python实现高斯判别分析算法的例子
高斯判别分析算法(Gaussian discriminat analysis)
高斯判别算法是一个典型的生成学习算法(关于生成学习算法可以参考我的另外一篇博客)。在这个算法中,我们假设p(x|y)p(x|y)服从多元正态分布。
注:在判别学习算法中,我们假设p(y|x)p(y|x)服从一维正态分布,这个很好类比,因为在模型中输入数据XX通常是拥有很多维度的,所以对于XX的条件概率建模时要取多维正态分布。
多元正态分布
多元正态分布也叫多元高斯分布,这个分布的两个参数分别是平均向量μ∈Rnμ∈Rn和一个协方差矩阵∑∈Rn×n∑∈Rn×n
关于协方差矩阵的定义;假设XX是由nn个标量随机变量组成的列向量,并且μkμk是第kk个元素的期望值,即μk=E(Xk)μk=E(Xk),那么协方差矩阵被定义为

下面是一些二维高斯分布的概率密度图像:
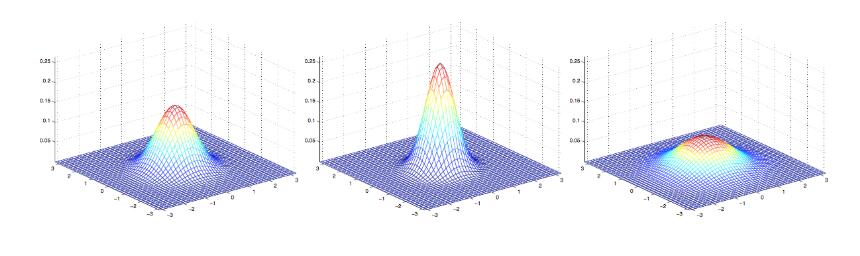
最右边的图像展现的二维高斯分布的均值是零向量(2x1的零向量),协方差矩阵Σ=IΣ=I(2x2的单位矩阵),像这样以零向量为均值以单位阵为协方差的多维高斯分布称为标准正态分布,中间的图像以零向量为均值,Σ=0.6IΣ=0.6I;最右边的图像中Σ=2IΣ=2I,观察发现当ΣΣ越大时,高斯分布越“铺开”,当ΣΣ越小时,高斯分布越“收缩”。
让我们看一些其他例子对比发现规律
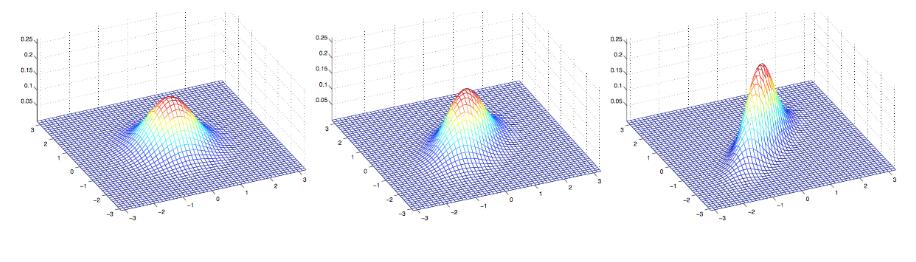
上图中展示的三个高斯分布对应的均值均为零向量,协方差矩阵分别对应与下面三个
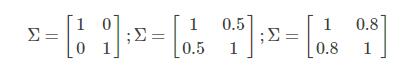
最左边的图像是我们熟悉的标准二维正态分布,然后我们观察到当我们增加ΣΣ的非主对角元素时,概率密度图像沿着45°线(x1=x2x1=x2)“收缩”,从对应的等高线轮廓图可以跟清楚的看到这一点:
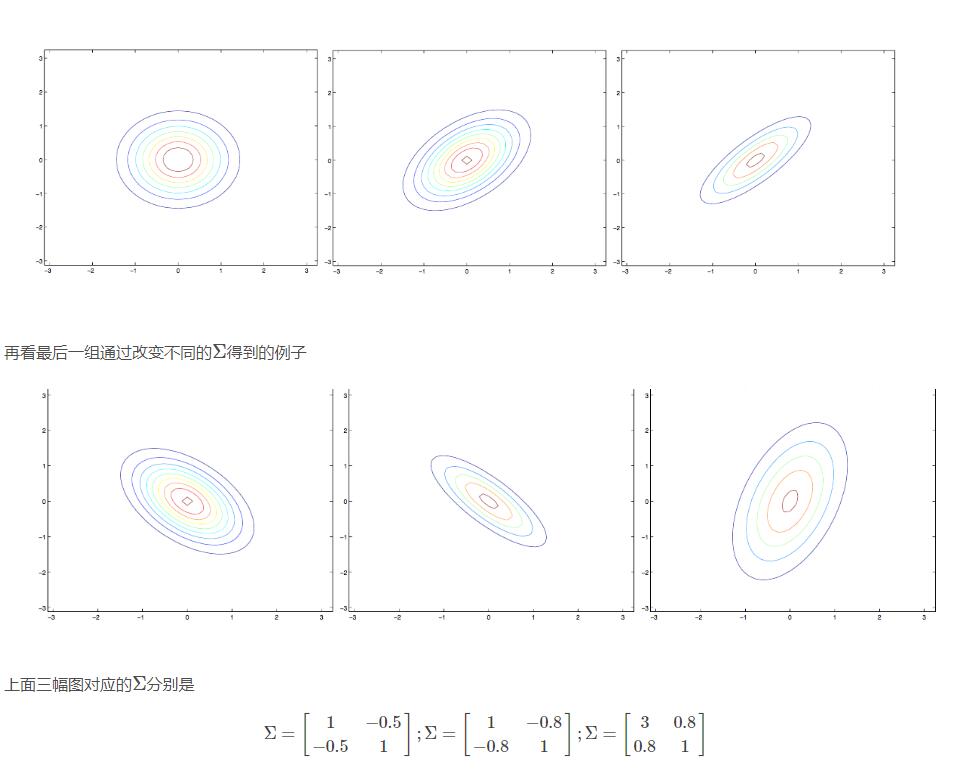
通过对比右边和中间的两幅图发现,通过减少主对角元素可以让概率密度图像变得“收缩”,不过是在相反的方向上。
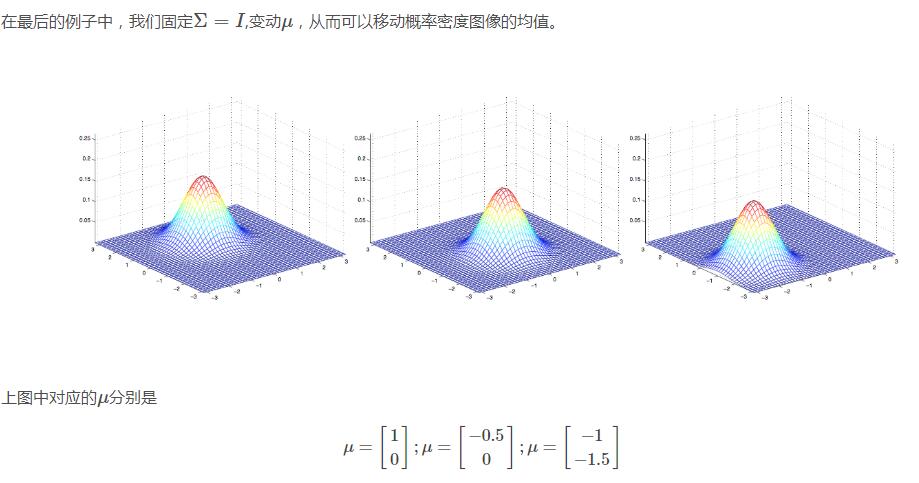
高斯判别分析模型
当我们处理输入特征是连续随机变量xx时的分类问题时,我们可以使用高斯判别分析模型(GDA),用多元正态分布模型来描述p(x|y)p(x|y),模型的具体数学表达式是这样的:

通过最大化似然函数ll可以得到上面四个参数的估计值:
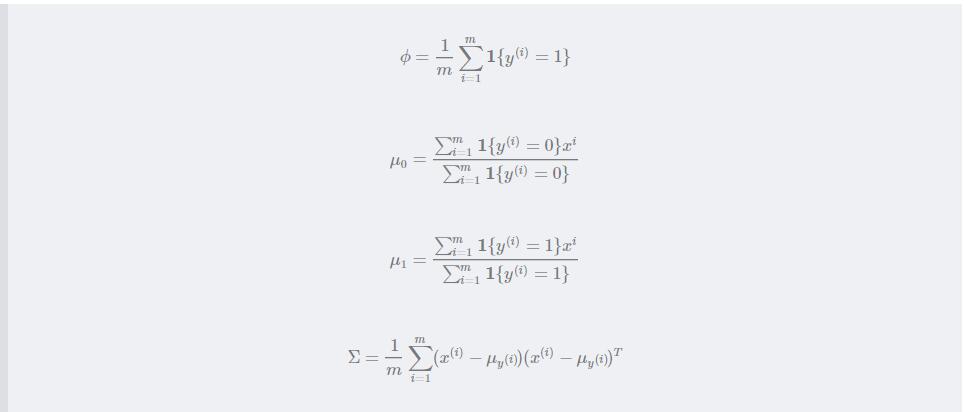
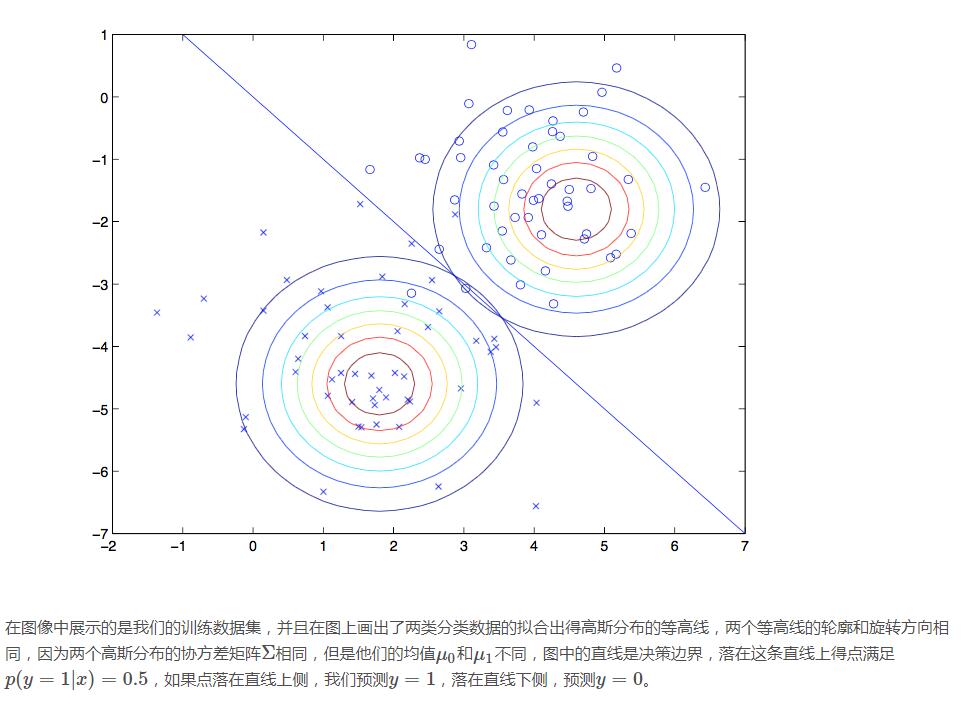
我们用图像直观的描述一下算法处理的结果:
python的实现demo 如下:
第57的高斯概率密度函数用矩阵运算写有bug没跑通,又因为实验数据只有二维,于是在纸上对上文中矩阵运算公式进行了化简至最后结果写在了函数里。如有疑问可以拿出笔来演算一下。
