python 正则表达式语法学习笔记
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
本文重点给大家介绍python 正则表达式语法。
The special characters are:
"." Matches any character except a newline.
"^" Matches the start of the string.
"$" Matches the end of the string or just before the newline at
the end of the string.
"*" Matches 0 or more (greedy) repetitions of the preceding RE.
Greedy means that it will match as many repetitions as possible.
"+" Matches 1 or more (greedy) repetitions of the preceding RE.
"?" Matches 0 or 1 (greedy) of the preceding RE.
*?,+?,?? Non-greedy versions of the previous three special characters.
{m,n} Matches from m to n repetitions of the preceding RE.
{m,n}? Non-greedy version of the above.
"\\" Either escapes special characters or signals a special sequence.
[] Indicates a set of characters.
A "^" as the first character indicates a complementing set.
"|" A|B, creates an RE that will match either A or B.
(...) Matches the RE inside the parentheses.
The contents can be retrieved or matched later in the string.
(?aiLmsux) Set the A, I, L, M, S, U, or X flag for the RE (see below).
(?:...) Non-grouping version of regular parentheses.
(?P<name>...) The substring matched by the group is accessible by name.
(?P=name) Matches the text matched earlier by the group named name.
(?#...) A comment; ignored.
(?=...) Matches if ... matches next, but doesn't consume the string.
(?!...) Matches if ... doesn't match next.
(?<=...) Matches if preceded by ... (must be fixed length).
(?<!...) Matches if not preceded by ... (must be fixed length).
(?(id/name)yes|no) Matches yes pattern if the group with id/name matched,
the (optional) no pattern otherwise.The special sequences consist of "\\" and a character from the list
below. If the ordinary character is not on the list, then the
resulting RE will match the second character.
\number Matches the contents of the group of the same number.
\A Matches only at the start of the string.
\Z Matches only at the end of the string.
\b Matches the empty string, but only at the start or end of a word.
\B Matches the empty string, but not at the start or end of a word.
\d Matches any decimal digit; equivalent to the set [0-9] in
bytes patterns or string patterns with the ASCII flag.
In string patterns without the ASCII flag, it will match the whole
range of Unicode digits.
\D Matches any non-digit character; equivalent to [^\d].
\s Matches any whitespace character; equivalent to [ \t\n\r\f\v] in
bytes patterns or string patterns with the ASCII flag.
In string patterns without the ASCII flag, it will match the whole
range of Unicode whitespace characters.
\S Matches any non-whitespace character; equivalent to [^\s].
\w Matches any alphanumeric character; equivalent to [a-zA-Z0-9_]
in bytes patterns or string patterns with the ASCII flag.
In string patterns without the ASCII flag, it will match the
range of Unicode alphanumeric characters (letters plus digits
plus underscore).
With LOCALE, it will match the set [0-9_] plus characters defined
as letters for the current locale.
\W Matches the complement of \w.
\\ Matches a literal backslash.This module exports the following functions:
match Match a regular expression pattern to the beginning of a string.
fullmatch Match a regular expression pattern to all of a string.
search Search a string for the presence of a pattern.
sub Substitute occurrences of a pattern found in a string.
subn Same as sub, but also return the number of substitutions made.
split Split a string by the occurrences of a pattern.
findall Find all occurrences of a pattern in a string.
finditer Return an iterator yielding a match object for each match.
compile Compile a pattern into a RegexObject.
purge Clear the regular expression cache.
escape Backslash all non-alphanumerics in a string.Some of the functions in this module takes flags as optional parameters:
A ASCII For string patterns, make \w, \W, \b, \B, \d, \D
match the corresponding ASCII character categories
(rather than the whole Unicode categories, which is the
default).
For bytes patterns, this flag is the only available
behaviour and needn't be specified.
I IGNORECASE Perform case-insensitive matching.
L LOCALE Make \w, \W, \b, \B, dependent on the current locale.
M MULTILINE "^" matches the beginning of lines (after a newline)
as well as the string.
"$" matches the end of lines (before a newline) as well
as the end of the string.
S DOTALL "." matches any character at all, including the newline.
X VERBOSE Ignore whitespace and comments for nicer looking RE's.
U UNICODE For compatibility only. Ignored for string patterns (it
is the default), and forbidden for bytes patterns.
