关于PostgreSQL 行排序的实例解析
在查询生成输出表之后,也就是在处理完选择列表之后,你还可以对输出表进行排序。
如果没有排序,那么行将以不可预测的顺序返回(实际顺序将取决于扫描和连接规划类型和在磁盘上的顺序,
但是肯定不能依赖这些东西)。确定的顺序只能在明确地使用了排序步骤之后才能保证。
ORDER BY子句用于声明排序顺序:
SELECT _select_list_
FROM _table_expression_
ORDER BY _sort_expression1_ [ASC | DESC] [NULLS { FIRST | LAST }]
[, `_sort_expression2_` [ASC | DESC] [NULLS { FIRST | LAST }] ...]
sort_expression 是任何可用于选择列表的表达式,可以将不同列相加减乘除后排序,例如:
SELECT a, b FROM table1 ORDER BY a + b, c;
如果指定了多个排序表达式,那么仅在前面的表达式排序相等的情况下才使用后面的表达式做进一步排序。
每个表达式都可以跟一个可选的ASC(升序,默认) 或DESC(降序)以设置排序方向。 升序先输出小的数值,这里的"小"是以<操作符的角度定义的。
类似的是,降序是以>操作符来判断的。
NULLS FIRST和NULLS LAST选项可以决定在排序操作中在 non-null 值之前还是之后。
默认情况下,空值大于任何非空值;也就是说,DESC 排序默认是NULLS FIRST,否则为NULLS LAST。
注意,排序选项对于每个排序列是相对独立的。例如ORDER BY x, y DESC 意思是说ORDER BY x ASC, y DESC,
不同于ORDER BY x DESC, y DESC。
一个_sort_expression_也可以是字段名或字段编号,如:
SELECT a + b AS sum, c FROM table1 ORDER BY sum; SELECT a, max(b) FROM table1 GROUP BY a ORDER BY 1;
都按照第一个字段进行排序。
需要注意的是,输出字段名必须是独立的(不允许在表达式中使用)。
比如,下面的语句是错误的:
SELECT a + b AS sum, c FROM table1 ORDER BY sum + c; -- 错误的
这样的限制主要是为了避免歧义。另外,如果某个排序表达式能够同时匹配输出字段名和表表达式中的字段名, 也会导致歧义(此时使用输出字段名)。
当然,这种情况仅在你使用了AS 重命名输出字段并且恰好与其它表的字段同名的时候才会发生。
ORDER BY可以应用于UNION, INTERSECT,EXCEPT 组合的计算结果,
不过在这种情况下,只允许按照字段的名字或编号进行排序,而不允许按照表达式进行排序。
Notes
[1] 事实上,PostgreSQL使用默认的B-tree操作符类 为表达式的数据类型确定ASC和DESC排序顺序。
一般来说,数据类型将被转换为适合于 <和 >操作符进行排序。但是对于用户自定义的数据类型可以不必如此。
补充:postgresql多列综合排序
一、需求
最近做项目遇到一个需求:对数据按照更新时间和创建时间进行综合排序,即对数据的操作时间进行排序,但是数据表中没有操作时间这个字段,需要根据更新时间和创建时间进行处理。
更新时间存在时,按照更新时间排序,更新时间不存在时,使用创建时间排序,最后更新时间和创建时间一起排序。
用数据举例说明:
原始数据:
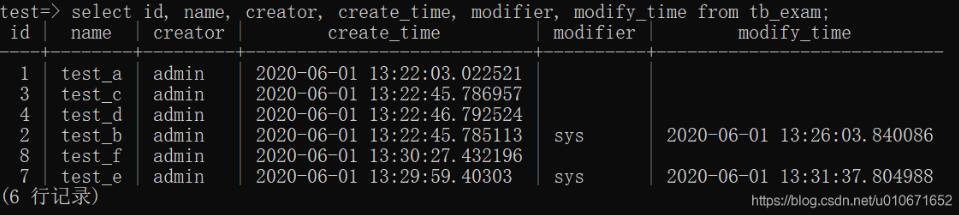
想要的排序结果:

二、postgresql 排序语法
SELECT column_list
FROM table_name
ORDER BY sort_expression1 [ASC | DESC] [NULLS { FIRST | LAST }]
[, `sort_expression2` [ASC | DESC] [NULLS { FIRST | LAST }] ...]
