Python爬虫实战之爬取携程评论
一、分析数据源
这里的数据源是指html网页?还是Aajx异步。对于爬虫初学者来说,可能不知道怎么判断,这里辰哥也手把手过一遍。
提示:以下操作均不需要登录(当然登录也可以)
咱们先在浏览器里面搜索携程,然后在携程里面任意搜索一个景点:长隆野生动物世界,这里就以长隆野生动物世界为例,讲解如何去爬取携程评论数据。
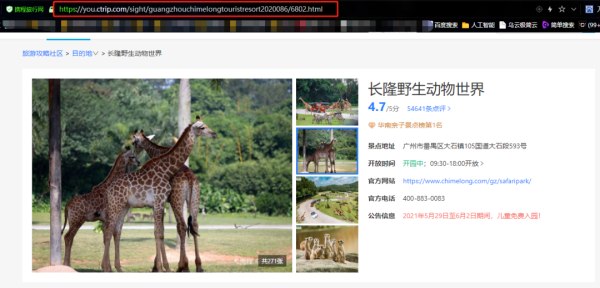
页面下方则是评论数据
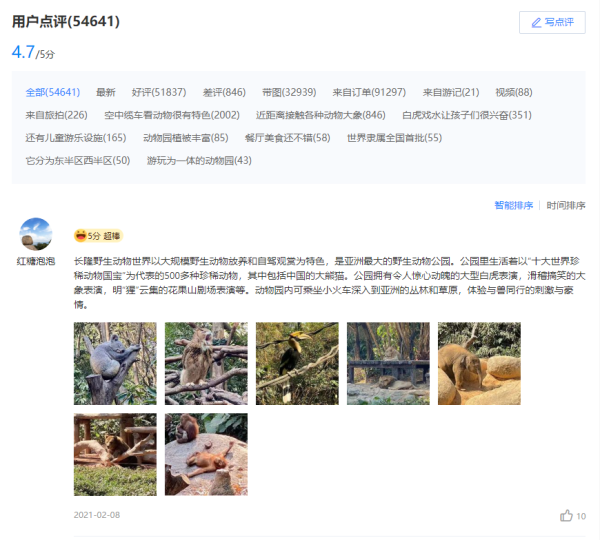

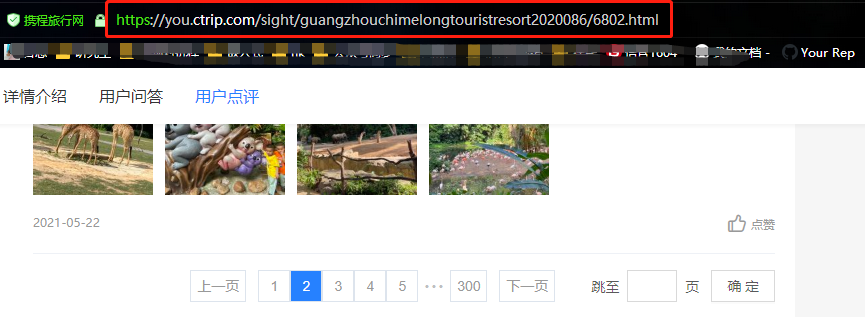
从上面两张图可以看出,点击评论下一页,浏览器的链接没有变化,说明数据是Ajax异步请求。因此我们就找到了数据是异步加载过来的,这时候需要去network里面是查看数据包。
二、分析数据包
在network中找到下面这个数据包

查看Preview里面的内容(请求返回内容)
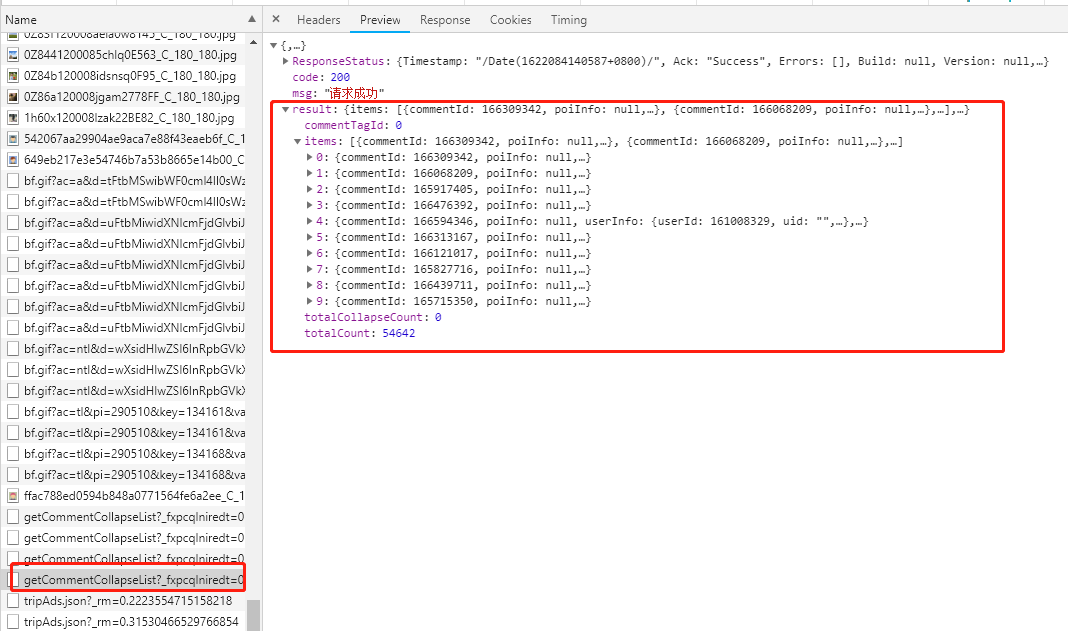
可以看到数据已经请求到了,下面看一下数据是否是正确的(和网页内容一致)。
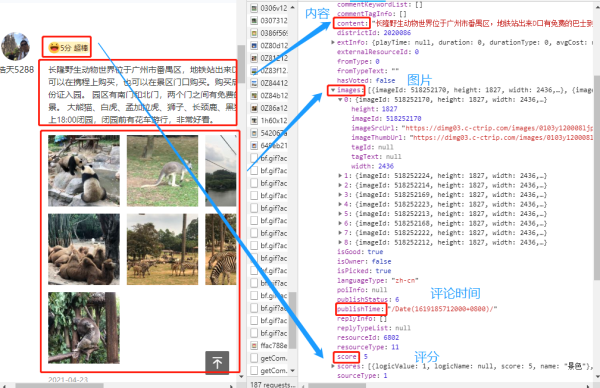
ok,没问题之后,下面开始编写Python程序去请求数据。
1.请求地址

可以获取到请求链接和请求方式。

这里请求不用添加请求头header也是可以的。其中postUrl是请求链接,data_1是请求参数。
2.请求参数
在network里可以看到请求参数
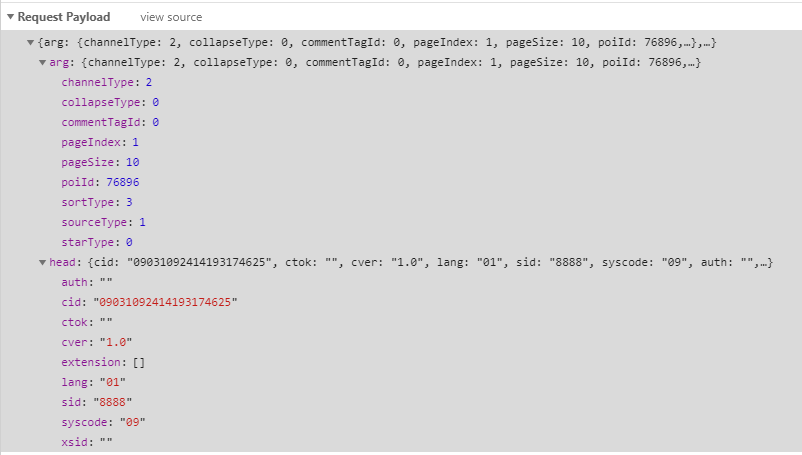
在程序中的构建如下:
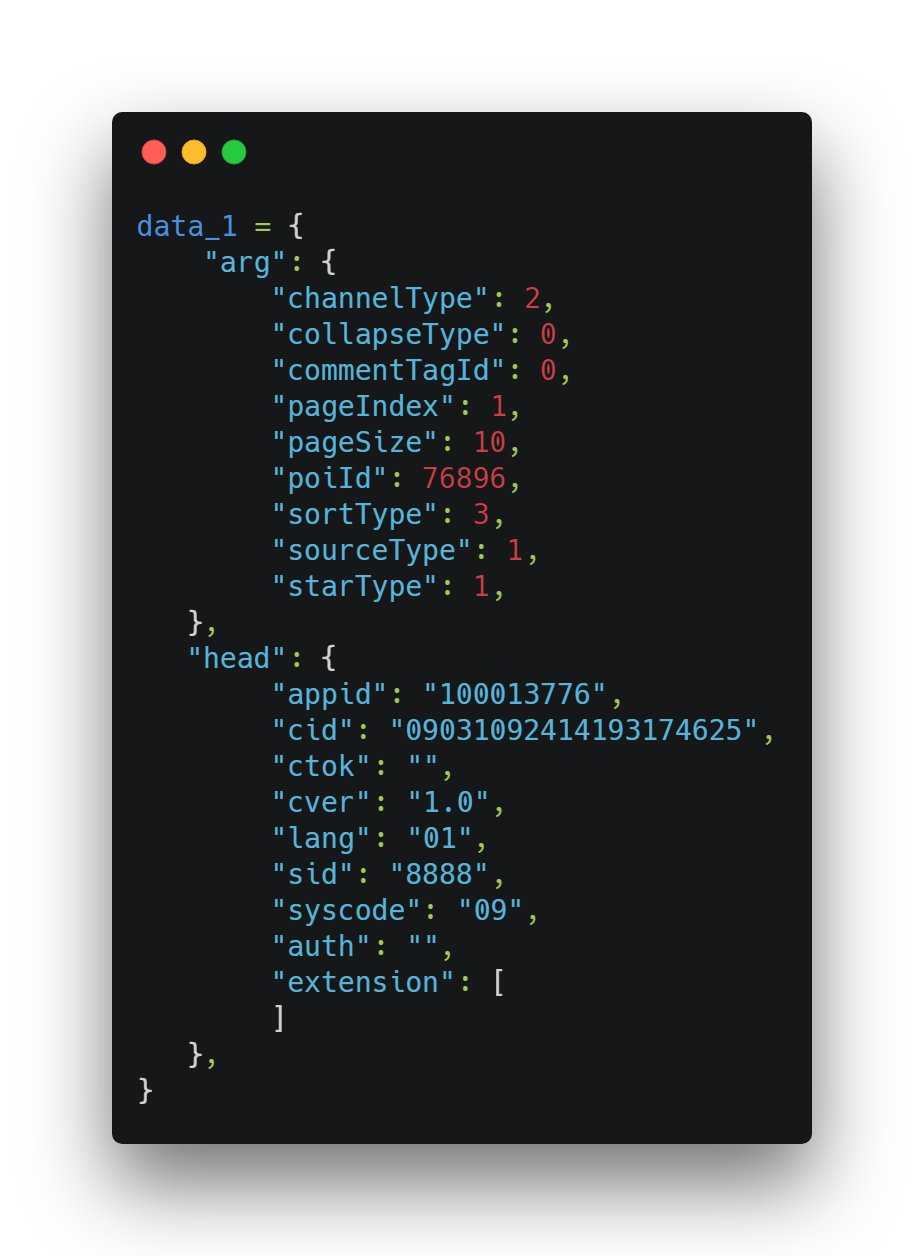
