Java org.w3c.dom.Document 类方法引用报错
org.w3c.dom.Document 类方法引用报错
The method setXmlVersion(String) is undefined for the type Document
开发时我们可能会碰到这样的问题,它产生的原因是我们实际需要调用的是 JDK 环境 rt.jar 下的 org.w3c.dom.org.w3c.dom.Document ,但事实上 Eclipse 等 IDE 工具此时自动为我们调用的是 J2EE 中的 xerces\xmlParserAPIs\2.6.2\xmlParserAPIs-2.6.2.jar ,这一点通过 Ctrl 左键点击 Document 类可以发现。
发现问题出在哪里就好解决了
我们需要做的是调整 Eclipse 的调用顺序
项目右键 > Properties > Java Build Path > 右边 Order and Export
把 JRE System Library 通过点击 Up 按钮放到 J2EE(Maven Dependencies) 的上面即可。
org.w3c.dom(java dom)解析XML文档
位于org.w3c.dom操作XML会比较简单,就是将XML看做是一颗树,DOM就是对这颗树的一个数据结构的描述,但对大型XML文件效果可能会不理想
首先来了解点Java DOM 的 API:
1.解析器工厂类:DocumentBuilderFactory
创建的方法:
DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();
2.解析器:DocumentBuilder
创建方法:通过解析器工厂类来获得
DocumentBuilder db = dbf.newDocumentBuilder();
3.文档树模型Document
创建方法:a.通过xml文档 Document doc = db.parse("bean.xml"); b.将需要解析的xml文档转化为输入流 InputStream is = new FileInputStream("bean.xml");
Document doc = db.parse(is);
Document对象代表了一个XML文档的模型树,所有的其他Node都以一定的顺序包含在Document对象之内,排列成一个树状结构,以后对XML文档的所有操作都与解析器无关,
直接在这个Document对象上进行操作即可;
包含的方法:


4.节点列表类NodeList
NodeList代表了一个包含一个或者多个Node的列表,根据操作可以将其简化的看做为数组
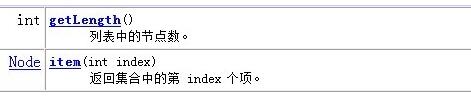
5.节点类Node
Node对象是DOM中最基本的对象,代表了文档树中的抽象节点。但在实际使用中很少会直接使用Node对象,而是使用Node对象的子对象Element,Attr,Text等
6.元素类Element
是Node类最主要的子对象,在元素中可以包含属性,因而Element中有存取其属性的方法

7.属性类Attr
代表某个元素的属性,虽然Attr继承自Node接口,但因为Attr是包含在Element中的,但并不能将其看做是Element的子对象,因为Attr并不是DOM树的一部分
基本的知识就到此结束,更加具体的大家可以参阅JDK API文档
实战:
1.使用DOM来遍历XML文档中的全部内容并且插入元素:
school.xml文档:
<?xml version = "1.0" encoding = "utf-8"?>
<School>
<Student>
<Name>沈浪</Name>
<Num>1006010022</Num>
<Classes>信管2</Classes>
<Address>浙江杭州3</Address>
<Tel>123456</Tel>
</Student>
<Student>
<Name>沈1</Name>
<Num>1006010033</Num>
<Classes>信管1</Classes>
<Address>浙江杭州4</Address>
<Tel>234567</Tel>
</Student>
<Student>
<Name>沈2</Name>
<Num>1006010044</Num>
<Classes>生工2</Classes>
<Address>浙江杭州1</Address>
<Tel>345678</Tel>
</Student>
<Student>
<Name>沈3</Name>
<Num>1006010055</Num>
<Classes>电子2</Classes>
<Address>浙江杭州2</Address>
<Tel>456789</Tel>
</Student>
</School>
DomDemo.java
package xidian.sl.dom;
import java.io.FileOutputStream;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.apache.crimson.tree.XmlDocument;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
public class DomDemo {
/**
* 遍历xml文档
* */
public static void queryXml(){
try{
//得到DOM解析器的工厂实例
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
//从DOM工厂中获得DOM解析器
DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder();
//把要解析的xml文档读入DOM解析器
Document doc = dbBuilder.parse("src/xidian/sl/dom/school.xml");
System.out.println("处理该文档的DomImplementation对象 = "+ doc.getImplementation());
//得到文档名称为Student的元素的节点列表