#GDA
#author:Xiaolewen
import matplotlib.pyplot as plt
from numpy import *
#Randomly generate two cluster data of Gaussian distributions
mean0=[2,3]
cov=mat([[1,0],[0,2]])
x0=random.multivariate_normal(mean0,cov,500).T #The first class point which labael equal 0
y0=zeros(shape(x0)[1])
#print x0,y0
mean1=[7,8]
cov=mat([[1,0],[0,2]])
x1=random.multivariate_normal(mean1,cov,300).T
y1=ones(shape(x1)[1]) #The second class point which label equals 1
#print x1,y1
x=array([concatenate((x0[0],x1[0])),concatenate((x0[1],x1[1]))])
y=array([concatenate((y0,y1))])
m=shape(x)[1]
#print x,y,m
#Caculate the parameters:\phi,\u0,\u1,\Sigma
phi=(1.0/m)*len(y1)
#print phi
u0=mean(x0,axis=1)
#print u0
u1=mean(x1,axis=1)
#print u1
xplot0=x0;xplot1=x1 #save the original data to plot
x0=x0.T;x1=x1.T;x=x.T
#print x0,x1,x
x0_sub_u0=x0-u0
x1_sub_u1=x1-u1
#print x0_sub_u0
#print x1_sub_u1
x_sub_u=concatenate([x0_sub_u0,x1_sub_u1])
#print x_sub_u
x_sub_u=mat(x_sub_u)
#print x_sub_u
sigma=(1.0/m)*(x_sub_u.T*x_sub_u)
#print sigma
#plot the discriminate boundary ,use the u0_u1's midnormal
midPoint=[(u0[0]+u1[0])/2.0,(u0[1]+u1[1])/2.0]
#print midPoint
k=(u1[1]-u0[1])/(u1[0]-u0[0])
#print k
x=range(-2,11)
y=[(-1.0/k)*(i-midPoint[0])+midPoint[1] for i in x]
#plot contour for two gaussian distributions
