Python爬虫使用bs4方法实现数据解析
聚焦爬虫:
爬取页面中指定的页面内容。
编码流程:
- 1.指定url
- 2.发起请求
- 3.获取响应数据
- 4.数据解析
- 5.持久化存储
数据解析分类:
- 1.bs4
- 2.正则
- 3.xpath (***)
数据解析原理概述:
解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储
1.进行指定标签的定位
2.标签或者标签对应的属性中存储的数据值进行提取(解析)
bs4进行数据解析数据解析的原理:
1.标签定位
2.提取标签、标签属性中存储的数据值
bs4数据解析的原理:
1.实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中
2.通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取
环境安装:
pip install bs4 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple
实例化BeautifulSoup对象步骤:
from bs4 import BeautifulSoup
对象的实例化:
1.将本地的html文档中的数据加载到该对象中
fp = open('./test.html','r',encoding='utf-8')
soup = BeautifulSoup(fp,'lxml')
2.将互联网上获取的页面源码加载到该对象中(常用方法,推荐)
page_text = response.text
soup = BeatifulSoup(page_text,'lxml')
提供的用于数据解析的方法和属性:
soup.tagName:返回的是文档中第一次出现的tagName对应的标签
soup.find():
find('tagName'):等同于soup.div
1.属性定位:
soup.find('div',class_/id/attr='song')
soup.find_all('tagName'):返回符合要求的所有标签(列表)
select:
select('某种选择器(id,class,标签...选择器)'),返回的是一个列表。
2.层级选择器:
soup.select('.tang > ul > li > a'):>表示的是一个层级
soup.select('.tang > ul a'):空格表示的多个层级
3.获取标签之间的文本数据:
soup.a.text/string/get_text()
text/get_text():可以获取某一个标签中所有的文本内容
string:只可以获取该标签下面直系的文本内容
4.获取标签中属性值:
soup.a['href']
案例:爬取三国演义小说所有的章节标题和章节内容代码如下:
import requests
from bs4 import BeautifulSoup
if __name__ == "__main__":
#对首页的页面数据进行爬取
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = 'http://www.shicimingju.com/book/sanguoyanyi.html'
page_text = requests.get(url=url,headers=headers).text
#在首页中解析出章节的标题和详情页的url
#实例化BeautifulSoup对象,需要将页面源码数据加载到该对象中
soup = BeautifulSoup(page_text,'lxml')
#解析章节标题和详情页的url
li_list = soup.select('.book-mulu > ul > li')
fp = open('./sanguo.txt','w',encoding='utf-8')
for li in li_list:
title = li.a.string
detail_url = 'http://www.shicimingju.com'+li.a['href']
#对详情页发起请求,解析出章节内容
detail_page_text = requests.get(url=detail_url,headers=headers).text
#解析出详情页中相关的章节内容
detail_soup = BeautifulSoup(detail_page_text,'lxml')
div_tag = detail_soup.find('div',class_='chapter_content')
#解析到了章节的内容
content = div_tag.text
fp.write(title+':'+content+'\n')
print(title,'爬取成功!!!')
运行结果:
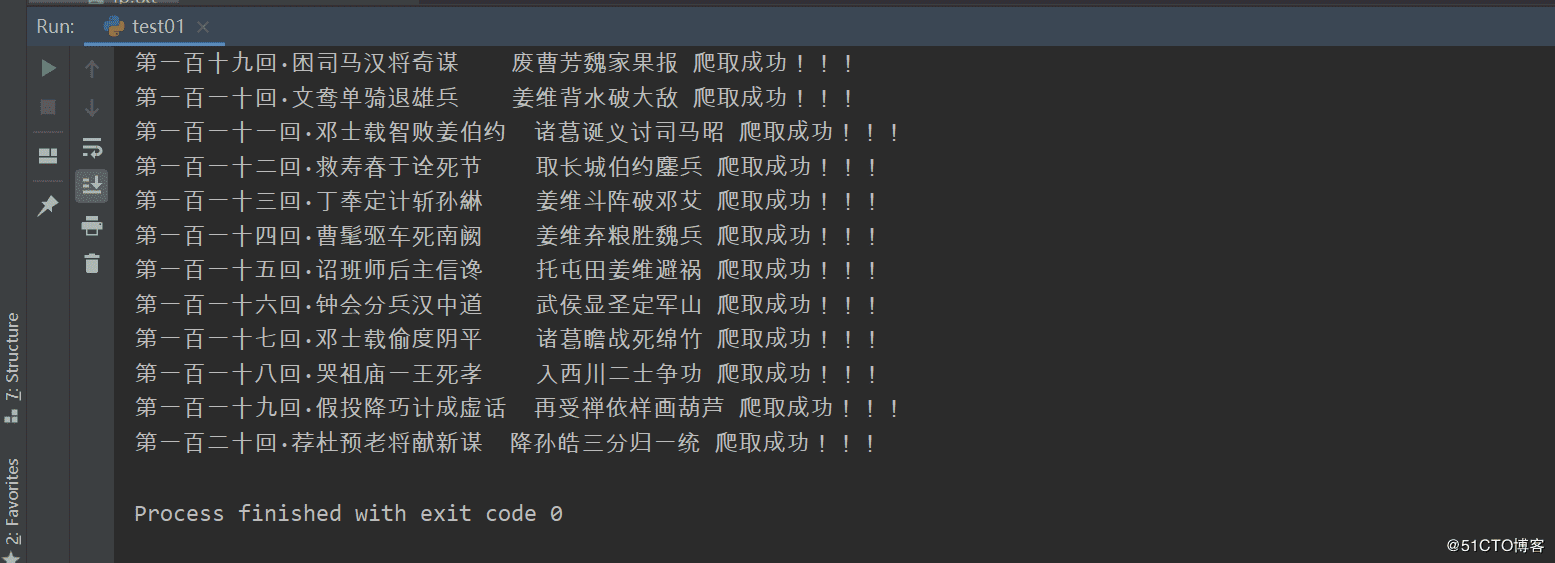
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