说明:
sort_expression 可以是列名,也可以是列的表达式.如可以将不同列相加后排序:
SELECT a, b FROM table1 ORDER BY a + b, c;
ASC | DESC 是可选的,按升序或者降序排列结果集。默认是 ASC。
NULLS FIRST 和 NULLS LAST 选项可以决定在排序操作中在 null 值之前还是之后。默认情况下,空值大于任何非空值;也就是说,DESC 排序默认是 NULLS FIRST,否则为 NULLS LAST。
三、使用排序 SQL 尝试获取得到想要的排序结果
先按照 modify_time 和 create_time 列降序排列
sql:
select id, name, creator, create_time, modifier, modify_time from tb_exam order by modify_time desc, create_time desc;
运行结果:

分析:
从运行结果看出 modify_time 为 null 的数据排列在前,不符合需求。
改变 null 值的位置
sql:
select id, name, creator, create_time, modifier, modify_time from tb_exam order by modify_time desc nulls last, create_time desc;
运行结果:

分析:
modify_time 为 null 的数据虽然在后面了,但排序结果并不符合要求。没有达到修改时间和创建时间综合排序的效果。
由此可见,使用基本的排序语法达不到两列综合排序的效果,可使用 case when 实现自定义排序规则。
自定义排序规则
sql:
select id, name, creator, create_time, modifier, modify_time from tb_exam order by case when modify_time is null then create_time when modify_time < create_time then create_time else modify_time end desc;
运行结果:
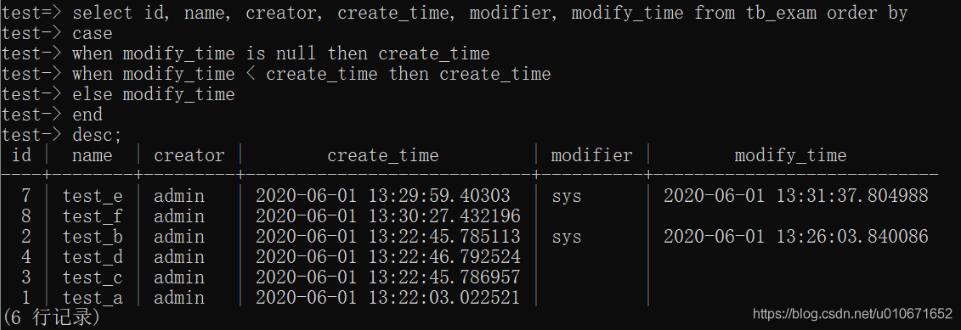
分析:
从运行结果可知,该 sql 的排序结果符合需求,实现了 modify_time 和 create_time 的综合排序。
结论:
可使用 case when 在一定程度上实现自定义排序规则,实现多列数据综合排序。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

解决postgresql无法远程访问的情况
今天刚入手这个数据库玩玩,发现无法通过IP去访问数据库,后面查询原因为,该数据库默认只能通过本地连接,也就是回环地址(127.0.0.1) 解决方案: 1.修改安装目录下的data\pg_hba.conf,在配置文件最后有IPV4和IPV6的配置,新增一行(这里我用的IPV4,开放所有IP) host all all 0.0.0.0/0 md5 说明: 该配置为允许所有IP访问,下面有对应的一些配置示例提供参考 32 -> 192.168.1.1/32 表示必须是来自这个IP地址的访问才合法:
-
浅谈Postgresql默认端口5432你所不知道的一点
关于Postgresql端口5432的定义: 5432端口,已经在IANA(The Internet Assigned Numbers Authority,互联网数字分配机构)注册, 并把该端口唯一分配给Postgres. 这意味着,一台安装了linux OS的服务器,哪怕没有安装过postgresql数据库,也会有这个预留端口. 查看这个预留端口的方法如下: new@newdb-> cat /etc/services |grep 5432 postgres 5432/tcp postgresq
-
postgresql 实现启动、状态查看、关闭
利用psql启动数据库 [postgres@highgo ~]$ pg_ctl start 查看系统中运行的postgres进程 #ps -ef | grep postgres 连接postgresql数据库 #psql -h 127.0.0.1 -d postgres -U postgres 停止postgresql数据库实例 #pg_ctl stop #ps -ef | grep postgres 启动服务器最简单的方法是像下面这样: $ postgres -D /usr/local/pgs
-
PostgreSQL的中文拼音排序案例
前一段时间开发人员咨询,说postgresql里面想根据一个字段做中文的拼音排序,但是不得其解 环境: OS:CentOS 6.3 DB:PostgreSQL 9.2.4 TABLE: tbl_kenyon 场景: postgres=# \d tbl_kenyon Table "public.tbl_kenyon" Column | Type | Modifiers --------+------+--------------- vname | text | --使用排序后的结果,不是
-
Postgresql排序与limit组合场景性能极限优化详解
