详解python使用金山词霸的翻译功能(调试工具断点的使用)
今天试着用python获取金山词霸的翻译功能,链接在这里:
ICIBA传送门
打开之后,界面是这样的,还是比较干净的。
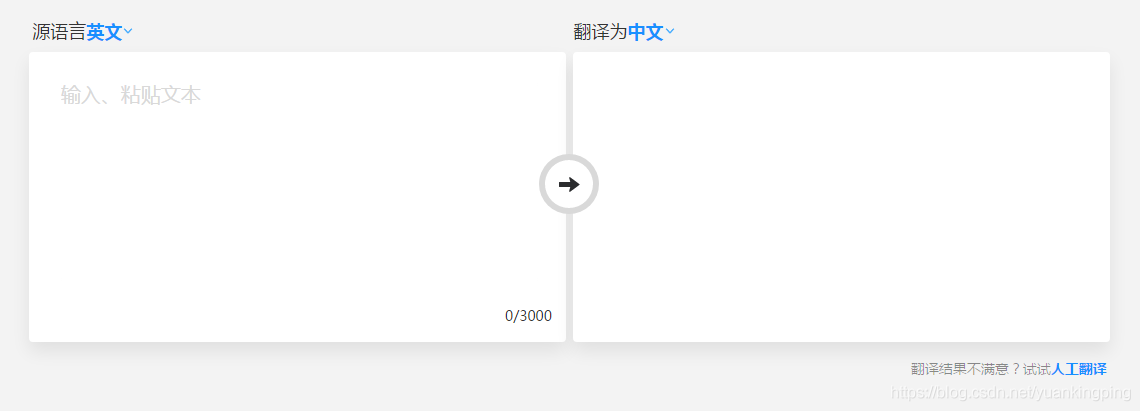
按F12,打开调试工具,选择Network,找到XHR

这里就是查看网络传输的内容。XHR就是不刷新页面的网络传输,就是常说的ajax(阿贾克斯,像是希腊神话里的名字……)。
然后我们在翻译窗口写点儿内容,然后点翻译
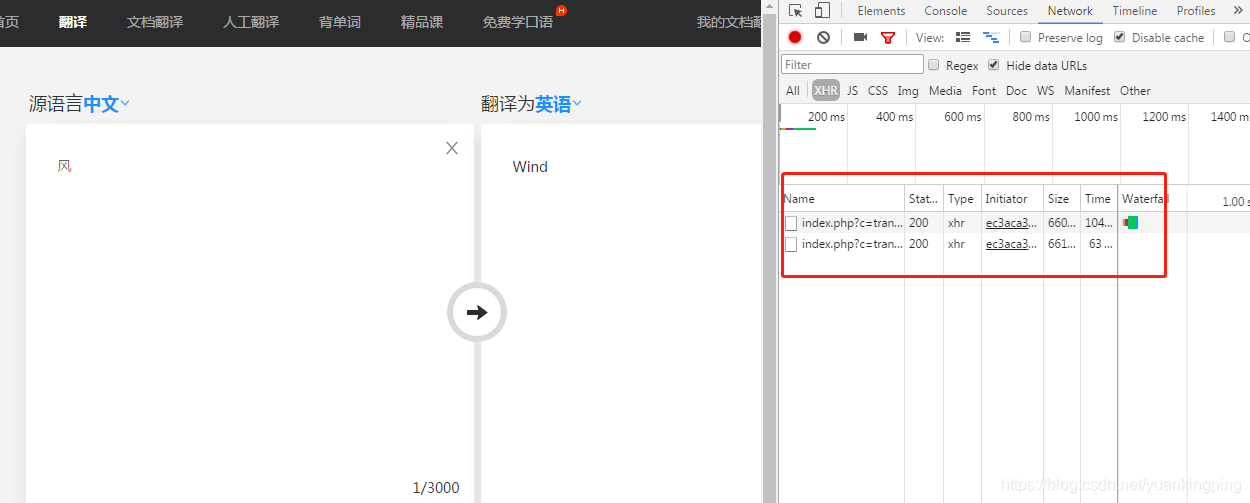
看,左边的页面出现了翻译结果,右边调试窗口出现了两条数据传输。
两条?那我们选哪条呢?点开看看……
哦,天哪~两条都是一样的,那我们随便选一条就可以了。
点一下,看后面的内容

