Python Pandas中DataFrame.drop_duplicates()删除重复值详解
目录
- 语法
- 参数
- 结果展示
- 扩展:识别重复值
- 总结
语法
df.drop_duplicates(subset = None,
keep = 'first',
inplace = False,
ignore_index = False)
参数
1.subset:指定的标签或标签序列,仅删除这些列重复值,默认情况为所有列
2.keep:确定要保留的重复值,有以下可选项:
first:保留第一次出现的重复值,默认
last:保留最后一次出现的重复值
False:删除所有重复值
3.inplace:是否生效
4.ignore_index:如果为True,则重新分配自然索引(0,1,…,n - 1)
# 删除重复值 DataFrame.drop_duplicates() import pandas as pd df = pd.DataFrame([['x','x',1],['x','x',1],['z','x',2]], columns = ['A','B','C']) # 删除重复行 res1 = df.drop_duplicates() # 删除指定列 res2 = df.drop_duplicates(subset = ['A']) # 保留最后一个 res3 = df.drop_duplicates(subset = ['A'], keep = 'last')
结果展示
df

res1
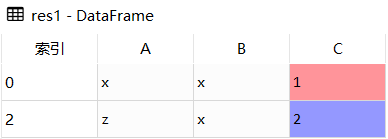
res2

res3

扩展:识别重复值
import pandas as pd
df = pd.DataFrame({
'studentID':['A001','A002','A003','A004','A005','A006','A006'],
'score':[100,93,94,96,93,95,95]})
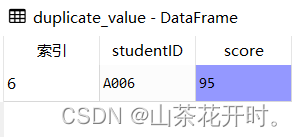
# 识别重复值
duplicate_value = df[df.duplicated()]
df
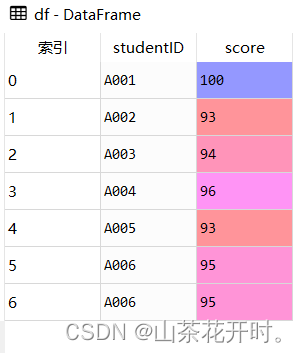
由上图可知studentID为'A006'的记录有两条,我们可以使用duplicated()方法识别重复值,它返回的是布尔值结果(True:有重复值,False:无重复值)

duplicate_value
总结
到此这篇关于Python Pandas中DataFrame.drop_duplicates()删除重复值的文章就介绍到这了,更多相关Pandas DataFrame.drop_duplicates()删除重复值内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