def gaussian_2d(x, y, x0, y0, sigmaMatrix):
return exp(-0.5*((x-x0)**2+0.5*(y-y0)**2))
delta = 0.025
xgrid0=arange(-2, 6, delta)
ygrid0=arange(-2, 6, delta)
xgrid1=arange(3,11,delta)
ygrid1=arange(3,11,delta)
X0,Y0=meshgrid(xgrid0, ygrid0) #generate the grid
X1,Y1=meshgrid(xgrid1,ygrid1)
Z0=gaussian_2d(X0,Y0,2,3,cov)
Z1=gaussian_2d(X1,Y1,7,8,cov)
#plot the figure and add comments
plt.figure(1)
plt.clf()
plt.plot(xplot0[0],xplot0[1],'ko')
plt.plot(xplot1[0],xplot1[1],'gs')
plt.plot(u0[0],u0[1],'rx',markersize=20)
plt.plot(u1[0],u1[1],'y*',markersize=20)
plt.plot(x,y)
CS0=plt.contour(X0, Y0, Z0)
plt.clabel(CS0, inline=1, fontsize=10)
CS1=plt.contour(X1,Y1,Z1)
plt.clabel(CS1, inline=1, fontsize=10)
plt.title("Gaussian discriminat analysis")
plt.xlabel('Feature Dimension (0)')
plt.ylabel('Feature Dimension (1)')
plt.show(1)
这是最终的拟合结果:
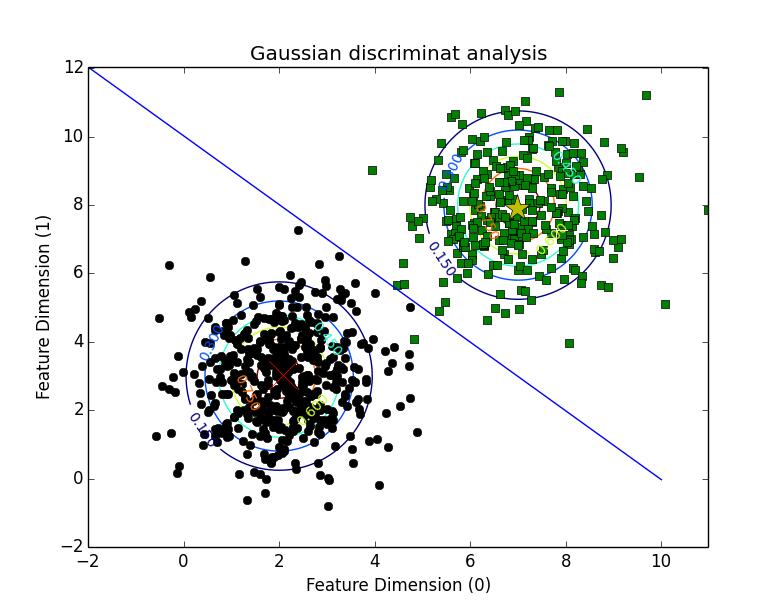
以上这篇python实现高斯判别分析算法的例子就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python求解正态分布置信区间教程
正态分布和置信区间 正态分布(Normal Distribution)又叫高斯分布,是一种非常重要的概率分布.其概率密度函数的数学表达如下: 置信区间是对该区间能包含未知参数的可置信的程度的描述. 使用SciPy求解置信区间 import numpy as np import matplotlib.pyplot as plt from scipy import stats N = 10000 x = np.random.normal(0, 1, N) # ddof取值为1是因为在统计学中样本的标
-
python 多维高斯分布数据生成方式
