用Python实现网易云音乐的数据进行数据清洗和可视化分析
目录
- Python实现对网易云音乐的数据进行一个数据清洗和可视化分析
- 对音乐数据进行数据清洗与可视化分析
- 对音乐数据进行数据清洗与可视化分析
- 歌词文本分析
- 总结
Python实现对网易云音乐的数据进行一个数据清洗和可视化分析
对音乐数据进行数据清洗与可视化分析
关于数据的清洗,实际上在上一一篇文章关于抓取数据的过程中已经做了一部分,后面我又做了一下用户数据的抓取
歌曲评论:


包括后台返回的空用户信息、重复数据的去重等。除此之外,还要进行一些清洗:用户年龄错误、用户城市编码转换等。
关于数据的去重,评论部分可以以sommentId为数据库索引,利用数据库来自动去重;用户信息部分以用户ID为数据库索引实现自动去重。
API返回的用户年龄一般是时间戳的形式(以毫秒计)、有时候也会返回一个负值或者一个大于当前时间的值,暂时没有找到这两种值代表的含义,故而一律按0来处理。
API返回的用户信息中,城市分为province和city两个字段,本此分析中只保存了city字段。实际上字段值是一个城市code码,具体对照在这里下载。
利用Python的数据处理库pandas进行数据处理,利用可视化库pyecharts进行数据可视化。
分别查看下面分析结果。
- 评论用户年龄分布
- 评论关键词分布
- 评论时间数量分布(年-月)
- 评论时间数量分布(年-月-日)
对音乐数据进行数据清洗与可视化分析
import pandas as pd
import pymysql
from pyecharts import Bar,Pie,Line,Scatter,Map
TABLE_COMMENTS = '****'
TABLE_USERS = '****'
DATABASE = '****'
conn = pymysql.connect(host='localhost', user='****', passwd='****', db=DATABASE, charset='utf8mb4')
sql_users = 'SELECT id,gender,age,city FROM '+TABLE_USERS
sql_comments = 'SELECT id,time FROM '+TABLE_COMMENTS
comments = pd.read_sql(sql_comments, con=conn)
users = pd.read_sql(sql_users, con=conn)
# 评论时间(按天)分布分析
comments_day = comments['time'].dt.date
data = comments_day.id.groupby(comments_day['time']).count()
line = Line('评论时间(按天)分布')
line.use_theme('dark')
line.add(
'',
data.index.values,
data.values,
is_fill=True,
)
line.render(r'./评论时间(按天)分布.html')
# 评论时间(按小时)分布分析
comments_hour = comments['time'].dt.hour
data = comments_hour.id.groupby(comments_hour['time']).count()
line = Line('评论时间(按小时)分布')
line.use_theme('dark')
line.add(
'',
data.index.values,
data.values,
is_fill=True,
)
line.render(r'./评论时间(按小时)分布.html')
# 评论时间(按周)分布分析
comments_week = comments['time'].dt.dayofweek
data = comments_week.id.groupby(comments_week['time']).count()
line = Line('评论时间(按周)分布')
line.use_theme('dark')
line.add(
'',
data.index.values,
data.values,
is_fill=True,
)
line.render(r'./评论时间(按周)分布.html')
# 用户年龄分布分析
age = users[users['age']>0] # 清洗掉年龄小于1的数据
age = age.id.groupby(age['age']).count() # 以年龄值对数据分组
Bar = Bar('用户年龄分布')
Bar.use_theme('dark')
Bar.add(
'',
age.index.values,