NodeList nList = doc.getElementsByTagName("Student");
//遍历该集合,显示结合中的元素及其子元素的名字
for(int i = 0; i< nList.getLength() ; i ++){
Element node = (Element)nList.item(i);
System.out.println("Name: "+ node.getElementsByTagName("Name").item(0).getFirstChild().getNodeValue());
System.out.println("Num: "+ node.getElementsByTagName("Num").item(0).getFirstChild().getNodeValue());
System.out.println("Classes: "+ node.getElementsByTagName("Classes").item(0).getFirstChild().getNodeValue());
System.out.println("Address: "+ node.getElementsByTagName("Address").item(0).getFirstChild().getNodeValue());
System.out.println("Tel: "+ node.getElementsByTagName("Tel").item(0).getFirstChild().getNodeValue());
}
}catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
/**
* 向已存在的xml文件中插入元素
* */
public static void insertXml(){
Element school = null;
Element student = null;
Element name = null;
Element num = null;
Element classes = null;
Element address = null;
Element tel = null;
try{
//得到DOM解析器的工厂实例
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
//从DOM工厂中获得DOM解析器
DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder();
//把要解析的xml文档读入DOM解析器
Document doc = dbBuilder.parse("src/xidian/sl/dom/school.xml");
//得到文档名称为Student的元素的节点列表
NodeList nList = doc.getElementsByTagName("School");
school = (Element)nList.item(0);
//创建名称为Student的元素
student = doc.createElement("Student");
//设置元素Student的属性值为231
student.setAttribute("examId", "23");
//创建名称为Name的元素
name = doc.createElement("Name");
//创建名称为 香香 的文本节点并作为子节点添加到name元素中
name.appendChild(doc.createTextNode("香香"));
//将name子元素添加到student中
student.appendChild(name);
/**
* 下面的元素依次加入即可
* */
num = doc.createElement("Num");
num.appendChild(doc.createTextNode("1006010066"));
student.appendChild(num);
classes = doc.createElement("Classes");
classes.appendChild(doc.createTextNode("眼视光5"));
student.appendChild(classes);
address = doc.createElement("Address");
address.appendChild(doc.createTextNode("浙江温州"));
student.appendChild(address);
tel = doc.createElement("Tel");
tel.appendChild(doc.createTextNode("123890"));
student.appendChild(tel);
//将student作为子元素添加到树的根节点school
school.appendChild(student);
//将内存中的文档通过文件流生成insertSchool.xml,XmlDocument位于crison.jar下
((XmlDocument)doc).write(new FileOutputStream("src/xidian/sl/dom/insertSchool.xml"));
System.out.println("成功");
}catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
public static void main(String[] args){
//读取
DomDemo.queryXml();
//插入
DomDemo.insertXml();
}
}
运行后结果:

然后到目录下查看生成的xml文件:

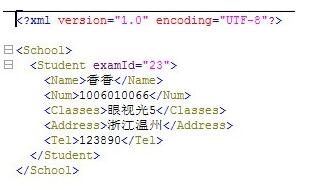
打开查看内容:

上面添加元素后输出的文件与之前的文件不是同一个文件,如果需要输出到原文件中,那么只要将路径改为原文间路径即可:src/xidian/sl/dom/school.xml
2.创建XML过程与插入过程相似,就是Document需要创建
package xidian.sl.dom;
