python实现数据清洗(缺失值与异常值处理)
1。 将本地sql文件写入mysql数据库
本文写入的是python数据库的taob表
source [本地文件]
其中总数据为9616行,列分别为title,link,price,comment
2。使用python链接并读取数据
查看数据概括
#-*- coding:utf-8 -*-
#author:M10
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import mysql.connector
conn = mysql.connector.connect(host='localhost',
user='root',
passwd='123456',
db='python')#链接本地数据库
sql = 'select * from taob'#sql语句
data = pd.read_sql(sql,conn)#获取数据
print(data.describe())
说明数据的导入是正确的,简单的分析发现问题并不是这么简单,因为comment均值562可能偏大,最大评论数454037也可能出现错误,price价格为0也不太可能出现。
price comment count 9616.00000 9616.000000 mean 64.49324 562.239601 std 176.10901 6078.909643 min 0.00000 0.000000 25% 20.00000 16.000000 50% 36.00000 58.000000 75% 66.00000 205.000000 max 7940.00000 454037.000000
3。缺失值处理
将价格为0的值设置为中位数36
#-*- coding:utf-8 -*-
#author:M10
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import mysql.connector
conn = mysql.connector.connect(host='localhost',
user='root',
passwd='123456',
db='python')#链接本地数据库
sql = 'select * from taob'#sql语句
data = pd.read_sql(sql,conn)#获取数据
data['price'][data['price']==0]=None
x = 0
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull()) [j]:
data[i][j]='36'
x+=1
print(x)
#44
结果显示修改了44行的数据。
4。异常值处理
#-*- coding:utf-8 -*-
#author:M10
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import mysql.connector
conn = mysql.connector.connect(host='localhost',
user='root',
passwd='123456',
db='python')#链接本地数据库
sql = 'select * from taob'#sql语句
data = pd.read_sql(sql,conn)#获取数据
#缺失值处理
data['price'][data['price']==0]=None
x = 0
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull()) [j]:
data[i][j]='36'
x+=1
print(x)
#异常值处理
#绘制散点图,价格为横轴
data1 = data.T#转置
price = data1.values[2]
comment = data1.values[3]
plt.plot(price,comment,'o')
plt.show()
#print(price)
结果如下图,价格为0左右时comment很大可能为异常值,comments为0时,价格极大这个有可能的。
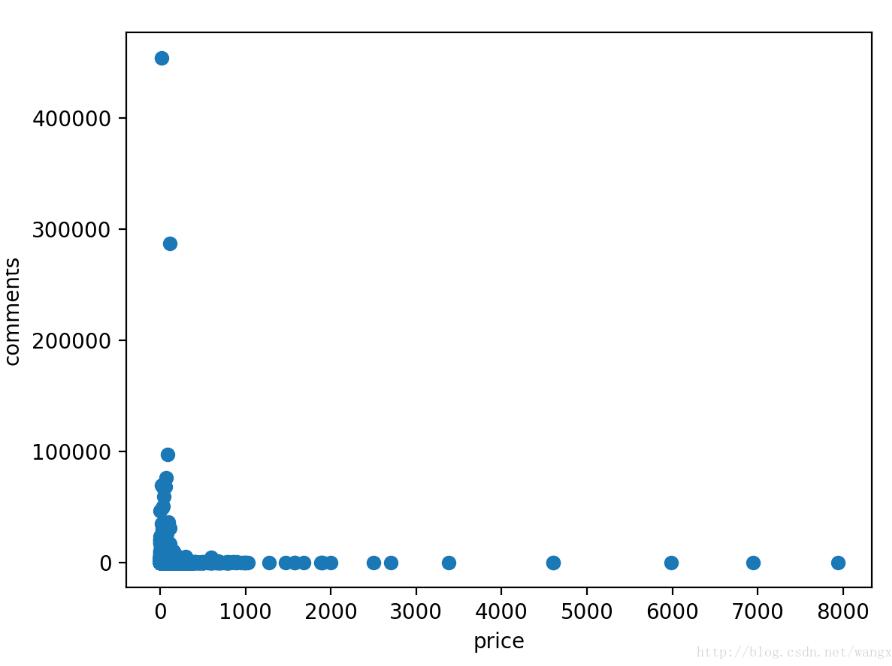
接下来处理评论数异常值,假设异常值分割线设置为20w,
#-*- coding:utf-8 -*-
#author:M10
import numpy as np
import pandas as pd
import matplotlib.pylab as plt
import mysql.connector
conn = mysql.connector.connect(host='localhost',
user='root',
passwd='123456',
db='python')#链接本地数据库
sql = 'select * from taob'#sql语句
data = pd.read_sql(sql,conn)#获取数据
#缺失值处理
data['price'][data['price']==0]=None
x = 0
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull()) [j]:
