关于Tensorflow 模型持久化详解
当我们使用 tensorflow 训练神经网络的时候,模型持久化对于我们的训练有很重要的作用。
如果我们的神经网络比较复杂,训练数据比较多,那么我们的模型训练就会耗时很长,如果在训练过程中出现某些不可预计的错误,导致我们的训练意外终止,那么我们将会前功尽弃。为了避免这个问题,我们就可以通过模型持久化(保存为CKPT格式)来暂存我们训练过程中的临时数据。
如果我们训练的模型需要提供给用户做离线的预测,那么我们只需要前向传播的过程,只需得到预测值就可以了,这个时候我们就可以通过模型持久化(保存为PB格式)只保存前向传播中需要的变量并将变量的值固定下来,这个时候只需用户提供一个输入,我们就可以通过模型得到一个输出给用户。
保存为 CKPT 格式的模型
定义运算过程
声明并得到一个 Saver
通过 Saver.save 保存模型
# coding=UTF-8 支持中文编码格式
import tensorflow as tf
import shutil
import os.path
MODEL_DIR = "model/ckpt"
MODEL_NAME = "model.ckpt"
# if os.path.exists(MODEL_DIR): 删除目录
# shutil.rmtree(MODEL_DIR)
if not tf.gfile.Exists(MODEL_DIR): #创建目录
tf.gfile.MakeDirs(MODEL_DIR)
#下面的过程你可以替换成CNN、RNN等你想做的训练过程,这里只是简单的一个计算公式
input_holder = tf.placeholder(tf.float32, shape=[1], name="input_holder") #输入占位符,并指定名字,后续模型读取可能会用的
W1 = tf.Variable(tf.constant(5.0, shape=[1]), name="W1")
B1 = tf.Variable(tf.constant(1.0, shape=[1]), name="B1")
_y = (input_holder * W1) + B1
predictions = tf.greater(_y, 50, name="predictions") #输出节点名字,后续模型读取会用到,比50大返回true,否则返回false
init = tf.global_variables_initializer()
saver = tf.train.Saver() #声明saver用于保存模型
with tf.Session() as sess:
sess.run(init)
print "predictions : ", sess.run(predictions, feed_dict={input_holder: [10.0]}) #输入一个数据测试一下
saver.save(sess, os.path.join(MODEL_DIR, MODEL_NAME)) #模型保存
print("%d ops in the final graph." % len(tf.get_default_graph().as_graph_def().node)) #得到当前图有几个操作节点
for op in tf.get_default_graph().get_operations(): #打印模型节点信息
print (op.name, op.values())
运行后生成的文件如下:
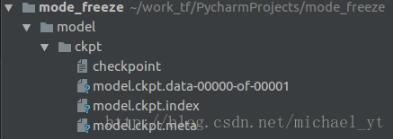
checkpoint : 记录目录下所有模型文件列表
ckpt.data : 保存模型中每个变量的取值
ckpt.meta : 保存整个计算图的结构
保存为 PB 格式模型
定义运算过程
通过 get_default_graph().as_graph_def() 得到当前图的计算节点信息
通过 graph_util.convert_variables_to_constants 将相关节点的values固定
通过 tf.gfile.GFile 进行模型持久化
# coding=UTF-8
import tensorflow as tf
import shutil
import os.path
from tensorflow.python.framework import graph_util
# MODEL_DIR = "model/pb"
# MODEL_NAME = "addmodel.pb"
# if os.path.exists(MODEL_DIR): 删除目录
# shutil.rmtree(MODEL_DIR)
#
# if not tf.gfile.Exists(MODEL_DIR): #创建目录
# tf.gfile.MakeDirs(MODEL_DIR)
output_graph = "model/pb/add_model.pb"
#下面的过程你可以替换成CNN、RNN等你想做的训练过程,这里只是简单的一个计算公式
input_holder = tf.placeholder(tf.float32, shape=[1], name="input_holder")
W1 = tf.Variable(tf.constant(5.0, shape=[1]), name="W1")
B1 = tf.Variable(tf.constant(1.0, shape=[1]), name="B1")