age.values,
is_fill=True,
)
Bar.render(r'./用户年龄分布图.html') # 生成渲染的html文件
# 用户地区分布分析
# 城市code编码转换
def city_group(cityCode):
city_map = {
'11': '北京',
'12': '天津',
'31': '上海',
'50': '重庆',
'5e': '重庆',
'81': '香港',
'82': '澳门',
'13': '河北',
'14': '山西',
'15': '内蒙古',
'21': '辽宁',
'22': '吉林',
'23': '黑龙江',
'32': '江苏',
'33': '浙江',
'34': '安徽',
'35': '福建',
'36': '江西',
'37': '山东',
'41': '河南',
'42': '湖北',
'43': '湖南',
'44': '广东',
'45': '广西',
'46': '海南',
'51': '四川',
'52': '贵州',
'53': '云南',
'54': '西藏',
'61': '陕西',
'62': '甘肃',
'63': '青海',
'64': '宁夏',
'65': '新疆',
'71': '台湾',
'10': '其他',
}
return city_map[cityCode[:2]]
city = users['city'].apply(city_group)
city = city.id.groupby(city['city']).count()
map_ = Map('用户地区分布图')
map_.add(
'',
city.index.values,
city.values,
maptype='china',
is_visualmap=True,
visual_text_color='#000',
is_label_show=True,
)
map_.render(r'./用户地区分布图.html')
可视化结果

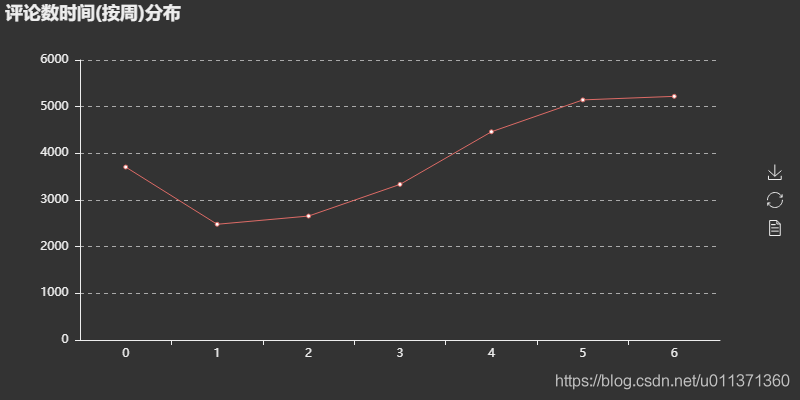
评论时间按周分布图可以看出,评论数在一周当中前面较少,后面逐渐增多,这可以解释为往后接近周末,大家有更多时间来听听歌、刷刷歌评,而一旦周末过完,评论量马上下降(周日到周一的下降过渡),大家又回归到工作当中。
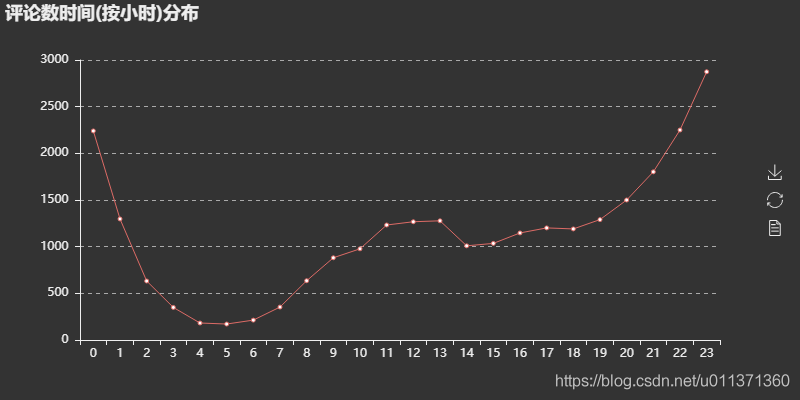
评论时间按小时分布图可以看出,评论数在一天当中有两个小高峰:11点-13点和22点-0点。这可以解释为用户在中午午饭时间和晚上下班(课)在家时间有更多的时间来听歌刷评论,符合用户的日常。至于为什么早上没有出现一个小高峰,大概是早上大家都在抢时间上班(学),没有多少时间去刷评论。

https://blog.csdn.net/u011371360
用户年龄分布图可以看出,用户大多集中在14-30岁之间,以20岁左右居多,除去虚假年龄之外,这个年龄分布也符合网易云用户的年龄段。图中可以看出28岁有个高峰,猜测可能是包含了一些异常数据,有兴趣的化可以做进一步分析。
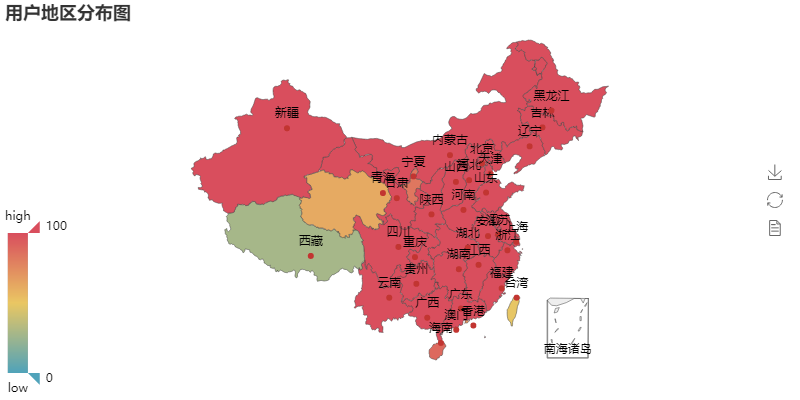
用户地区分布图可以看出,用户涵盖了全国各大省份,因为中间数据(坑)的缺失,并没有展现出哪个省份特别突出的情况。对别的歌评(完全数据)的可视化分析,可以看出明显的地区分布差异。
此次分析只是对某一首歌曲评论时间、用户年龄/地区分布进行的,实际上抓取到的信息不仅仅在于此,可以做进一步分析(比如利用评论内容进行文本内容分析等),这部分,未来会进一步分析。当然也可以根据自己情况对不同歌曲进行分析。
歌词文本分析
情感分析采用Python的文本分析库snownlp,代码如下:
import numpy as np
import pymysql
from snownlp import SnowNLP
from pyecharts import Bar
TABLE_COMMENTS = '****'
DATABASE = '****'
SONGNAME = '****'
def getText():
conn = pymysql.connect(host='localhost', user='root', passwd='root', db=DATABASE, charset='utf8')
sql = 'SELECT id,content FROM '+TABLE_COMMENTS
text = pd.read_sql(sql%(SONGNAME), con=conn)
return text
def getSemi(text):
text['content'] = text['content'].apply(lambda x:round(SnowNLP(x).sentiments, 2))