其中需要关注的是arg中的pageIndex(页数),pageSize(每页条数)。

最终结果如下:

该景点的评论就可以成功爬取下来了。
三、采集全部评论
上面只是采集了第一页的评论数据,通过改变arg中的pageIndex(页数),就可以遍历爬取全部的评论。

比如这个景点一共是300页。现在把循环给加上
最终的完整代码如下:
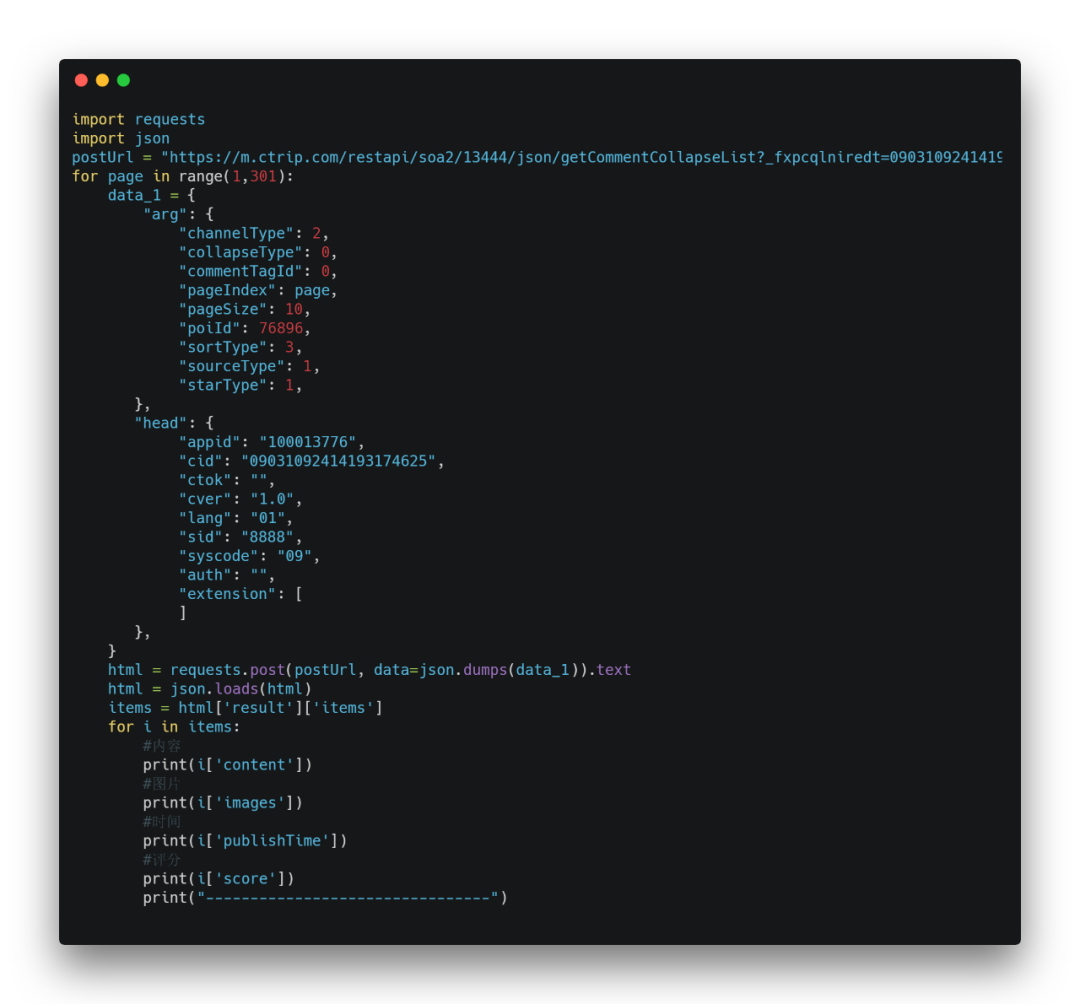
到此这篇关于Python爬虫实战之爬取携程评论的文章就介绍到这了,更多相关Python爬取携程评论内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python爬取豆瓣电影TOP250数据
在执行程序前,先在MySQL中创建一个数据库"pachong". import pymysql import requests import re #获取资源并下载 def resp(listURL): #连接数据库 conn = pymysql.connect( host = '127.0.0.1', port = 3306, user = 'root', password = '******', #数据库密码请根据自身实际密码输入 database = 'pachong', cha
-
python 爬取影视网站下载链接
项目地址: https://github.com/GriffinLewis2001/Python_movie_links_scraper 运行效果 导入模块 import requests,re from requests.cookies import RequestsCookieJar from fake_useragent import UserAgent import os,pickle,threading,time import concurrent.futures from goto