_y = (input_holder * W1) + B1
# predictions = tf.greater(_y, 50, name="predictions") #比50大返回true,否则返回false
predictions = tf.add(_y, 10,name="predictions") #做一个加法运算
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print "predictions : ", sess.run(predictions, feed_dict={input_holder: [10.0]})
graph_def = tf.get_default_graph().as_graph_def() #得到当前的图的 GraphDef 部分,通过这个部分就可以完成重输入层到输出层的计算过程
output_graph_def = graph_util.convert_variables_to_constants( # 模型持久化,将变量值固定
sess,
graph_def,
["predictions"] #需要保存节点的名字
)
with tf.gfile.GFile(output_graph, "wb") as f: # 保存模型
f.write(output_graph_def.SerializeToString()) # 序列化输出
print("%d ops in the final graph." % len(output_graph_def.node))
print (predictions)
# for op in tf.get_default_graph().get_operations(): 打印模型节点信息
# print (op.name)
*GraphDef:这个属性记录了tensorflow计算图上节点的信息。
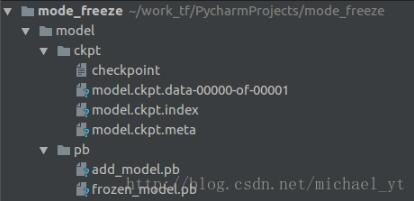
add_model.pb : 里面保存了重输入层到输出层这个计算过程的计算图和相关变量的值,我们得到这个模型后传入一个输入,既可以得到一个预估的输出值
CKPT 转换成 PB格式
通过传入 CKPT 模型的路径得到模型的图和变量数据
通过 import_meta_graph 导入模型中的图
通过 saver.restore 从模型中恢复图中各个变量的数据
通过 graph_util.convert_variables_to_constants 将模型持久化
# coding=UTF-8
import tensorflow as tf
import os.path
import argparse
from tensorflow.python.framework import graph_util
MODEL_DIR = "model/pb"
MODEL_NAME = "frozen_model.pb"
if not tf.gfile.Exists(MODEL_DIR): #创建目录
tf.gfile.MakeDirs(MODEL_DIR)
def freeze_graph(model_folder):
checkpoint = tf.train.get_checkpoint_state(model_folder) #检查目录下ckpt文件状态是否可用
input_checkpoint = checkpoint.model_checkpoint_path #得ckpt文件路径
output_graph = os.path.join(MODEL_DIR, MODEL_NAME) #PB模型保存路径
output_node_names = "predictions" #原模型输出操作节点的名字
saver = tf.train.import_meta_graph(input_checkpoint + '.meta', clear_devices=True) #得到图、clear_devices :Whether or not to clear the device field for an `Operation` or `Tensor` during import.
graph = tf.get_default_graph() #获得默认的图
input_graph_def = graph.as_graph_def() #返回一个序列化的图代表当前的图
with tf.Session() as sess:
saver.restore(sess, input_checkpoint) #恢复图并得到数据
print "predictions : ", sess.run("predictions:0", feed_dict={"input_holder:0": [10.0]}) # 测试读出来的模型是否正确,注意这里传入的是输出 和输入 节点的 tensor的名字,不是操作节点的名字
output_graph_def = graph_util.convert_variables_to_constants( #模型持久化,将变量值固定
sess,
input_graph_def,
output_node_names.split(",") #如果有多个输出节点,以逗号隔开
)
with tf.gfile.GFile(output_graph, "wb") as f: #保存模型