浅谈Python中的bs4基础
安装 在命令提示符框中直接输入pip install beautifulsoup4 介绍 beautifulsoup是python的一个第三方库,和xpath一样,都是用来解析html数据的. 引入 from bs4 import BeautifulSoup 使用 将一段文档传入BeautifulSoup的构造方法,就能得到一个文档的对象. bs = BeautifulSoup(open('index.html',encoding='utf-8'),'lxml') print(bs) 注意:这样
-
python中bs4.BeautifulSoup的基本用法
导入模块 from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc,"html.parser") 下面看下常见的用法 print(soup.a) # 拿到soup中的第一个a标签 print(soup.a.name) # 获取a标签的名称 print(soup.a.string) # 获取a标签的文本内容 print(soup.a.text) # 获取a标签的文本内容 print(soup.a["href"
-
Python BS4库的安装与使用详解
Beautiful Soup 库一般被称为bs4库,支持Python3,是我们写爬虫非常好的第三方库.因用起来十分的简便流畅.所以也被人叫做"美味汤".目前bs4库的最新版本是4.60.下文会介绍该库的最基本的使用,具体详细的细节还是要看:[官方文档](Beautiful Soup Documentation) bs4库的安装 Python的强大之处就在于他作为一个开源的语言,有着许多的开发者为之开发第三方库,这样我们开发者在想要实现某一个功能的时候,只要专心实现特定的功能,其他细节与
-

python利用re,bs4,requests模块获取股票数据
今天闲来无聊无意间看到了百度股票,就想着用python爬一下数据,于是就找到了东方财经网,结合这两个网站,写了一个小爬虫,数据保存在文件中,比较简单的示例,就当做用来练习正则表达式和BeautifulSoupl了. 首先页面分析,打开东方财经网股票列表页, 和百度股票详情页 ,右键查看网页源代码, 网址后面的代码就是股票代码,所以打算先获取股票代码,然后获取详情,废话少说,直接上代码吧: import re import requests from bs4 import BeautifulSou
-
python2使用bs4爬取腾讯社招过程解析
目的:获取腾讯社招这个页面的职位名称及超链接 职位类别 人数 地点和发布时间 要求:使用bs4进行解析,并把结果以json文件形式存储 注意:如果直接把python列表没有序列化为json数组,写入到json文件,会产生中文写不进去到文件,所以要序列化并进行utf-8编码后写入文件. # -*- coding:utf-8 -*- import requests from bs4 import BeautifulSoup as bs import json url = 'https://hr.te
-
Python使用bs4获取58同城城市分类的方法
本文实例讲述了Python使用bs4获取58同城城市分类的方法.分享给大家供大家参考.具体如下: # -*- coding:utf-8 -*- #! /usr/bin/python import urllib import os, datetime, sys from bs4 import BeautifulSoup reload(sys) sys.setdefaultencoding( "utf-8" ) __BASEURL__ = "http://bj.58.com/&q
-
Python爬虫使用bs4方法实现数据解析
聚焦爬虫: 爬取页面中指定的页面内容. 编码流程: 1.指定url 2.发起请求 3.获取响应数据 4.数据解析 5.持久化存储 数据解析分类: 1.bs4 2.正则 3.xpath (***) 数据解析原理概述: 解析的局部的文本内容都会在标签之间或者标签对应的属性中进行存储 1.进行指定标签的定位 2.标签或者标签对应的属性中存储的数据值进行提取(解析) bs4进行数据解析数据解析的原理: 1.标签定位 2.提取标签.标签属性中存储的数据值 bs4数据解析的原理: 1.实例化一个Beauti
-
python爬虫之bs4数据解析
一.实现数据解析 因为正则表达式本身有难度,所以在这里为大家介绍一下 bs4 实现数据解析.除此之外还有 xpath 解析.因为 xpath 不仅可以在 python 中使用,所以 bs4 和 正则解析一样,仅仅是简单地写两个案例(爬取可翻页的图片,以及爬取三国演义).以后的重点会在 xpath 上. 二.安装库 闲话少说,我们先来安装 bs4 相关的外来库.比较简单. 1.首先打开 cmd 命令面板,依次安装bs4 和 lxml. 2. 命令分别是 pip install bs4 和 pip
-
一个Python案例带你掌握xpath数据解析方法