好了,首先看到的是Request URL。嗯……就是我们要的URL了。
先记下来……
(你是用复制、粘贴,还是键盘上手打?难道是抄在本子上?)
下面的Post也要记住,这是请求类型,别用成get了。
再往下,
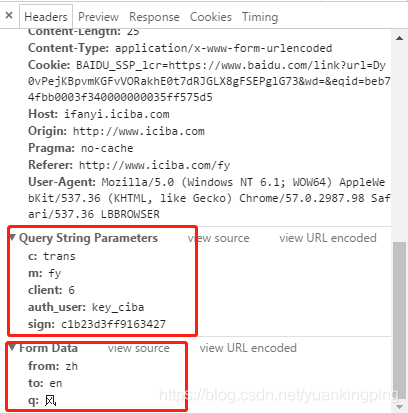
上面那部分是不是很熟悉?对了,就是URL链接里的东西。不管他,URL里有了就好了。
下面的部分,就是要提交的数据了。
把这部分转成字典格式:
data = {
'from':'zh'
'to':'en'
'q':'风'
}
from和to这就好理解了,就是从中文到英文嘛。好,咱们不管他是中是英,都给成“auto”,让他自己去猜去……
q就是我们查的词语,那我们就用变量q表示吧,这样改后的字典就是:
data = {
'from':'auto'
'to':'auto'
'q':q
}
提交的数据有了,那我们把请求头建立起来吧
再让我们回到调试工具里去看下
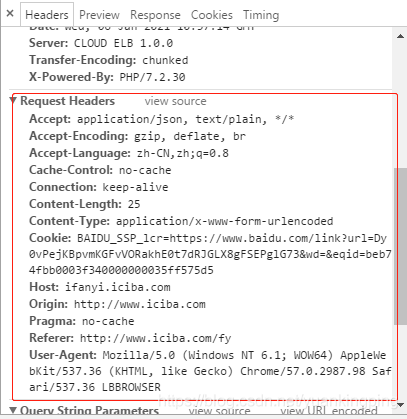
headers就是请求头部,那里面这么多东西,我们要用什么呢?
当然**User-Agent:**不能少了
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER'
}
好了,我们需要的东西都齐了,那就开始吧:
首先是引入文件,
import requests
我们再到调试工具里看下返回值,看下获取的内容是什么格式的。一般返回值有json的,也有html的。
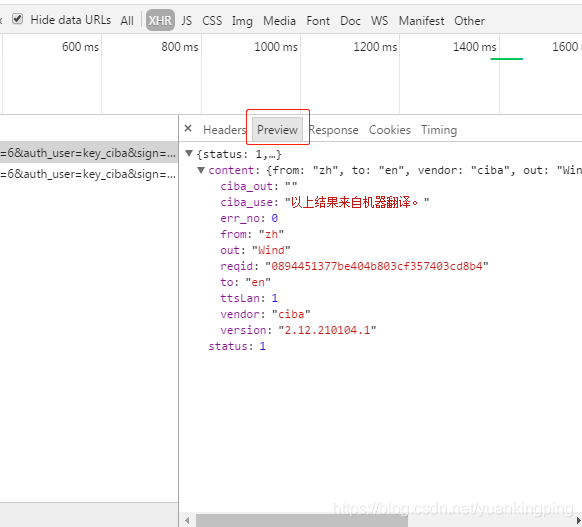
这里把返回的结果给你了,这就是json的数据格式。
我们用q来获取输入的文本
q = input('请输入要翻译的内容:')
整理后就是这样了:
import requests
q = input('请输入要翻译的内容:')
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = 'https://ifanyi.iciba.com/index.php?c=trans&m=fy&client=6&auth_user=key_ciba&sign=c1b23d3ff9163427'
data = {
'from':'auto',
'to':'auto',
'q':q
}
res = requests.post(url=url,headers=headers,data=data).json()
print(res)
好了,运行一遍试下