f.write(output_graph_def.SerializeToString()) #序列化输出
print("%d ops in the final graph." % len(output_graph_def.node)) #得到当前图有几个操作节点
for op in graph.get_operations():
print(op.name, op.values())
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("model_folder", type=str, help="input ckpt model dir") #命令行解析,help是提示符,type是输入的类型,
# 这里运行程序时需要带上模型ckpt的路径,不然会报 error: too few arguments
aggs = parser.parse_args()
freeze_graph(aggs.model_folder)
# freeze_graph("model/ckpt") #模型目录
以上这篇关于Tensorflow 模型持久化详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Tensorflow训练模型越来越慢的2种解决方案
1 解决方案 [方案一] 载入模型结构放在全局,即tensorflow会话外层. '''载入模型结构:最关键的一步''' saver = tf.train.Saver() '''建立会话''' with tf.Session() as sess: for i in range(STEPS): '''开始训练''' _, loss_1, acc, summary = sess.run([train_op_1, train_loss, train_acc, summary_op], feed_dic
-
tensorflow2.0保存和恢复模型3种方法
方法1:只保存模型的权重和偏置 这种方法不会保存整个网络的结构,只是保存模型的权重和偏置,所以在后期恢复模型之前,必须手动创建和之前模型一模一样的模型,以保证权重和偏置的维度和保存之前的相同. tf.keras.model类中的save_weights方法和load_weights方法,参数解释我就直接搬运官网的内容了. save_weights( filepath, overwrite=True, save_format=None ) Arguments: filepath: String,
-

TensorFlow 模型载入方法汇总(小结)
一.TensorFlow常规模型加载方法 保存模型 tf.train.Saver()类,.save(sess, ckpt文件目录)方法 参数名称 功能说明 默认值 var_list Saver中存储变量集合 全局变量集合 reshape 加载时是否恢复变量形状 True sharded 是否将变量轮循放在所有设备上 True max_to_keep 保留最近检查点个数 5 restore_sequentially 是否按顺序恢复变量,模型较大时顺序恢复内存消耗小 True var_list是字典
-
TensorFlow Saver:保存和读取模型参数.ckpt实例
在使用TensorFlow的过程中,保存模型参数变量是很重要的一个环节,既可以保证训练过程信息不丢失,也可以帮助我们在需要快速恢复或使用一个模型的时候,利用之前保存好的参数之间导入,可以节省大量的训练时间.本文通过最简单的例程教大家如何保存和读取.ckpt文件. 一.保存到文件 首先是导入必要的东西: import tensorflow as tf import numpy as np 随便写几个变量: # Save to file # remember to define the same d
-
tensorflow实现读取模型中保存的值 tf.train.NewCheckpointReader
使用tf.trian.NewCheckpointReader(model_dir) 一个标准的模型文件有一下文件, model_dir就是MyModel(没有后缀) checkpoint Model.meta Model.data-00000-of-00001 Model.index import tensorflow as tf import pprint # 使用pprint 提高打印的可读性 NewCheck =tf.train.NewCheckpointReader("model&quo
-
关于Tensorflow 模型持久化详解
当我们使用 tensorflow 训练神经网络的时候,模型持久化对于我们的训练有很重要的作用. 如果我们的神经网络比较复杂,训练数据比较多,那么我们的模型训练就会耗时很长,如果在训练过程中出现某些不可预计的错误,导致我们的训练意外终止,那么我们将会前功尽弃.为了避免这个问题,我们就可以通过模型持久化(保存为CKPT格式)来暂存我们训练过程中的临时数据. 如果我们训练的模型需要提供给用户做离线的预测,那么我们只需要前向传播的过程,只需得到预测值就可以了,这个时候我们就可以通过模型持久化(保存为PB
-
RocketMQ Push 消费模型示例详解