目录 xpath基本概念 xpath解析原理 环境安装 如何实例化一个etree对象 xpath(‘xpath表达式’) xpath爬取58二手房实例 xpath图片解析下载实例 xpath爬取全国城市名称实例 xpath爬取简历模板实例 xpath基本概念 xpath解析:最常用且最便捷高效的一种解析方式.通用性强. xpath解析原理 1.实例化一个etree的对象,且需要将被解析的页面源码数据加载到该对象中 2.调用etree对象中的xpath方法结合xpath表达式实现标签的定位和内容的
-
python爬虫请求库httpx和parsel解析库的使用测评
Python网络爬虫领域两个最新的比较火的工具莫过于httpx和parsel了.httpx号称下一代的新一代的网络请求库,不仅支持requests库的所有操作,还能发送异步请求,为编写异步爬虫提供了便利.parsel最初集成在著名Python爬虫框架Scrapy中,后独立出来成立一个单独的模块,支持XPath选择器, CSS选择器和正则表达式等多种解析提取方式, 据说相比于BeautifulSoup,parsel的解析效率更高. 今天我们就以爬取链家网上的二手房在售房产信息为例,来测评下http
-
python爬虫模拟浏览器访问-User-Agent过程解析
这篇文章主要介绍了python爬虫模拟浏览器访问-User-Agent过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 模拟浏览器访问-User-Agent: import urllib2 #User-Agent 模拟浏览器访问 headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, li
-
Python爬虫爬取全球疫情数据并存储到mysql数据库的步骤
思路:使用Python爬虫对腾讯疫情网站世界疫情数据进行爬取,封装成一个函数返回一个 字典数据格式的对象,写另一个方法调用该函数接收返回值,和数据库取得连接后把 数据存储到mysql数据库. 一.mysql数据库建表 CREATE TABLE world( id INT(11) NOT NULL AUTO_INCREMENT, dt DATETIME NOT NULL COMMENT '日期', c_name VARCHAR(35) DEFAULT NULL COMMENT '国家'
-
Python爬虫爬取电影票房数据及图表展示操作示例
本文实例讲述了Python爬虫爬取电影票房数据及图表展示操作.分享给大家供大家参考,具体如下: 爬虫电影历史票房排行榜 http://www.cbooo.cn/BoxOffice/getInland?pIndex=1&t=0 Python爬取历史电影票房纪录 解析Json数据 横向条形图展示 面向对象思想 导入相关库 import requests import re from matplotlib import pyplot as plt from matplotlib import font
-
Python爬虫HTPP请求方法有哪些
HTTP请求方法 GET:请求指定的页面信息,并返回实体主体. HEAD:类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 POST:向指定资源提交数据进行处理请求(例如提交表单或者上传文件),数据被包含在请求体中.POST请求可能会导致新的资源的建立和/或已有资源的修改. PUT:从客户端向服务器传送的数据取代指定的文档的内容. DELETE:请求服务器删除指定的页面. CONNECT:HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器. OPTIONS:允许客户端
-
Python爬虫获取国外大桥排行榜数据清单
目录 目标站点分析 编码时间 前言: 本例开始学习 PyQuery 解析框架,该解析对从前端转 Python 的朋友非常友好,因为它模拟的是 JQuery 操作. 正式开始前,先安装 pyquery 到本地开发环境中.命令如下:pip install pyquery ,我使用的版本为 1.4.3. 基本使用如下所示,看懂也就掌握了 5 成了,就这么简单. from pyquery import PyQuery as pq s = '<html><title>橡皮擦的PyQuery小
-
用Python爬虫破解滑动验证码的案例解析
做爬虫总会遇到各种各样的反爬限制,反爬的第一道防线往往在登录就出现了,为了限制爬虫自动登录,各家使出了浑身解数,所谓道高一尺魔高一丈. 今天分享个如何简单处理滑动图片的验证码的案例. 类似这种拖动滑块移动到图片中缺口位置与之重合的登录验证在很多网站或者APP都比较常见,因为它对真实用户体验友好,容易识别.同时也能拦截掉大部分初级爬虫. 作为一只python爬虫,如何正确地自动完成这个验证过程呢? 先来分析下,核心问题其实是要怎么样找到目标缺口的位置,一旦知道了位置,我们就可以借用selenium