我就废话不多说了,直接上代码吧! import numpy as np import matplotlib.pyplot as plt def gen_clusters(): mean1 = [0,0] cov1 = [[1,0],[0,10]] data = np.random.multivariate_normal(mean1,cov1,100) mean2 = [10,10] cov2 = [[10,0],[0,1]] data = np.append(data, np.random.mu
-
python实现高斯(Gauss)迭代法的例子
我就废话不多说了,直接上代码大家一起看吧! #Gauss迭代法 输入系数矩阵mx.值矩阵mr.迭代次数n(以list模拟矩阵 行优先) def Gauss(mx,mr,n=100): if len(mx) == len(mr): #若mx和mr长度相等则开始迭代 否则方程无解 x = [] #迭代初值 初始化为单行全0矩阵 for i in range(len(mr)): x.append([0]) count = 0 #迭代次数计数 while count < n: for i in rang
-
在python中画正态分布图像的实例
1.正态分布简介 正态分布(normal distribtution)又叫做高斯分布(Gaussian distribution),是一个非常重要也非常常见的连续概率分布.正态分布大家也都非常熟悉,下面做一些简单的介绍. 假设随机变量XX服从一个位置参数为μμ.尺度参数为σσ的正态分布,则可以记为: 而概率密度函数为 2.在python中画正态分布直方图 先直接上代码 import numpy as np import matplotlib.mlab as mlab import matplot
-

Python数据可视化正态分布简单分析及实现代码
Python说来简单也简单,但是也不简单,尤其是再跟高数结合起来的时候... 正态分布(Normaldistribution),也称"常态分布",又名高斯分布(Gaussiandistribution),最早由A.棣莫弗在求二项分布的渐近公式中得到.C.F.高斯在研究测量误差时从另一个角度导出了它.P.S.拉普拉斯和高斯研究了它的性质.是一个在数学.物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力. 正态曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此人
-
Python使用numpy产生正态分布随机数的向量或矩阵操作示例
本文实例讲述了Python使用numpy产生正态分布随机数的向量或矩阵操作.分享给大家供大家参考,具体如下: 简单来说,正态分布(Normal distribution)又名高斯分布(Gaussian distribution),是一个在数学.物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力.一般的正态分布可以通过标准正态分布配合数学期望向量和协方差矩阵得到.如下代码,可以得到满足一维和二维正态分布的样本. 示例1(一维正态分布): # coding=utf-8 '''