pandas去除重复值的实战
目录 加载数据 sample抽样函数 指定需要更新的值 append直接添加 append函数用法 根据某一列key值进行去重(key唯一) 加载数据 首先,我们需要加载到所需要的数据,这里我们所需要的数据是同过sample函数采样过来的. import pandas as pd #这里说明一下,clean_beer.csv数据有两千多行数据 #所以从其中采样一部分,来进行演示,当然可以简单实用data.head()也可以做练习 data = pd.read_csv('clean_beer.cs
-
pandas中DataFrame检测重复值的实现
本文详解如何使用pandas查看dataframe的重复数据,判断是否重复,以及如何去重 DataFrame.duplicated(subset=None, keep='first') subset:如果你认为几个字段重复,则数据重复,就把那几个字段以列表形式放到subset后面.默认是所有字段重复为重复数据. keep: 默认为'first' ,也就是如果有重复数据,则第一条出现的定义为False,后面的重复数据为True. 如果为'last',也就是如果有重复数据,则最后一条出现的定义为Fa
-
pandas统计重复值次数的方法实现
本文主要介绍了pandas统计重复值次数的方法实现,分享给大家,具体如下: from pandas import DataFrame df = DataFrame({'key1':['a','a','b','b','a','a'], 'key2':['one','two','one','two','one','one'], 'data1':[1,2,3,2,1,1], # 'data2':np.random.randn(5) }) # 打印数据框 print(df) # data1 key1 k
-
Python教程pandas数据分析去重复值
目录 加载数据 sample抽样函数 指定需要更新的值 append直接添加 append函数用法 根据某一列key值进行去重(key唯一) 加载数据 首先,我们需要加载到所需要的数据,这里我们所需要的数据是同过sample函数采样过来的. import pandas as pd #这里说明一下,clean_beer.csv数据有两千多行数据 #所以从其中采样一部分,来进行演示,当然可以简单实用data.head()也可以做练习 data = pd.read_csv('clean_beer.cs
-
Python Pandas中DataFrame.drop_duplicates()删除重复值详解
目录 语法 参数 结果展示 扩展:识别重复值 总结 语法 df.drop_duplicates(subset = None, keep = 'first', inplace = False, ignore_index = False) 参数 1.subset:指定的标签或标签序列,仅删除这些列重复值,默认情况为所有列 2.keep:确定要保留的重复值,有以下可选项: first:保留第一次出现的重复值,默认 last:保留最后一次出现的重复值 False:删除所有重复值 3.inplace:是否
-
Python pandas中apply函数简介以及用法详解
目录 1.基本信息 2.语法结构 3.使用案例 3.1 DataFrame使用apply 3.2 Series使用apply 3.3 其他案例 4.总结 参考链接: 1.基本信息 Pandas 的 apply() 方法是用来调用一个函数(Python method),让此函数对数据对象进行批量处理.Pandas 的很多对象都可以使用 apply() 来调用函数,如 Dataframe.Series.分组对象.各种时间序列等. 2.语法结构 apply() 使用时,通常放入一个 lambd
-
python pandas中DataFrame类型数据操作函数的方法
python数据分析工具pandas中DataFrame和Series作为主要的数据结构. 本文主要是介绍如何对DataFrame数据进行操作并结合一个实例测试操作函数. 1)查看DataFrame数据及属性 df_obj = DataFrame() #创建DataFrame对象 df_obj.dtypes #查看各行的数据格式 df_obj['列名'].astype(int)#转换某列的数据类型 df_obj.head() #查看前几行的数据,默认前5行 df_obj.tail() #查看后几
-
Python pandas找出、删除重复的数据实例
目录 前言 一.duplicated() 二.drop_duplicates() 总结 前言 当我们使用pandas处理数据的时候,经常会遇到数据重复的问题,如何找出重复数据进而分析重复原因,或者如何直接删除重复的数据是一个关键的步骤,pandas提供了很方便的方法:duplicated()和drop_duplicates(). 一.duplicated() duplicated()可以被用在DataFrame的三种情况下,分别是pandas.DataFrame.duplicated.panda
-
Pandas中DataFrame数据删除详情
目录 1.根据默认的行列索引操作 1.1行删除 1.2列删除 2.根据自定义的行列索引操作 2.1行删除 2.2列删除 本文介绍Pandas中DataFrame数据删除,主要使用drop.del方式. # drop函数的参数解释 drop( self, labels=None, # 就是要删除的行列的标签,用列表给定; axis=0, # axis是指处哪一个轴,0为行(默认),1为列; index=None, # index是指某一行或者多行 columns=None, # columns是指
-
python3中datetime库,time库以及pandas中的时间函数区别与详解
1介绍datetime库之前 我们先比较下time库和datetime库的区别 先说下time 在 Python 文档里,time是归类在Generic Operating System Services中,换句话说, 它提供的功能是更加接近于操作系统层面的.通读文档可知,time 模块是围绕着 Unix Timestamp 进行的. 该模块主要包括一个类 struct_time,另外其他几个函数及相关常量. 需要注意的是在该模块中的大多数函数是调用了所在平台C library的同名函数, 所以
-
Python Pandas学习之数据离散化与合并详解
目录 1数据离散化 1.1为什么要离散化 1.2什么是数据的离散化 1.3举例股票的涨跌幅离散化 2数据合并 2.1pd.concat实现数据合并 2.2pd.merge 1 数据离散化 1.1 为什么要离散化 连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数.离散化方法经常作为数据挖掘的工具. 1.2 什么是数据的离散化 连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值. 离散化有
-
对pandas中时间窗函数rolling的使用详解
在建模过程中,我们常常需要需要对有时间关系的数据进行整理.比如我们想要得到某一时刻过去30分钟的销量(产量,速度,消耗量等),传统方法复杂消耗资源较多,pandas提供的rolling使用简单,速度较快. 函数原型和参数说明 DataFrame.rolling(window, min_periods=None, freq=None, center=False, win_type=None, on=None, axis=0, closed=None) window:表示时间窗的大小,注意有两种形式
-
python爬虫中的url下载器用法详解
前期的入库筛选工作已经由url管理器完成了,整理的工作自然要由url下载器接手.当我们需要爬取的数据已经去重后,下载器的主要任务的是这些数据下载下来.所以它的使用也并不复杂,不过需要借助到我们之前所学过的一个库进行操作,相信之前的基础大家都学的很牢固.下面小编就来为大家介绍url下载器及其使用的方法. 下载器的作用就是接受URL管理器传递给它的一个url,然后把该网页的内容下载下来.python自带有urllib和urllib2等库(这两个库在python3中合并为urllib),它们的作用就是
-
Pandas中的unique()和nunique()区别详解
Pandas中Series和DataFrame的两种数据类型中都有nunique()和unique()方法.这两个方法作用很简单,都是求Series或Pandas中的不同值.而unique()方法返回的是去重之后的不同值,而nunique()方法则直接放回不同值的个数. 具体如下: 如果Series或DataFrame中没有None值,则unique()方法返回的序列数据的长度等于nunique()方法的返回值(如上述代码中所展示的).则当Series或DataFrame中有None值时,这两个