data[i][j]='36'
x+=1
print(x)
#异常值处理
da = data.values#重新赋值data
#异常值处理,将commments大于200000的数据comments设置为58
cont_clou = len(da)#获取行数
#遍历数据进行处理
for i in range(0,cont_clou):
if(data.values[i][3]>200000):
#print(data.values[i][3])
da[i][3]='58'
#print(da[i][3])
#绘制散点图,价格为横轴
data1 = da.T#转置
price = data1[2]
comment = data1[3]
plt.plot(price,comment,'o')
plt.xlabel('price')
plt.ylabel('comments')
plt.show()
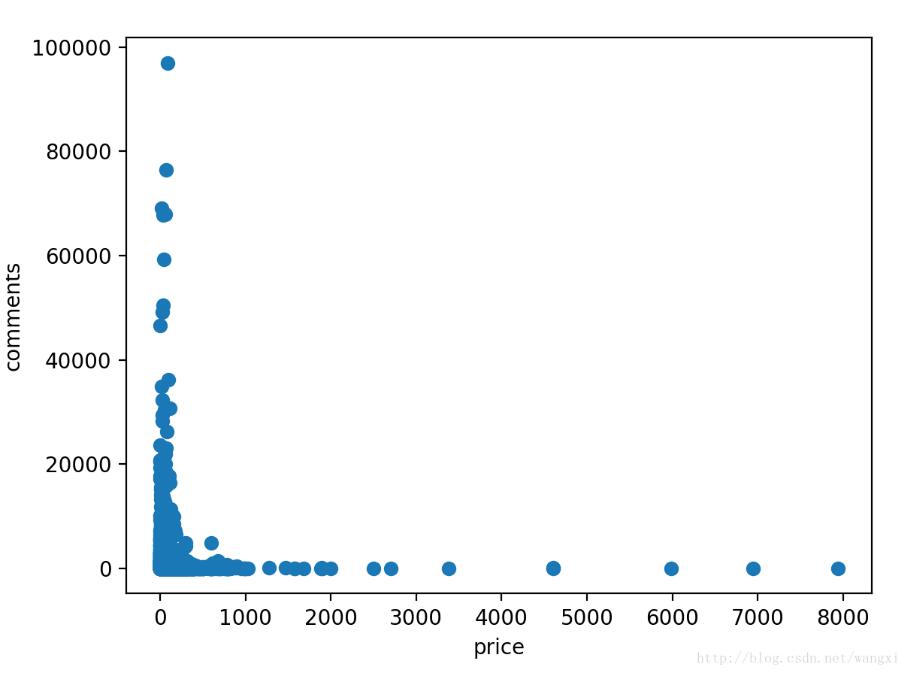
处理后的输出结果为:
以上这篇python实现数据清洗(缺失值与异常值处理)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Pandas 数据处理,数据清洗详解
如下所示: # -*-coding:utf-8-*- from pandas import DataFrame import pandas as pd import numpy as np """ 获取行列数据 """ df = DataFrame(np.random.rand(4, 5), columns=['A', 'B', 'C', 'D', 'E']) print df print df['col_sum'] = df.apply(lam
-
python3常用的数据清洗方法(小结)
首先载入各种包: import pandas as pd import numpy as np from collections import Counter from sklearn import preprocessing from matplotlib import pyplot as plt %matplotlib inline import seaborn as sns plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体 p
-
数据清洗--DataFrame中的空值处理方法
数据清洗是一项复杂且繁琐的工作,同时也是整个数据分析过程中最为重要的环节. 在python中空值被显示为NaN.首先,我们要构造一个包含NaN的DataFrame对象. >>> import numpy as np >>> import pandas as pd >>> from pandas import Series,DataFrame >>> from numpy import nan as NaN >>> d
-

python实现数据预处理之填充缺失值的示例
1.给定一个数据集noise-data-1.txt,该数据集中保护大量的缺失值(空格.不完整值等).利用"全局常量"."均值或者中位数"来填充缺失值. noise-data-1.txt: 5.1 3.5 1.4 0.2 4.9 3 1.4 0.2 4.7 3.2 1.3 0.2 4.6 3.1 1.5 0.2 5 3.6 1.4 0.2 5.4 3.9 1.7 0.4 4.6 3.4 1.4 0.3 5 3.4 1.5 0.2 4.4 2.9 1.4 0.2 4.9
-
pandas 缺失值与空值处理的实现方法
1.相关函数 df.dropna() df.fillna() df.isnull() df.isna() 2.相关概念 空值:在pandas中的空值是"" 缺失值:在dataframe中为nan或者naT(缺失时间),在series中为none或者nan即可 3.函数具体解释 DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) 函数作用:删除含有空值的行或列 axis:维度,axis=
-
python实现数据清洗(缺失值与异常值处理)
1. 将本地sql文件写入mysql数据库 本文写入的是python数据库的taob表 source [本地文件] 其中总数据为9616行,列分别为title,link,price,comment 2.使用python链接并读取数据 查看数据概括 #-*- coding:utf-8 -*- #author:M10 import numpy as np import pandas as pd import matplotlib.pylab as plt import mysql.connector
-
利用Python进行数据清洗的操作指南
目录 缺失值 异常值 数据不一致 无效数据 重复数据 数据泄漏问题 你一定听说过这句著名的数据科学名言: 在数据科学项目中, 80% 的时间是在做数据处理. 如果你没有听过,那么请记住:数据清洗是数据科学工作流程的基础. 机器学习模型会根据你提供的数据执行,混乱的数据会导致性能下降甚至错误的结果,而干净的数据是良好模型性能的先决条件. 当然干净的数据并不意味着一直都有好的性能,模型的正确选择(剩余 20%)也很重要,但是没有干净的数据,即使是再强大的模型也无法达到预期的水平. 在本文中将列出数据