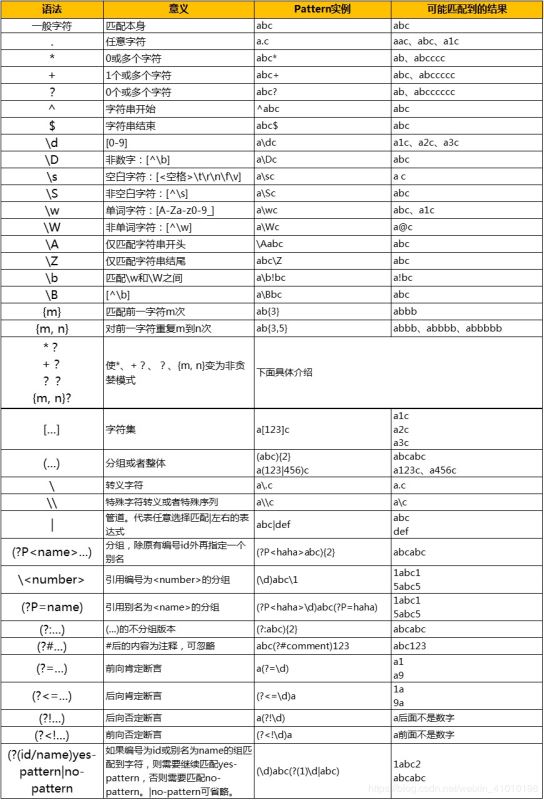
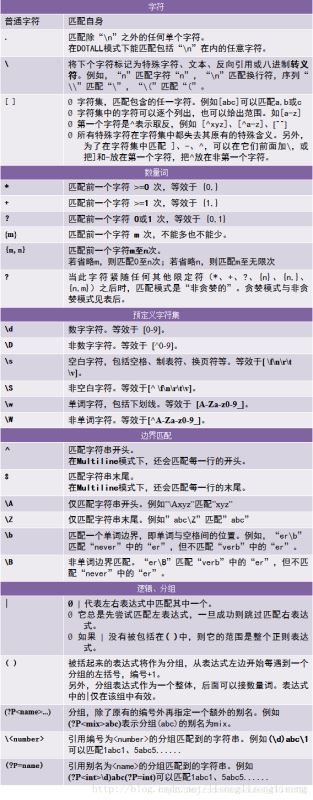
下面看下正则表达式匹配的流程:

正则表达式的大致匹配过程是:依次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。如果表达式中有量词或边界,这个过程会稍微有一些不同,但也是很好理解的,自己多使用几次就能明白。
总结
到此这篇关于python 正则表达式语法记录的文章就介绍到这了,更多相关python 正则表达式语法记录内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python 实用技巧之正则表达式查找和替换文本的操作方法
1.需求 我们想对字符串中的文本做查找和替换. 2.解决方案 对于简单的文本模式,使用str.replace()即可. 例如: text='mark ,帅哥,18,183 帅,mark' print(text.replace('18','19')) print(text) 运行结果: mark ,帅哥,19,193 帅,mark mark ,帅哥,18,183 帅,mark 针对更为复杂的模式,可以使用re模块中的sub()函数. 实例:将日期格式从"11/28/2018"改为&quo
-
python 正则表达式获取字符串中所有的日期和时间
提取日期前的处理 1.处理文本数据的日期格式统一化 text = "2015年8月31日,衢州元立金属制品有限公司仓储公司(以下简称元立仓储公司)成品仓库发生一起物体打击事故,造成直接经济损失95万元." text1 = "2015/12/28下达行政处罚决定书" text2 = "2015年8月发生一起物体打击事故" # 对文本处理一下 # 2015-8-31 2015-12-28 text = text.replace("年&quo
-
Python 正则表达式匹配数字及字符串中的纯数字
Python 正则表达式匹配数字 电话号码:\d{3}-\d{8}|\d{4}-\d{7} QQ号:[1-9][0-9]{4,} 中国邮政编码:[1-9]\d{5}(?!\d) 身份证:\d{15}|\d{18} ip地址:\d+\.\d+\.\d+\.\d+ [1-9]\d* 正整数 -[1-9]\d* 负整数 -?[1-9]\d* 整数 [1-9]\d*|0 非负整数 -[1-9]\d*|0 非正整数 [1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 正浮点数 -([1-
-
Python基础教程之正则表达式基本语法以及re模块
什么是正则: 正则表达式是可以匹配文本片段的模式. 正则表达式'Python'可以匹配'python' 正则是个很牛逼的东西,python中当然也不会缺少. 所以今天的Python就跟大家一起讨论一下python中的re模块. re模块包含对正则表达式的支持. 通配符 .表示匹配任何字符: '.ython'可以匹配'python'和'fython' 对特殊字符进行转义: 'python\.org'匹配'python.org' 字符集 '[pj]ython'能够匹配'python'和'jython
-

python 正则表达式语法学习笔记
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串.将匹配的子串替换或者从某个串中取出符合某个条件的子串等. Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式. re 模块使 Python 语言拥有全部的正则表达式功能. compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象.该对象拥有一系列方法用于正则表达式匹配和替换. 本文重点给大家介绍python 正则
-
python网络编程学习笔记(二):socket建立网络客户端
1.建立socket 建立socket对象需要搞清通信类型和协议家族.通信类型指明了用什么协议来传输数据.协议的例子包括IPv4.IPv6.IPX\SPX.AFP.对于internet通信,通信类型基本上都是AF_INET(和IPv4对应).协议家族一般表示TCP通信的SOCK_STREAM或者表示UDP通信的SOCK_DGRAM.因此对于TCP通信,建立一个socket连接的语句为:s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)对于UDP通
-
Python GUI编程学习笔记之tkinter中messagebox、filedialog控件用法详解