import java.io.FileOutputStream;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.apache.crimson.tree.XmlDocument;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
public class CreateNewDom {
/**
* 创建xml文档
* */
public static void createDom(){
Document doc;
Element school,student;
Element name = null;
Element num = null;
Element classes = null;
Element address = null;
Element tel = null;
try{
//得到DOM解析器的工厂实例
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
//从DOM工厂中获得DOM解析器
DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder();
//创建文档树模型对象
doc = dbBuilder.newDocument();
if(doc != null){
//创建school元素
school = doc.createElement("School");
//创建student元素
student = doc.createElement("Student");
//设置元素Student的属性值为231
student.setAttribute("examId", "23");
//创建名称为Name的元素
name = doc.createElement("Name");
//创建名称为 香香 的文本节点并作为子节点添加到name元素中
name.appendChild(doc.createTextNode("香香"));
//将name子元素添加到student中
student.appendChild(name);
/**
* 下面的元素依次加入即可
* */
num = doc.createElement("Num");
num.appendChild(doc.createTextNode("1006010066"));
student.appendChild(num);
classes = doc.createElement("Classes");
classes.appendChild(doc.createTextNode("眼视光5"));
student.appendChild(classes);
address = doc.createElement("Address");
address.appendChild(doc.createTextNode("浙江温州"));
student.appendChild(address);
tel = doc.createElement("Tel");
tel.appendChild(doc.createTextNode("123890"));
student.appendChild(tel);
//将student作为子元素添加到树的根节点school
school.appendChild(student);
//添加到文档树中
doc.appendChild(school);
//将内存中的文档通过文件流生成insertSchool.xml,XmlDocument位于crison.jar下
((XmlDocument)doc).write(new FileOutputStream("src/xidian/sl/dom/createSchool.xml"));
System.out.println("创建成功");
}
}catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}
}
public static void main(String[] args) {
CreateNewDom.createDom();
}
}
运行结果:
DOM的操作应该还是非常简单明了的,掌握了没哦。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Java中使用DOM和SAX解析XML文件的方法示例
dom4j介绍 dom4j的项目地址:http://sourceforge.net/projects/dom4j/?source=directory dom4j是一个简单的开源库,用于处理XML. XPath和XSLT,它基于Java平台,使用Java的集合框架,全面集成了DOM,SAX和JAXP. dom4j的使用 下载了dom4j项目之后,解压缩,将其jar包(我的当前版本叫做dom4j-1.6.1.jar)加入class path下面. (Properties->Java Build Pa
-
Java:DocumentBuilderFactory调用XML的方法实例
首先得到:得到 DOM 解析器的工厂实例 DocumentBuilderFactory domfac=DocumentBuilderFactory.newInstance(); 然后从 DOM 工厂获得 DOM 解析器 DocumentBuilder dombuilder=domfac.newDocumentBuilder(); )把要解析的 XML 文档转化为输入流,以便 DOM 解析器解析它 InputStream is= new FileInputStream("test1.x
-
java中四种生成和解析XML文档的方法详解(介绍+优缺点比较+示例)
众所周知,现在解析XML的方法越来越多,但主流的方法也就四种,即:DOM.SAX.JDOM和DOM4J 下面首先给出这四种方法的jar包下载地址 DOM:在现在的Java JDK里都自带了,在xml-apis.jar包里 SAX:http://sourceforge.net/projects/sax/ JDOM:http://jdom.org/downloads/index.html DOM4J:http://sourceforge.net/projects/dom4j/ 一.介绍及优缺点分析