semiscore = text.id.groupby(text['content']).count()
bar = Bar('评论情感得分')
bar.use_theme('dark')
bar.add(
'',
y_axis = semiscore.values,
x_axis = semiscore.index.values,
is_fill=True,
)
bar.render(r'情感得分分析.html')
text['content'] = text['content'].apply(lambda x:1 if x>0.5 else -1)
semilabel = text.id.groupby(text['content']).count()
bar = Bar('评论情感标签')
bar.use_theme('dark')
bar.add(
'',
y_axis = semilabel.values,
x_axis = semilabel.index.values,
is_fill=True,
)
bar.render(r'情感标签分析.html')
结果:


词云生成采用jieba分词库分词,wordcloud生成词云,代码如下:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.rcParams['axes.unicode_minus'] = False
def getWordcloud(text):
text = ''.join(str(s) for s in text['content'] if s)
word_list = jieba.cut(text, cut_all=False)
stopwords = [line.strip() for line in open(r'./StopWords.txt', 'r').readlines()] # 导入停用词
clean_list = [seg for seg in word_list if seg not in stopwords] #去除停用词
clean_text = ''.join(clean_list)
# 生成词云
cloud = WordCloud(
font_path = r'C:/Windows/Fonts/msyh.ttc',
background_color = 'white',
max_words = 800,
max_font_size = 64
)
word_cloud = cloud.generate(clean_text)
# 绘制词云
plt.figure(figsize=(12, 12))
plt.imshow(word_cloud)
plt.axis('off')
plt.show()
if __name__ == '__main__':
text = getText()
getSemi(text)
getWordcloud(text)
总结
本篇文章就到这里了,希望能给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-

Python爬虫实战之网易云音乐加密解析附源码
目录 环境 知识点 第一步 第二步 开始代码 先导入所需模块 请求数据 提取我们真正想要的 音乐的名称 id 导入js文件 保存文件 完整代码 环境 python3.8 pycharm2021.2 知识点 requests >>> pip install requests execjs >>> pip install PyExecJS 第一步 打开这个网站 在里面去分析我们需要的数据 每个音乐的名称 id 去网页源代码查找数据,发现并没有,这个网页 并不是一个静态页面
-
用Python实现网易云音乐的数据进行数据清洗和可视化分析
目录 Python实现对网易云音乐的数据进行一个数据清洗和可视化分析 对音乐数据进行数据清洗与可视化分析 对音乐数据进行数据清洗与可视化分析 歌词文本分析 总结 Python实现对网易云音乐的数据进行一个数据清洗和可视化分析 对音乐数据进行数据清洗与可视化分析 关于数据的清洗,实际上在上一一篇文章关于抓取数据的过程中已经做了一部分,后面我又做了一下用户数据的抓取 歌曲评论: 包括后台返回的空用户信息.重复数据的去重等.除此之外,还要进行一些清洗:用户年龄错误.用户城市编码转换等. 关于数据的去重
-
python爬取网易云音乐排行榜实例代码