本文实例讲述了Python GUI编程学习笔记之tkinter中messagebox.filedialog控件用法.分享给大家供大家参考,具体如下: 相关内容: messagebox 介绍 使用 filedialog 介绍 使用 首发时间:2018-03-04 22:18 messagebox: 介绍:messagebox是tkinter中的消息框.对话框 使用: 导入模块:import tkinter.messagebox 选择消息框的模式: 提示消息框:[返回"ok"] tkint
-
Python GUI编程学习笔记之tkinter事件绑定操作详解
本文实例讲述了Python GUI编程学习笔记之tkinter事件绑定操作.分享给大家供大家参考,具体如下: 相关内容: command bind protocol 首发时间:2018-03-04 19:26 command: command是控件中的一个参数,如果使得command=函数,那么点击控件的时候将会触发函数 能够定义command的常见控件有: Button.Menu- 调用函数时,默认是没有参数传入的,如果要强制传入参数,可以考虑使用lambda from tkinter imp
-
Python GUI编程学习笔记之tkinter控件的介绍及基本使用方法详解
本文实例讲述了Python GUI编程学习笔记之tkinter控件的介绍及基本使用方法.分享给大家供大家参考,具体如下: 相关内容: tkinter的使用 1.模块的导入 2.使用 3.控件介绍 Tk Button Label Frame Toplevel Menu Menubutton Canvas Entry Message Text Listbox Checkbutton Radiobutton Scale Scrollbar 首发时间:2018-03-04 16:39 Python的GU
-
Python GUI编程学习笔记之tkinter界面布局显示详解
本文实例讲述了Python GUI编程学习笔记之tkinter界面布局显示.分享给大家供大家参考,具体如下: 相关内容: pack 介绍 常用参数 使用情况 常用函数 grid 介绍 常用参数 使用情况 常用函数 place 介绍 常用参数 使用情况 常用函数 首发时间:2018-03-04 14:20 pack: 介绍: pack几何管理器按行或列打包小部件. 可以使用填充fill,展开expand和靠边side等选项来控制此几何体管理器. pack的排放控件的形式就像将一个个控件按大小从上到
-
Python基础语言学习笔记总结(精华)
以下是Python基础学习内容的学习笔记的全部内容,非常的详细,如果你对Python语言感兴趣,并且针对性的系统学习一下基础语言知识,下面的内容能够很好的满足你的需求,如果感觉不错,就收藏以后慢慢跟着学习吧. 一.变量赋值及命名规则 ① 声明一个变量及赋值 #!/usr/bin/env python # -*- coding:utf-8 -*- # _author_soloLi name1="solo" name2=name1 print(name1,name2) name1 = &q
-
python网络爬虫学习笔记(1)
本文实例为大家分享了python网络爬虫的笔记,供大家参考,具体内容如下 (一) 三种网页抓取方法 1. 正则表达式: 模块使用C语言编写,速度快,但是很脆弱,可能网页更新后就不能用了. 2.Beautiful Soup 模块使用Python编写,速度慢. 安装: pip install beautifulsoup4 3. Lxml 模块使用C语言编写,即快速又健壮,通常应该是最好的选择. (二) Lxml安装 pip install lxml 如果使用lxml的css选择器,还要安装下面的
-
python入门之基础语法学习笔记
Python 中文编码 Python 文件中如果未指定编码,在执行过程会出现报错: Python中默认的编码格式是 ASCII 格式,在没修改编码格式时无法正确打印汉字,所以在读取中文时会报错. 解决方法为只要在文件开头加入 # -*- coding: UTF-8 -*- 或者 #coding=utf-8 就行了. Python 标识符 在 Python 里,标识符由字母.数字.下划线组成. 在 Python 中,所有标识符可以包括英文.数字以及下划线(_),但不能以数字开头. Python 中
-
python web框架学习笔记
一.web框架本质 1.基于socket,自己处理请求 #!/usr/bin/env python3 #coding:utf8 import socket def handle_request(client): #接收请求 buf = client.recv(1024) print(buf) #返回信息 client.send(bytes('<h1>welcome liuyao webserver</h1>','utf8')) def main(): #创建sock对象 sock