我们输入要翻译的内容,

不错,结果返回了,是json格式的数据,里面有我们需要的结果。
再换个词试下……

这是什么情况?为什么错了?
好吧,我们在浏览器里试下
点开看一下……
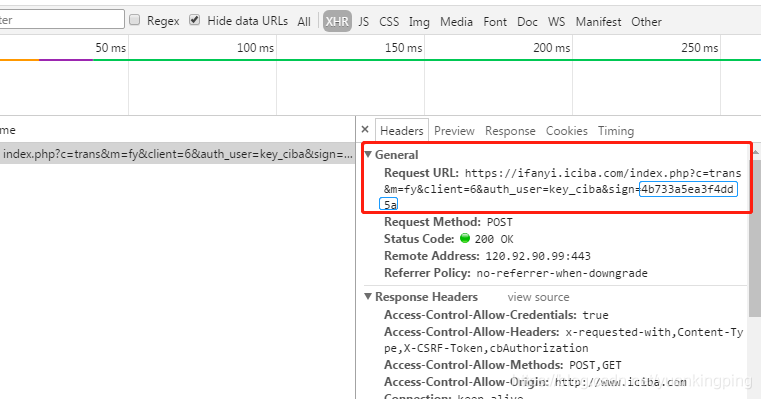
发现了吗?sign不一样……
前一个是什么?
sign=c1b23d3ff9163427'
这个是
sign=4b733a5ea3f4dd5a
sign是动态生成的,怎么办?找生成方法!
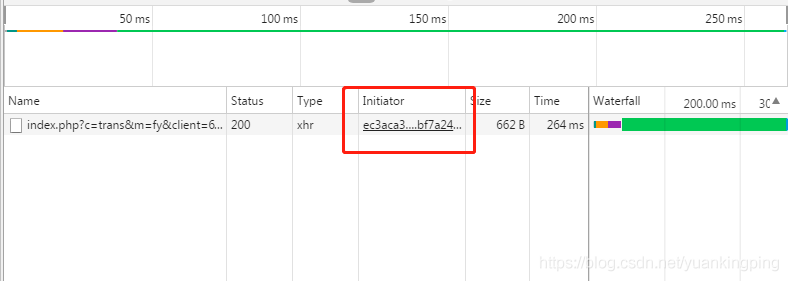
我们看这里……
这是运行的代码的位置,我们点进去……

上面老长一行了,怎么办?
看左下角的大括号了吗?点下就会有惊喜!