目录 网易云音乐排行榜歌曲及评论爬取 一.模拟登录 二.排行榜数据爬取 三.排行榜评论获取 总结 网易云音乐排行榜歌曲及评论爬取 主要注意问题:selenium 模拟登录.iframe标签定位.页面元素提取. 在利用selenium定位元素并取值的过程中遇到问题.比如xpath正确但无法定位,在进行翻页提取评论的过程中,利用selenium似乎不能提取不同页的数据,比如,明明定位的第三页的评论数据,而只能返回第一页的评论数据. 一.模拟登录 selenium 定位元素模拟人的操作进行登录,直接上
-
Python爬取网易云音乐热门评论
最近在研究文本挖掘相关的内容,所谓巧妇难为无米之炊,要想进行文本分析,首先得到有文本吧.获取文本的方式有很多,比如从网上下载现成的文本文档,或者通过第三方提供的API进行获取数据.但是有的时候我们想要的数据并不能直接获取,因为并不提供直接的下载渠道或者API供我们获取数据.那么这个时候该怎么办呢?有一种比较好的办法是通过网络爬虫,即编写计算机程序伪装成用户去获得想要的数据.利用计算机的高效,我们可以轻松快速地获取数据. 那么该如何写一个爬虫呢?有很多种语言都可以写爬虫,比如Java,php,py
-
详解python selenium 爬取网易云音乐歌单名
目标网站: 首先获取第一页的数据,这里关键要切换到iframe里 打印一下 获取剩下的页数,这里在点击下一页之前需要设置一个延迟,不然会报错. 结果: 一共37页,爬取完毕后关闭浏览器 完整代码: url = 'https://music.163.com/#/discover/playlist/' from selenium import webdriver import time # 创建浏览器对象 window = webdriver.Chrome('./chromedriver') win
-
python爬取网易云音乐热歌榜实例代码
首先找到要下载的歌曲排行榜的链接,这里用的是: https://music.163.com/discover/toplist?id=3778678 然后更改你要保存的目录,目录要先建立好文件夹,例如我的是保存在D盘-360下载-网易云热歌榜文件夹内,就可以完成下载. 如果文件夹没有提前建好,会报错[Errno 2] No such file or directory. 代码实现: from urllib import request from bs4 import BeautifulSoup i
-
Python模拟登录网易云音乐并自动签到
一.开发工具 **Python****版本:**3.6.4 相关模块: DecryptLogin模块: argparse模块: 以及一些Python自带的模块. 二.环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.原理简介 既然要签到,首先,自然是需要模拟登录啦,这里我们还是简单地利用我们开源的DecryptLogin库来实现网易云音乐的模拟登录: '''模拟登录''' @staticmethod def login(username, password): lg
-
Python爬取网易云音乐上评论火爆的歌曲
前言 网易云音乐这款音乐APP本人比较喜欢,用户量也比较大,而网易云音乐之所以用户众多和它的歌曲评论功能密不可分,很多歌曲的评论非常有意思,其中也不乏很多感人的评论.但是,网易云音乐并没有提供热评排行榜和按评论排序的功能,没关系,本文就使用爬虫给大家爬一爬网易云音乐上那些热评的歌曲. 结果 对过程没有兴趣的童鞋直接看这里啦. 评论数大于五万的歌曲排行榜 首先恭喜一下我最喜欢的歌手(之一)周杰伦的<晴天>成为网易云音乐第一首评论数过百万的歌曲! 通过结果发现目前评论数过十万的歌曲正好十首,通过这
-
python爬取网易云音乐评论
本文实例为大家分享了python爬取网易云音乐评论的具体代码,供大家参考,具体内容如下 import requests import bs4 import json def get_hot_comments(res): comments_json = json.loads(res.text) hot_comments = comments_json['hotComments'] with open("hotcmments.txt", 'w', encoding = 'utf-8') a
-
Python3实战之爬虫抓取网易云音乐的热门评论
前言 之前刚刚入门python爬虫,有大概半个月时间没有写python了,都快遗忘了.于是准备写个简单的爬虫练练手,我觉得网易云音乐最优特色的就是其精准的歌曲推荐和独具特色的用户评论,于是写了这个抓取网易云音乐热歌榜里的热评的爬虫.我也是刚刚入门爬虫,有什么意见和问题欢迎提出,大家一起共同进步. 废话就不多说了-下面来一起看看详细的介绍吧. 我们的目标是爬取网易云中的热歌排行榜中所有歌曲的热门评论. 这样既可以减少我们需要爬取的工作量,又可以保存到高质量的评论. 实现分析 首先,我们打开网易云网