺时,我们甚至可能无法提供足够的数据来构成一个合适的验证集。这个问题的一个流行的解决方案是采用 K K K折交叉验证。这里,原始训练数据被分成 K个不重叠的子集。然后执行K次模型训练和验证,每次在K−1个子集上进行训练,并在剩余的一个子集(在该轮中没有用于训练的子集)上进行验证。最后,通过K次实验的结果取平均来估计训练和验证误差。
欠拟合还是过拟合?
当我们比较训练和验证误差时,我们要注意两种常见的情况。
首先,我们要注意这样的情况:训练误差和验证误差都很严重,但它们之间仅有一点差距。如果模型不能降低训练误差,这可能意味着我们的模型过于简单(即表达能力不足),无法捕获我们试图学习的模式。此外,由于我们的训练和验证误差之间的泛化误差很小,我们有理由相信可以用一个更复杂的模型降低训练误差。这种现象被称为欠拟合。
另一方面,当我们的训练误差明显低于验证误差时要小心,这表明严重的过拟合。注意,过拟合并不总是一件坏事。
我们是否过拟合或欠拟合可能取决于模型的复杂性和可用数据集的大小,这两个点将在下面进行讨论。
模型复杂性

告诫多项式函数比低阶多项式函数复杂得多。高阶多项式的参数较多,模型函数的选择范围较广。因此在固定训练数据集的情况下,高阶多项式函数相对于低阶多项式的训练误差应该始终更低(最坏也是相等)。事实上,当数据样本包含了 x的不同取值时,函数阶数等于数据样本数量的多项式函数可以完美拟合训练集。在下图中,我们直观地描述了多项式的阶数和欠拟合与过拟合之间的关系。
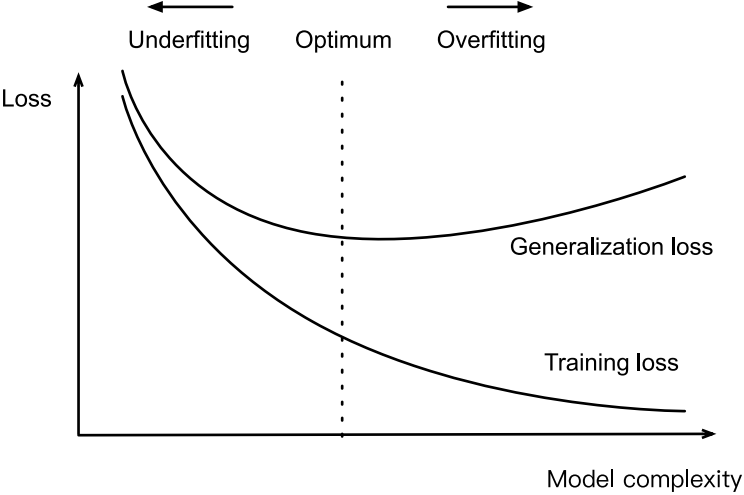
数据集大小
训练数据集中的样本越少,我们就越可能(且更严重地)遇到过拟合。随着训练数据量的增加,泛化误差通常会减小。此外,一般来说,更多的数据不会有什么坏处。
以上就是Python机器学习pytorch模型选择及欠拟合和过拟合详解的详细内容,更多关于pytorch模型选择及欠拟合和过拟合的资料请关注我们其它相关文章!
相关推荐
-
解决Pytorch 加载训练好的模型 遇到的error问题
这是一个非常愚蠢的错误 debug的时候要好好看error信息 提醒自己切记好好对待error!切记!切记! -----------------------分割线---------------- pytorch 已经非常友好了 保存模型和加载模型都只需要一条简单的命令 #保存整个网络和参数 torch.save(your_net, 'save_name.pkl') #加载保存的模型 net = torch.load('save_name.pkl') 因为我比较懒我就想直接把整个网络都保存下来,然
-
keras处理欠拟合和过拟合的实例讲解
baseline import tensorflow.keras.layers as layers baseline_model = keras.Sequential( [ layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)), layers.Dense(16, activation='relu'), layers.Dense(1, activation='sigmoid') ] ) baseline_model.compil
-

Pytorch之如何dropout避免过拟合
一.做数据 二.搭建神经网络 三.训练 四.对比测试结果 注意:测试过程中,一定要注意模式切换 Pytorch的学习--过拟合 过拟合 过拟合是当数据量较小时或者输出结果过于依赖某些特定的神经元,训练神经网络训练会发生一种现象.出现这种现象的神经网络预测的结果并不具有普遍意义,其预测结果极不准确. 解决方法 1.增加数据量 2.L1,L2,L3-正规化,即在计算误差值的时候加上要学习的参数值,当参数改变过大时,误差也会变大,通过这种惩罚机制来控制过拟合现象 3.dropout正规化,在训练过程中
-
pytorch构建网络模型的4种方法
利用pytorch来构建网络模型有很多种方法,以下简单列出其中的四种. 假设构建一个网络模型如下: 卷积层-->Relu层-->池化层-->全连接层-->Relu层-->全连接层 首先导入几种方法用到的包: import torch import torch.nn.functional as F from collections import OrderedDict 第一种方法 # Method 1 --------------------------------------
-
Python机器学习pytorch模型选择及欠拟合和过拟合详解
目录 训练误差和泛化误差 模型复杂性 模型选择 验证集 K折交叉验证 欠拟合还是过拟合? 模型复杂性 数据集大小 训练误差和泛化误差 训练误差是指,我们的模型在训练数据集上计算得到的误差. 泛化误差是指,我们将模型应用在同样从原始样本的分布中抽取的无限多的数据样本时,我们模型误差的期望. 在实际中,我们只能通过将模型应用于一个独立的测试集来估计泛化误差,该测试集由随机选取的.未曾在训练集中出现的数据样本构成. 模型复杂性 在本节中将重点介绍几个倾向于影响模型泛化的因素: 可调整参数的数量.当可调
-