好棒!已经排列整齐了……
下面就是在这里查找sign的位置了,Ctrl+F,开始搜索

23个结果,一个个看过去……找找哪个比较像加密的……
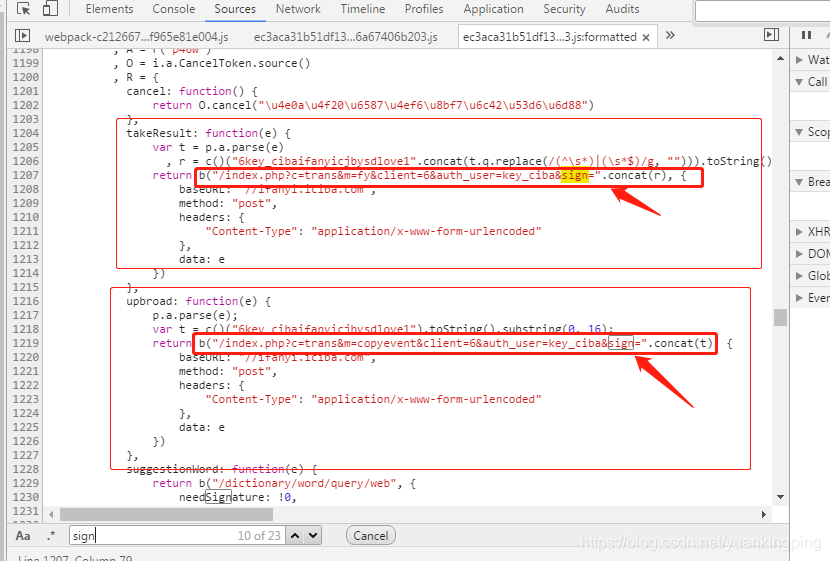
看,这里是对URL进行拼接的。上面就是sign的加密方式
sign后面拼接的是个r,r就是上面的一行算出来的,
r = c()("6key_cibaifanyicjbysdlove1".concat(t.q.replace(/(^\s*)|(\s*$)/g, ""))).toString().substring(0, 16);
你看,这个r就是用一系列字符串拼接起来的,都有什么呢?
1、"6key_cibaifanyicjbysdlove1" 2、t.q.replace(/(^\s*)|(\s*$)/g, "")
第一个简单,就是一串固定的字符串
第二个呢?t.q是什么鬼?我们来找一下……
好,我们在这一行打个断点,就是在前面的行号上点一下。
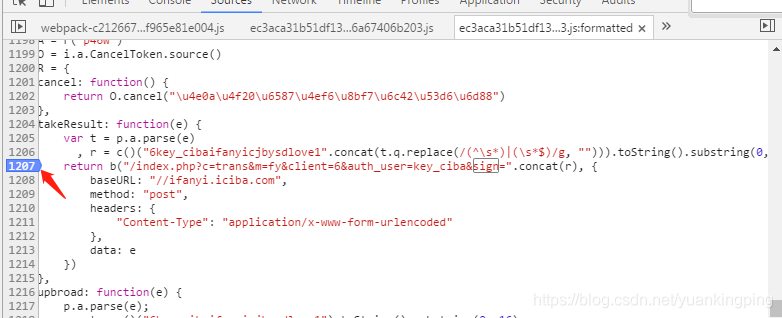
看见蓝色的标签了吧,这就是个断点。在运行的时候,运行到这里就会停止,然后把当前状态给你报出来。好了,断点有了,
咱们让点下翻译,让他运行下看看
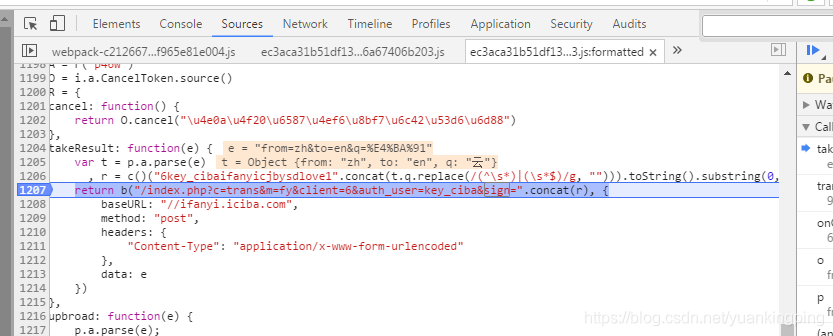
运行到断点时,停止了,并将当前的参数显示了出来。把鼠标放在q上……

所得寺内!原来就是我们要查的词哦……
然后就把他们拼在一起……
"6key_cibaifanyicjbysdlove1"+"云"
可是c()又是什么鬼?好吧,我们看下加密后的结果是什么
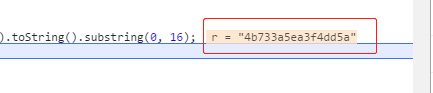
这个字符串是不是很眼熟?很像md5不是吗?
好的,那我们找一个md5加密工具试下,把加密前的字符串拼接起来
"6key_cibaifanyicjbysdlove1云"
然后我们放到md5加密工具里,看结果
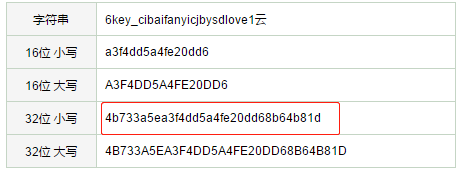
看这里……