-
Python爬虫之爬取最新更新的小说网站
一.引言 这个五一假期自驾回老家乡下,家里没装宽带,用手机热点方式访问网络.这次回去感觉4G信号没有以前好,通过百度查找小说最新更新并打开小说网站很慢,有时要打开好多个网页才能找到可以正常打开的最新更新.为了躲懒,老猿决定利用Python爬虫知识,写个简单应用自己查找小说最新更新并访问最快的网站,花了点时间研究了一下相关报文,经过近一天时间研究和编写,终于搞定,下面就来介绍一下整个过程. 二.关于相关访问请求及应答报文 2.1.百度搜索请求 我们通过百度网页的搜索框进行搜索时,提交的url请求是
-
教你怎么用python爬取爱奇艺热门电影
一.首先我们要找到目标 找到目标先分析一下网页(url:https://list.iqiyi.com/www/1/-------------11-1-1-iqiyi–.html),很幸运这个只有一个网页,不需要翻页. 二.F12查看网页源代码 找到目标,分析如何获取需要的数据.找到href与电影名称 三.进行代码实现,获取想要资源. ''' 爬取爱奇艺电影与地址路径 操作步骤 1,获取到url内容 2,css选择其选择内容 3,保存自己需要数据 ''' #导入爬虫需要的包 import requ
-
python 爬取吉首大学网站成绩单