-
python实现高斯判别分析算法的例子
高斯判别分析算法(Gaussian discriminat analysis) 高斯判别算法是一个典型的生成学习算法(关于生成学习算法可以参考我的另外一篇博客).在这个算法中,我们假设p(x|y)p(x|y)服从多元正态分布. 注:在判别学习算法中,我们假设p(y|x)p(y|x)服从一维正态分布,这个很好类比,因为在模型中输入数据XX通常是拥有很多维度的,所以对于XX的条件概率建模时要取多维正态分布. 多元正态分布 多元正态分布也叫多元高斯分布,这个分布的两个参数分别是平均向量μ∈Rnμ∈Rn
-
Python语言描述KNN算法与Kd树
最近邻法和k-近邻法 下面图片中只有三种豆,有三个豆是未知的种类,如何判定他们的种类? 提供一种思路,即:未知的豆离哪种豆最近就认为未知豆和该豆是同一种类.由此,我们引出最近邻算法的定义:为了判定未知样本的类别,以全部训练样本作为代表点,计算未知样本与所有训练样本的距离,并以最近邻者的类别作为决策未知样本类别的唯一依据.但是,最近邻算法明显是存在缺陷的,比如下面的例子:有一个未知形状(图中绿色的圆点),如何判断它是什么形状? 显然,最近邻算法的缺陷--对噪声数据过于敏感,为了解决这个问题,我们可
-
python实现K最近邻算法
KNN核心算法函数,具体内容如下 #! /usr/bin/env python3 # -*- coding: utf-8 -*- # fileName : KNNdistance.py # author : zoujiameng@aliyun.com.cn import math def getMaxLocate(target): # 查找target中最大值的locate maxValue = float("-inFinIty") for i in range(len(target)
-
python opencv之SURF算法示例
本文介绍了python opencv之SURF算法示例,分享给大家,具体如下: 目标: SURF算法基础 opencv总SURF算法的使用 原理: 上节课使用了SIFT算法,当时这种算法效率不高,需要更快速的算法.在06年有人提出了SURF算法"加速稳定特征",从名字上来看,他是SIFT算法的加速版本. (原文) 在SIFT算法当中使用高斯差分方程(Difference of Gaussian)对高斯拉普拉斯方程( Laplacian of Gaussian)进行近似.然而,SURF使
-
python opencv之SIFT算法示例