是不是这个?32位加密后的前16位!
我们再验证一下,换一个词查下,我们查下“雨”
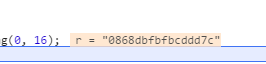
我把字符串拼接好
"6key_cibaifanyicjbysdlove1雨"
放到md5工具里看下

是不是一样的?好了,我们知道sign的加密规则了,那我们自己就把这个sign加密。
要用到md5,我们就要引用新的文件了
import hashlib
至于md5的用法,可以看下:
import hashlib
hash = hashlib.md5()#md5对象,md5不能反解,但是加密是固定的,就是关系是一一对应,所以有缺陷,可以被对撞出来
hash.update(bytes('admin',encoding='utf-8'))#要对哪个字符串进行加密,就放这里
print(hash.hexdigest())#拿到加密字符串
# hash2=hashlib.sha384()#不同算法,hashlib很多加密算法
# hash2.update(bytes('admin',encoding='utf-8'))
# print(hash.hexdigest())
hash3 = hashlib.md5(bytes('abd',encoding='utf-8'))
''' 如果没有参数,所有md5遵守一个规则,生成同一个对应关系,如果加了参数,
就是在原先加密的基础上再加密一层,这样的话参数只有自己知道,防止被撞库,
因为别人永远拿不到这个参数
'''
hash3.update(bytes('admin',encoding='utf-8'))
print(hash3.hexdigest())
然后我们把sign的加密写一下
sign = (hashlib.md5(("6key_cibaifanyicjbysdlove1"+q).encode('utf-8')).hexdigest())[0:16]
再把sign拼接到url上
sign = (hashlib.md5(("6key_cibaifanyicjbysdlove1"+q).encode('utf-8')).hexdigest())[0:16]
url = 'https://ifanyi.iciba.com/index.php?c=trans&m=fy&client=6&auth_user=key_ciba'
url = url+'&sign='+sign
然后我们运行下看看

一切OK,没问题!
最后我们从返回的json数据里提取出我们要的那部分
rt= res['content']['out']
print('翻译完成:'+rt)
全部代码就是
import requests
import hashlib
q = input('请输入要翻译的内容:')
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36'
}
url = 'https://ifanyi.iciba.com/index.php?c=trans&m=fy&client=6&auth_user=key_ciba'
sign = (hashlib.md5(("6key_cibaifanyicjbysdlove1"+q).encode('utf-8')).hexdigest())[0:16]
url = url+'&sign='+sign
data = {
'from':'auto',
'to':'auto',
'q':q
}
res = requests.post(url=url,headers=headers,data=data).json()
rt= res['content']['out']
print('翻译完成:'+rt)
运行看下:
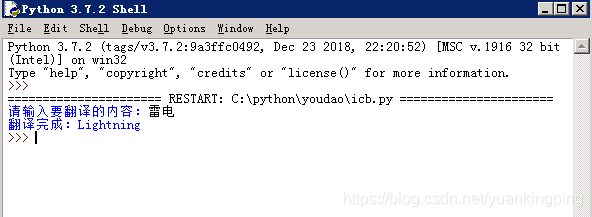
OK,翻译完工!
总结:
post请求的所有data都是已知的,只有url里有一个动态的sign。麻烦的地方就是查找sign的加密方式。
一般情况下,大部分sign的加密都是使用的md5,你只要找到用来加密的字符串就可以了。
使用断点来跟踪运行过程是比较常用的手段,但也不是全都能找到结果的。
到此这篇关于详解python使用金山词霸的翻译功能(调试工具断点的使用)的文章就介绍到这了,更多相关python金山词霸的翻译内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬虫实现百度翻译功能过程详解
首先,需要简单的了解一下爬虫,尽可能简单快速的上手,其次,需要了解的是百度的API的接口,搞定这个之后,最后,按照官方给出的demo,然后写自己的一个小程序 打开浏览器 F12 打开百度翻译网页源代码: 我们可以轻松的找到百度翻译的请求接口为:http://fanyi.baidu.com/sug 然后我们可以从方法为POST的请求中找到参数为:kw:job(job是输入翻译的内容) 下面是代码部分: from urllib import request,parse import json def
-