-
Java Document生成和解析XML操作
一)Document介绍 API来源:在JDK中javax.xml.*包下 使用场景: 1.需要知道XML文档所有结构 2.需要把文档一些元素排序 3.文档中的信息被多次使用的情况 优势:由于Document是java中自带的解析器,兼容性强 缺点:由于Document是一次性加载文档信息,如果文档太大,加载耗时长,不太适用 二)Document生成XML 实现步骤: 第一步:初始化一个XML解析工厂 DocumentBuilderFactory factory = DocumentBuilde
-
Java org.w3c.dom.Document 类方法引用报错
org.w3c.dom.Document 类方法引用报错 The method setXmlVersion(String) is undefined for the type Document 开发时我们可能会碰到这样的问题,它产生的原因是我们实际需要调用的是 JDK 环境 rt.jar 下的 org.w3c.dom.org.w3c.dom.Document ,但事实上 Eclipse 等 IDE 工具此时自动为我们调用的是 J2EE 中的 xerces\xmlParserAPIs\2.6.2\
-
java 如何使用org.w3c.dom操作XML文件
本篇介绍在java中,如何使用org.w3c.dom中的相关内容来操作XML文件.包括: 如何在内存中构建XML文件并写入磁盘: 如何从磁盘读取XML文件到内存: 如何添加注释,读取注释: 如何添加属性,读取属性: 如何添加子元素,读取子元素: 下面直接贴出样例代码: import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers
-
在java中使用dom解析xml的示例分析
dom是个功能强大的解析工具,适用于小文档 为什么这么说呢?因为它会把整篇xml文档装载进内存中,形成一颗文档对象树 总之听起来怪吓人的,不过使用它来读取点小东西相对Sax而言还是挺方便的 至于它的增删操作等,我是不打算写了,在我看教程的时候我就差点被那代码给丑到吐了 也正因为如此,才有后来那些jdom和dom4j等工具的存在-- 不多说,直接上代码 Dom解析示例 复制代码 代码如下: import java.io.File; import javax.xml.parsers.Document
-
Java如何基于DOM解析xml文件
一.Java解析xml.解析xml四种方法.DOM.SAX.JDOM.DOM4j.XPath 此文针对其中的DOM方法具体展开介绍及代码分析 sax.dom是两种对xml文档进行解析的方法(没有具体实现,只是接口),所以只有它们是无法解析xml文档的:jaxp只是api,它进一步封装了sax.dom两种接口,并且提供了DomcumentBuilderFactory/DomcumentBuilder和SAXParserFactory/SAXParser(默认使用xerces解释器).如果是嵌入式的
-
详解JavaScript对W3C DOM模版的支持情况
本文档对象模型允许访问所有的文档内容和修改,由万维网联合会(W3C)规范.几乎所有的现代浏览器都支持这种模式. 在W3C DOM规范的大部分传统DOM的功能,而且还增加了新的重要的功能.除了支持forms[ ], images[ ]和文档对象的其它数组属性,它定义了方法,使脚本来访问和操纵的任何文档元素,而不只是专用元件状的表单和图像. 文档属性在W3C DOM: 此模型支持所有传统DOM提供的属性.此外,这里是文档属性,可以使用W3C DOM访问列表: 文档方法在W3C DOM: 此模型支持所
-
elementui之el-tebs浏览器卡死的问题和使用报错未注册问题
elementui之新版本组件使用报错未注册问题 现在elementui已经更新到2.10.1也新加了一些组件,也给我们带来了很多的方便,再此非常感谢elementui,但是在有些版本中有些组件,应该是不太兼容,不知道大家有没有遇到过,下面我说下我遇到的两个小问题 我们习惯开发的时候看的文档都是最新的文档,当你去使用一些组件例如,无限滚动,日历这些,可能会遇到未注册的报错 报错是未注册这个组件,原因是你的elementui版本太低小于2.8.0,那个时候还没有这些组件,所以你去更新下elemen
-
详解Element-ui NavMenu子菜单使用递归生成时使用报错
当采用递归方式生成导航栏的子菜单时,菜单可以正常生成,但是当鼠标hover时,会出现循环调用某个(mouseenter)事件,导致最后报错 处理方式 注:2.13.2 版本,只需对子菜单设置属性 :popper-append-to-body="false" 就不会出现这个问题了 报错信息如下: Uncaught RangeError: Maximum call stack size exceeded. at VueComponent.handleMouseenter (inde
-
spring bean.xml文件p标签使用报错的解决
目录 bean.xml文件p标签使用报错 spring 的xml配置使用p标签简化 1.常见配置 可以配置如下 bean.xml文件p标签使用报错 The prefix "p" for attribute "p:某属性" associated with an element type "bean" is not bound. 某元素属性未捆绑,直接点击添加p的命名空间,或者手动在<beans>里面添加一行约束 xmlns:p=&quo
-
什么是DOM(Document Object Model)文档对象模型
D:document 文档 浏览器加载的页面 DOM O:object 对象 页面及页面中的任何元素都是对象 M:module 模型 页面中的元素的组织形式 DOM被W3C组织设计为一种平台无关.语言无关的API,程序或脚本通过其动态访问.修改文档的内容.样式.结构. DOM是web 浏览器的运行规范,javascript借助DOM成就了其web标准语言的地位,在web领域实现了所谓"一次编写到处运行"的目标. 文档对象模型(Document Object Model,DOM)是一种用