项目地址: https://github.com/chen0495/pythonCrawlerForJSU 环境 python 3.5即以上 request.BeautifulSoup.numpy.pandas. 安装BeautifulSoup使用命令pip install BeautifulSoup4 配置及使用 登陆学校成绩单查询网站,修改cookie. 按F12后按Ctrl+R刷新一下,获取cookie的方法见下图: 修改爬虫url为自己的成绩单网址. 运行src/main.py文件即可在
-
python爬取链家二手房的数据
一.查找数据所在位置: 打开链家官网,进入二手房页面,选取某个城市,可以看到该城市房源总数以及房源列表数据. 二.确定数据存放位置: 某些网站的数据是存放在html中,而有些却api接口,甚至有些加密在js中,还好链家的房源数据是存放到html中: 三.获取html数据: 通过requests请求页面,获取每页的html数据 # 爬取的url,默认爬取的南京的链家房产信息 url = 'https://nj.lianjia.com/ershoufang/pg{}/'.format(page) #
-
Python爬虫之爬取我爱我家二手房数据
一.问题说明 首先,运行下述代码,复现问题: # -*-coding:utf-8-*- import re import requests from bs4 import BeautifulSoup cookie = 'PHPSESSID=aivms4ufg15sbrj0qgboo3c6gj; HMF_CI=4d8ff20092e9832daed8fe5eb0475663812603504e007aca93e6630c00b84dc207; _ga=GA1.2.556271139.1620784
-
python趣味挑战之爬取天气与微博热搜并自动发给微信好友