Python机器学习应用之基于BP神经网络的预测篇详解
目录 一.Introduction 1 BP神经网络的优点 2 BP神经网络的缺点 二.实现过程 1 Demo 2 基于BP神经网络的乳腺癌分类预测 三.Keys 一.Introduction 1 BP神经网络的优点 非线性映射能力:BP神经网络实质上实现了一个从输入到输出的映射功能,数学理论证明三层的神经网络就能够以任意精度逼近任何非线性连续函数.这使得其特别适合于求解内部机制复杂的问题,即BP神经网络具有较强的非线性映射能力. 自学习和自适应能力:BP神经网络在训练时,能够通过学习自动提取输
-
Python机器学习算法库scikit-learn学习之决策树实现方法详解
本文实例讲述了Python机器学习算法库scikit-learn学习之决策树实现方法.分享给大家供大家参考,具体如下: 决策树 决策树(DTs)是一种用于分类和回归的非参数监督学习方法.目标是创建一个模型,通过从数据特性中推导出简单的决策规则来预测目标变量的值. 例如,在下面的例子中,决策树通过一组if-then-else决策规则从数据中学习到近似正弦曲线的情况.树越深,决策规则越复杂,模型也越合适. 决策树的一些优势是: 便于说明和理解,树可以可视化表达: 需要很少的数据准备.其他技术通常需要
-
Python机器学习入门(四)选择模型
目录 1.数据分离与验证 1.1分离训练数据集和评估数据集 1.2K折交叉验证分离 1.3弃一交叉验证分离 1.4重复随机分离评估数据集与训练数据集 2.算法评估 2.1分类算法评估 2.1.1分类准确度 2.1.2分类报告 2.2回归算法评估 2.2.1平均绝对误差 2.2.2均方误差 2.2.3判定系数() 总结 1.数据分离与验证 要知道算法模型对未知的数据表现如何,最好的评估办法是利用已经明确知道结果的数据运行生成的算法模型进行验证.此外还可以使用新的数据来评估算法模型. 在评估机器学习
-
python机器学习pytorch自定义数据加载器
目录 正文 1. 加载数据集 2. 迭代和可视化数据集 3.创建自定义数据集 3.1 __init__ 3.2 __len__ 3.3 __getitem__ 4. 使用 DataLoaders 为训练准备数据 5.遍历 DataLoader 正文 处理数据样本的代码可能会逐渐变得混乱且难以维护:理想情况下,我们希望我们的数据集代码与我们的模型训练代码分离,以获得更好的可读性和模块化.PyTorch 提供了两个数据原语:torch.utils.data.DataLoader和torch.util
-
python机器学习pytorch 张量基础教程
目录 正文 1.初始化张量 1.1 直接从列表数据初始化 1.2 用 NumPy 数组初始化 1.3 从另一个张量初始化 1.4 使用随机值或常量值初始化 2.张量的属性 3.张量运算 3.1 标准的类似 numpy 的索引和切片: 3.2 连接张量 3.3 算术运算 3.4单元素张量 Single-element tensors 3.5 In-place 操作 4. 张量和NumPy 桥接 4.1 张量到 NumPy 数组 4.2 NumPy 数组到张量 正文 张量是一种特殊的数据结构,与数组
-
对python实现二维函数高次拟合的示例详解
在参加"数据挖掘"比赛中遇到了关于函数高次拟合的问题,然后就整理了一下源码,以便后期的学习与改进. 在本次"数据挖掘"比赛中感觉收获最大的还是对于神经网络的认识,在接近一周的时间里,研究了进40种神经网络模型,虽然在持续一周的挖掘比赛把自己折磨的惨不忍睹,但是收获颇丰.现在想想也挺欣慰自己在这段时间里接受新知识的能力.关于神经网络方面的理解会在后续博文中补充(刚提交完论文,还没来得及整理),先分享一下高次拟合方面的知识. # coding=utf-8 import
-
PyTorch: 梯度下降及反向传播的实例详解
线性模型 线性模型介绍 线性模型是很常见的机器学习模型,通常通过线性的公式来拟合训练数据集.训练集包括(x,y),x为特征,y为目标.如下图: 将真实值和预测值用于构建损失函数,训练的目标是最小化这个函数,从而更新w.当损失函数达到最小时(理想上,实际情况可能会陷入局部最优),此时的模型为最优模型,线性模型常见的的损失函数: 线性模型例子 下面通过一个例子可以观察不同权重(w)对模型损失函数的影响. #author:yuquanle #data:2018.2.5 #Study of Linear
-
python 安装库几种方法之cmd,anaconda,pycharm详解
python安装库的几种方法 在python项目开发的过程中,需要安装大大小小的库,本文会提供几种安装库的方法,总有一种可以帮到大家. 安装的方法主要有三种: ①利用命令框安装库. ②利用pycharm的环境配置界面安装库. ③利用anaconda直接安装库(几乎无所不能). ①利用命令框安装python库 首先进命令行界面(cmd),利用conda指令打开演示用的anaconda环境(名称为tf1.13) conda activate tf1.13 如下图所示,进入名为tf1.13的环境(最前