本文介绍了python opencv之SIFT算法示例,分享给大家,具体如下: 目标: 学习SIFT算法的概念 学习在图像中查找SIFT关键的和描述符 原理: (原理部分自己找了不少文章,内容中有不少自己理解和整理的东西,为了方便快速理解内容和能够快速理解原理,本文尽量不使用数学公式,仅仅使用文字来描述.本文中有很多引用别人文章的内容,仅供个人记录使用,若有错误,请指正出来,万分感谢) 之前的harris算法和Shi-Tomasi 算法,由于算法原理所致,具有旋转不变性,在目标图片发生旋转时依然
-
python实现决策树分类算法
本文实例为大家分享了python实现决策树分类算法的具体代码,供大家参考,具体内容如下 1.概述 决策树(decision tree)--是一种被广泛使用的分类算法. 相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置 在实际应用中,对于探测式的知识发现,决策树更加适用. 2.算法思想 通俗来说,决策树分类的思想类似于找对象.现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话: 女儿:多大年纪了? 母亲:26. 女儿:长的帅不帅? 母亲:挺帅的. 女儿:收入高不?
-
Python实现线性判别分析(LDA)的MATLAB方式
线性判别分析(linear discriminant analysis),LDA.也称为Fisher线性判别(FLD)是模式识别的经典算法. (1)中心思想:将高维的样本投影到最佳鉴别矢量空间,来达到抽取分类信息和压缩特种空间维数的效果,投影后保证样本在新的子空间有最大的类间距离和最小的类内距离.也就是说在该空间中有最佳的可分离性. (2)与PCA的不同点:PCA主要是从特征的协方差出发,来找到比较好的投影方式,最后需要保留的特征维数可以自己选择.但是LDA更多的是考虑了类别信息,即希望投影后不
-
python实现mean-shift聚类算法
本文实例为大家分享了python实现mean-shift聚类算法的具体代码,供大家参考,具体内容如下 1.新建MeanShift.py文件 import numpy as np # 定义 预先设定 的阈值 STOP_THRESHOLD = 1e-4 CLUSTER_THRESHOLD = 1e-1 # 定义度量函数 def distance(a, b): return np.linalg.norm(np.array(a) - np.array(b)) # 定义高斯核函数 def gaussian
-
Python几种常见算法汇总
1.选择排序 选择排序是一种简单直观的排序算法.它的原理是这样:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的后面,以此类推,直到所有元素均排序完毕.算法实现如下: #找到最小的元素def FindSmall(list): min=list[0] for i in range(len(list)): if list[i]<min: min=list[i] return min #选择排序def Select_