一.系统环境 1.python 3.8.2 2.webdriver(用于驱动edge) 3.微信电脑版 4.windows10 二.爬取中国天气网 因为中国天气网的网页是动态生成的,所以不能直接爬取到数据,需要先使用webdriver打开网页并渲染完成,然后保存网页源代码,使用beautifulsoup分析数据.爬取的数据包括实时温度.最高温度与最低温度.污染状况.风向和湿度.紫外线状况.穿衣指南八项数据. def getZZWeatherAndSendMsg(): HTML1='http://
-
python 爬取京东指定商品评论并进行情感分析
项目地址 https://github.com/DA1YAYUAN/JD-comments-sentiment-analysis 爬取京东商城中指定商品下的用户评论,对数据预处理后基于SnowNLP的sentiment模块对文本进行情感分析. 运行环境 Mac OS X Python3.7 requirements.txt Pycharm 运行方法 数据爬取(jd.comment.py) 启动jd_comment.py,建议修改jd_comment.py中变量user-agent为自己浏览器用户
-
python结合多线程爬取英雄联盟皮肤(原理分析)
1.什么是多线程? 多线程是为了同步完成多项任务,不是为了提高运行效率,而是为了提高资源使用效率来提高系统的效率.线程是在同一时间需要完成多项任务的时候实现的. 为什么要使用多线程 线程在程序中是独立的.并发的执行流.与分隔的进程相比,进程中线程之间的隔离程度要小,它们共享内存.文件句柄和其他进程应有的状态. 因为线程的划分尺度小于进程,使得多线程程序的并发性高.进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率. 线程比进程具有更高的性能,这是由于同一个进程