目录 使用 DefaultMQPushConsumer 消费消息 基于长轮询机制的伪 push 实现 客户端侧发起的长轮询请求 服务端阻塞请求 客户端回调处理 客户端发起请求的底层逻辑 PullCallback 回调 总结 Push 模式是指由 Server 端来控制消息的推送,即当有消息到 Server 之后,会将消息主动投递给 client(Consumer 端). 使用 DefaultMQPushConsumer 消费消息 下面是使用 DefaultMQPushConsumer 消费消息的
-
Python深度学习之Keras模型转换成ONNX模型流程详解
目录 从Keras转换成PB模型 从PB模型转换成ONNX模型 改变现有的ONNX模型精度 部署ONNX 模型 总结 从Keras转换成PB模型 请注意,如果直接使用Keras2ONNX进行模型转换大概率会出现报错,这里笔者曾经进行过不同的尝试,最后都失败了. 所以笔者的推荐的情况是:首先将Keras模型转换为TensorFlow PB模型. 那么通过tf.keras.models.load_model()这个函数将模型进行加载,前提是你有一个基于h5格式或者hdf5格式的模型文件,最后再通过改
-
Java内存模型JMM详解
Java Memory Model简称JMM, 是一系列的Java虚拟机平台对开发者提供的多线程环境下的内存可见性.是否可以重排序等问题的无关具体平台的统一的保证.(可能在术语上与Java运行时内存分布有歧义,后者指堆.方法区.线程栈等内存区域). 并发编程有多种风格,除了CSP(通信顺序进程).Actor等模型外,大家最熟悉的应该是基于线程和锁的共享内存模型了.在多线程编程中,需要注意三类并发问题: ·原子性 ·可见性 ·重排序 原子性涉及到,一个线程执行一个复合操作的时候,其他线程是否能够看
-
对Django中内置的User模型实例详解
User模型 User模型是这个框架的核心部分.他的完整的路径是在django.contrib.auth.models.User. 字段 内置的User模型拥有以下的字段: 1.username: 用户名.150个字符以内.可以包含数字和英文字符,以及_.@.+..和-字符.不能为空,且必须唯一! 2.first_name:歪果仁的first_name,在30个字符以内.可以为空. 3.last_name:歪果仁的last_name,在150个字符以内.可以为空. 4.email:邮箱.可以为空
-
Java内存模型知识详解
1. 概述 多任务和高并发是衡量一台计算机处理器的能力重要指标之一.一般衡量一个服务器性能的高低好坏,使用每秒事务处理数(Transactions Per Second,TPS)这个指标比较能说明问题,它代表着一秒内服务器平均能响应的请求数,而TPS值与程序的并发能力有着非常密切的关系.在讨论Java内存模型和线程之前,先简单介绍一下硬件的效率与一致性. 2.硬件的效率与一致性 由于计算机的存储设备与处理器的运算能力之间有几个数量级的差距,所以现代计算机系统都不得不加入一层读写速度尽可能接近处理
-
go版tensorflow安装教程详解
此文章基于ubuntu16.04 先在这里贴上官方教程 https://github.com/tensorflow/tensorflow/tree/master/tensorflow/go 注意 安装go版的tensorflow时一定要先安装C版tensorflow且要部署好go语言 c版tensorflow官方教程 (Go 版本 TensorFlow 依赖于 TensorFlow C 语言库) 按照官方的指导就可以,没什么坑,最好是官方指定位置,否则后面可能会有坑! 安好后执行这个命令 go
-
python神经网络Xception模型复现详解
目录 什么是Xception模型 Xception网络部分实现代码 图片预测 Xception是继Inception后提出的对Inception v3的另一种改进,学一学总是好的 什么是Xception模型 Xception是谷歌公司继Inception后,提出的InceptionV3的一种改进模型,其改进的主要内容为采用depthwise separable convolution来替换原来Inception v3中的多尺寸卷积核特征响应操作. 在讲Xception模型之前,首先要讲一下什么是
-
python神经网络InceptionV3模型复现详解
目录 神经网络学习小记录21——InceptionV3模型的复现详解 学习前言什么是InceptionV3模型InceptionV3网络部分实现代码图片预测 学习前言 Inception系列的结构和其它的前向神经网络的结构不太一样,每一层的内容不是直直向下的,而是分了很多的块. 什么是InceptionV3模型 InceptionV3模型是谷歌Inception系列里面的第三代模型,其模型结构与InceptionV2模型放在了同一篇论文里,其实二者模型结构差距不大,相比于其它神经网络模型,Inc
-
python神经网络Densenet模型复现详解
目录 什么是Densenet Densenet 1.Densenet的整体结构 2.DenseBlock 3.Transition Layer 网络实现代码 什么是Densenet 据说Densenet比Resnet还要厉害,我决定好好学一下. ResNet模型的出现使得深度学习神经网络可以变得更深,进而实现了更高的准确度. ResNet模型的核心是通过建立前面层与后面层之间的短路连接(shortcuts),这有助于训练过程中梯度的反向传播,从而能训练出更深的CNN网络. DenseNet模型,