-
pandas数据清洗(缺失值和重复值的处理)
目录 前言 缺失值处理 缺失值的判断 缺失值统计 缺失值筛选 缺失值类型 插入缺失值 缺失值填充 插值填充 interpolate() 的具体参数 缺失值删除 缺失值删除 dropna 重复值处理 重复值查找 删除重复值 drop删除数据 数据替换replace 字符替换 缺失值替换 数字替换 数据裁剪df.clip() 前言 pandas对大数据有很多便捷的清洗用法,尤其针对缺失值和重复值.缺失值就不用说了,会影响计算,重复值有时候可能并未带来新的信息反而增加了计算量,所以有时候要进行处理.针
-
Python Pandas找到缺失值的位置方法
问题描述: python pandas判断缺失值一般采用 isnull(),然而生成的却是所有数据的true/false矩阵,对于庞大的数据dataframe,很难一眼看出来哪个数据缺失,一共有多少个缺失数据,缺失数据的位置. 首先对于存在缺失值的数据,如下所示 import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(10,6)) # Make a few areas have NaN values df.
-
Python数据分析之缺失值检测与处理详解
目录 检测缺失值 缺失值处理 删除缺失值 填补缺失值 检测缺失值 我们先创建一个带有缺失值的数据框(DataFrame). import pandas as pd df = pd.DataFrame( {'A': [None, 2, None, 4], 'B': [10, None, None, 40], 'C': [100, 200, None, 400], 'D': [None, 2000, 3000, None]}) df 数值类缺失值在 Pandas 中被显示为 NaN (Not A N
-
python数据分析实战指南之异常值处理
目录 异常值 1.异常值定义 2.异常值处理方式 2.1 均方差 2.2 箱形图 3.实战 3.1 加载数据 3.2 检测异常值数据 3.3 显示异常值的索引位置 总结 异常值 异常值是指样本中的个别值,其数值明显偏离其余的观测值.异常值也称离群点,异常值的分析也称为离群点的分析. 常用的异常值分析方法为3σ原则.箱型图分析.机器学习算法检测,一般情况下对异常值的处理都是删除和修正填补,即默认为异常值对整个项目的作用不大,只有当我们的目的是要求准确找出离群点,并对离群点进行分析时有必要用到机器学
-
Python Pandas中缺失值NaN的判断,删除及替换
目录 前言 1. 检查缺失值NaN 2. Pandas中NaN的类型 3. NaN的删除 dropna() 3.1 删除所有值均缺失的行/列 3.2 删除至少包含一个缺失值的行/列 3.3 根据不缺少值的元素数量删除行/列 3.4 删除特定行/列中缺少值的列/行 4. 缺失值NaN的替换(填充) fillna() 4.1 用通用值统一替换 4.2 为每列替换不同的值 4.3 用每列的平均值,中位数,众数等替换 4.4 替换为上一个或下一个值 总结 前言 当使用pandas读取csv文件时,如果元
-
Python实现数据清洗的示例详解
目录 前言 去掉信息不全的用户 描述 答案 修补缺失的用户数据 描述 答案 解决牛客网用户重复的数据 描述 答案 统一最后刷题日期的格式 描述 答案 将用户的json文件转换为表格形式 描述 答案 前言 Python实际针对数据分析的学习是库,用库来解决一系列的数据分析问题 去掉信息不全的用户 描述 现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔): Nowcoder_ID:用户ID Level:等级 Achievement_value
-
Python pandas处理缺失值方法详解(dropna、drop、fillna)
目录 面对缺失值三种处理方法: 对于option1: 对于option 2: 对于option3 总结 面对缺失值三种处理方法: option 1: 去掉含有缺失值的样本(行) option 2:将含有缺失值的列(特征向量)去掉 option 3:将缺失值用某些值填充(0,平均值,中值等) 对于dropna和fillna,dataframe和series都有,在这主要讲datafame的 对于option1: 使用DataFrame.dropna(axis=0, how='any', thres
-
Python Pandas对缺失值的处理方法
Pandas使用这些函数处理缺失值: isnull和notnull:检测是否是空值,可用于df和series dropna:丢弃.删除缺失值 axis : 删除行还是列,{0 or 'index', 1 or 'columns'}, default 0 how : 如果等于any则任何值为空都删除,如果等于all则所有值都为空才删除 inplace : 如果为True则修改当前df,否则返回新的df fillna:填充空值 value:用于填充的值,可以是单个值,或者字典(key是列名,valu