基于python实现百度翻译功能
运行环境: python 3.6.0 今天处于练习的目的,就用 python 写了一个百度翻译,是如何做到的呢,其实呢就是拿到接口,通过这个接口去访问,不过中间确实是出现了点问题,不过都解决掉了 先晾图后晾代码 运行结果: 代码: # -*- coding: utf-8 -*- """ 功能:百度翻译 注意事项:中英文自动切换 """ import requests import re class Baidu_Translate(object):
-
python实现在线翻译功能
对于需要大量翻译的数据,人工翻译太慢,此时需要使用软件进行批量翻译. 1.使用360的翻译 def fanyi_word_cn(string): url="https://fanyi.so.com/index/search" #db_path = './db/tasks.db' Form_Data= {} #这里输入要翻译的英文 Form_Data['query']= string Form_Data['eng']= '1' #用urlencode把字典变成字符串,#服务器不接受字典,
-
Python 实现的 Google 批量翻译功能
首先声明,没有什么不良动机,因为经常会用 translate.google.cn,就想着用 Python 模拟网页提交实现文档的批量翻译.据说有 API,可是要收费. 生成 Token Google 为防爬虫而生成 token 的代码是 Javascript 的,且是根据网站的 TKK 值和提交的文本动态生成.更新规律未知,只好定时去取一下了. 网上能找到的 Python 代码大部分是去调用 PyExecJS 库,先不说执行效率的高低(大概是差一个数量级),首先是舍近求远,不纯粹,本人不喜欢.
-
使用Python3中的gettext模块翻译Python源码以支持多语言
你写了一个Python 3程序,还想要它适用于其他语言.你能复制全部代码库,然后刻意地检查每个.py文件,替换掉所有找到的文本字符串.但这意味着你有两份你代码的独立副本,每当你要做出个改动或修复个bug,你的工作量会加倍.而且如果你想要程序还适用于其他语言,就更糟了. 幸运的是,Python给了一个解决办法,就是用gettext模块. 一个Hack解法 你应该把你自己的解决办法统一改变.例如,你可以把你程序中的每个字符串替换为一个函数调用(函数名简单些,比如像_()一样),这会返回被翻译为该正确
-
python自动翻译实现方法
本文实例讲述了python自动翻译实现方法.分享给大家供大家参考,具体如下: 以前学过python的基础,一般也没用过.后来有一个参数表需要中英文.想了一下,还是用python做吧.调用的百度翻译接口,经历了乱码.模块不全等问题.一般google,一边做的.分享一下. #encoding=utf-8 ## eagle_91@sina.com ## created 2014-07-22 import urllib import urllib2 import MySQLdb import json
-
详解python使用金山词霸的翻译功能(调试工具断点的使用)
今天试着用python获取金山词霸的翻译功能,链接在这里: ICIBA传送门 打开之后,界面是这样的,还是比较干净的. 按F12,打开调试工具,选择Network,找到XHR 这里就是查看网络传输的内容.XHR就是不刷新页面的网络传输,就是常说的ajax(阿贾克斯,像是希腊神话里的名字--). 然后我们在翻译窗口写点儿内容,然后点翻译 看,左边的页面出现了翻译结果,右边调试窗口出现了两条数据传输. 两条?那我们选哪条呢?点开看看-- 哦,天哪~两条都是一样的,那我们随便选一条就可以了. 点一下,
-
详解python里使用正则表达式的全匹配功能
详解python里使用正则表达式的全匹配功能 python中很多匹配,比如搜索任意位置的search()函数,搜索边界的match()函数,现在还需要学习一个全匹配函数,就是搜索的字符与内容全部匹配,它就是fullmatch()函数. 例子如下: #python 3.6 #蔡军生 #http://blog.csdn.net/caimouse/article/details/51749579 # import re text = 'This is some text -- with punctua
-
详解Python 3.10 中的新功能和变化
随着最后一个alpha版发布,Python 3.10 的功能更改全面敲定! 现在,正是体验Python 3.10 新功能的理想时间!正如标题所言,本文将给大家分享Python 3.10中所有重要的功能和更改. 新功能1:联合运算符 在过去, |符号用于 "算术或"运算,例如: print(0 | 0) print(0 | 1) print({1, 2} | {2, 3}) 输出: 0 1 {1, 2, 3} 在Python 3.10中, |符号有的新语法,可以表示x类型 或 Y类型,以
-
详解Python结合Genetic Algorithm算法破解网易易盾拼图验证
首先看一下目标的验证形态是什么样子的 是一种通过验证推理的验证方式,用来防人机破解的确是很有效果,但是,But,这里面已经会有一些破绽,比如: (以上是原图和二值化之后的结果) (这是正常图片) 像划红线的这些地方,可以看到有明显的突变,并且二值化之后边缘趋于直线,但是正常图像是不会有这种这么明显的突变现象. 初识潘多拉 后来,我去翻阅了机器视觉的相关文章和论文,发现了一个牛逼的算法,这个算法就是——Genetic Algorithm遗传算法,最贴心的的是,作者利用这个算法实现了一个功能,“拼图
-
详解Python文本操作相关模块
详解Python文本操作相关模块 linecache--通过使用缓存在内部尝试优化以达到高效从任何文件中读出任何行. 主要方法: linecache.getline(filename, lineno[, module_globals]):获取指定行的内容 linecache.clearcache():清除缓存 linecache.checkcache([filename]):检查缓存的有效性 dircache--定义了一个函数,使用缓存读取目录列表.使用目录的mtime来实现缓存失效.此外还定义
-
详解Python自建logging模块
简单使用 最开始,我们用最短的代码体验一下logging的基本功能. import logging logger = logging.getLogger() logging.basicConfig() logger.setLevel('DEBUG') logger.debug('logsomething') #输出 out>>DEBG:root:logsomething 第一步,通过logging.getLogger函数,获取一个loger对象,但这个对象暂时是无法使用的. 第二步,loggi
-
详解python中asyncio模块
一直对asyncio这个库比较感兴趣,毕竟这是官网也非常推荐的一个实现高并发的一个模块,python也是在python 3.4中引入了协程的概念.也通过这次整理更加深刻理解这个模块的使用 asyncio 是干什么的? 异步网络操作并发协程 python3.0时代,标准库里的异步网络模块:select(非常底层) python3.0时代,第三方异步网络库:Tornado python3.4时代,asyncio:支持TCP,子进程 现在的asyncio,有了很多的模块已经在支持:aiohttp,ai
-
详解python中的线程
Python中创建线程有两种方式:函数或者用类来创建线程对象. 函数式:调用 _thread 模块中的start_new_thread()函数来产生新线程. 类:创建threading.Thread的子类来包装一个线程对象. 1.线程的创建 1.1 通过thread类直接创建 import threading import time def foo(n): time.sleep(n) print("foo func:",n) def bar(n): time.sleep(n) prin
-
实例详解Python装饰器与闭包
闭包是Python装饰器的基础.要理解闭包,先要了解Python中的变量作用域规则. 变量作用域规则 首先,在函数中是能访问全局变量的: >>> a = 'global var' >>> def foo(): print(a) >>> foo() global var 然后,在一个嵌套函数中,内层函数能够访问在外层函数中定义的局部变量: >>> def foo(): a = 'free var' def bar(): print(a)
-
详解python statistics模块及函数用法
本节介绍 Python 中的另一个常用模块 -- statistics模块,该模块提供了用于计算数字数据的数理统计量的函数.它包含了很多函数,具体如下表: 名称 描述 mean() 数据的算术平均数("平均数") harmonic_mean() 数据的调和均值 median() 数据的中位数(中间值) median_low() 数据的低中位数 median_high() 数据的高中位数 median_grouped() 分组数据的中位数,即第50个百分点 mode() 离散的或标称的数