1 构造测试数据 create table tbl(id int, num int, arr int[]); create index idx_tbl_arr on tbl using gin (arr); create or replace function gen_rand_arr() returns int[] as $$ select array(select (1000*random())::int from generate_series(1,64)); $$ language sq
-
关于PostgreSQL 行排序的实例解析
在查询生成输出表之后,也就是在处理完选择列表之后,你还可以对输出表进行排序. 如果没有排序,那么行将以不可预测的顺序返回(实际顺序将取决于扫描和连接规划类型和在磁盘上的顺序, 但是肯定不能依赖这些东西).确定的顺序只能在明确地使用了排序步骤之后才能保证. ORDER BY子句用于声明排序顺序: SELECT _select_list_ FROM _table_expression_ ORDER BY _sort_expression1_ [ASC | DESC] [NULLS { FIRST |
-
Java并发之串行线程池实例解析
前言 做Android的这两年时间,通过研究Android源码,也会Java并发处理多线程有了自己的一些理解. 那么问题来了,如何实现一个串行的线程池呢? 思路 何为串行线程池呢? 也就是说,我们的Runnable对象应该有个排队的机制,它们顺序从队列尾部进入,并且从队列头部选择Runnable进行执行. 既然我们有了思路,那我们就考虑一下所需要的数据结构? 既然是从队列尾部插入Runnable对象,从队列头部执行Runnable对象,我们自然需要一个队列.Java的SDK已经给我们提供了很好的
-
Python3 pickle对象串行化代码实例解析
1.pickle对象串行化 pickle模块实现了一个算法可以将任意的Python对象转换为一系列字节.这个过程也被称为串行化对象.可以传输或存储表示对象的字节流,然后再重新构造来创建有相同性质的新对象. 1.1 编码和解码字符串中的数据 第一个例子使用dumps()将一个数据结构编码为一个字符串,然后把这个字符串打印到控制台.它使用了一个完全由内置类型构成的数据结构.任何类的实例都可以pickled,如后面的例子所示. import pickle import pprint data = [{
-
linux sort多字段排序实例解析
本文研究的主要是linux sort多字段排序,具体介绍如下. Linux多数发行版自带的sort程序,非常强大,在此只说多字段排序 sort 有个参数-k,可以指定字段,有比较复杂的语法,不在文本范围内. 一下为一段数据(从基因中得到,仅仅作为demo),文件名为 data chr13 3008566 3008677 chr9 3024384 3024515 chr19 3157071 3157172 chr5 3236386 3236476 chr13 3041044 3041191 chr
-
BootStrapTable服务器分页实例解析
项目中经常会使用到表格,数据量大的时候还需要进行分页,项目设计阶段,我选择了bootstrapTable的js插件,个人觉得这个框架非常好用,支持服务器端分页,此篇主要写的主要是关于服务器分页.之前遇到的问题时服务器分页,在服务器端接收的参数为null.查了资料发现少了参数 主要引入js <script type="text/javascript" src="<%=path%>/plugins/bootstrap-table/bootstrap-table.
-
Python建立Map写Excel表实例解析
本文主要研究的是用Python语言建立Map写Excel表的相关代码,具体如下. 前言:我们已经能够很熟练的写Excel表相关的脚本了.大致的操作就是,从数据库中取数据,建立Excel模板,然后根据模板建立一个新的Excel表,把数据库中的数据写入.最后发送邮件.之前的一篇记录博客,写的很标准了.这里我们说点遇到的新问题. 我们之前写类似脚本的时候,有个问题没有考虑过,为什么要建立模板然后再写入数据呢?诶-其实也不算是没考虑过,只是懒没有深究罢了.只求快点完成任务... 这里对这个问题进行思考阐
-
Java编程通过匹配合并数据实例解析(数据预处理)
本文研究的主要是Java编程通过匹配合并数据(数据预处理)的相关内容,具体如下. 数据描述 以下程序是对如下格式的数据进行合并处理. 这个表的每一行表示用户id及用户的特征.其中,一个用户只有一个特征向量,即第一列不会重复. 这张表的第一列,表示用户的id,第二列表示用户所看的电影,第三列表示用户对电影的打分(1-13分),第四列表示用户对电影的打分,但分值范围是1-5分. 问题描述 在做数据预处理时,如何将第二张表添加上用户特征呢?其实,方法很简单,将第二张表的用户id与第一张表的用户id进行
-
通过实例解析java8中的parallelStream
这篇文章主要介绍了通过实例解析java8中的parallelStream,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 about Stream 什么是流? Stream是java8中新增加的一个特性,被java猿统称为流. Stream 不是集合元素,它不是数据结构并不保存数据,它是有关算法和计算的,它更像一个高级版本的 Iterator.原始版本的 Iterator,用户只能显式地一个一个遍历元素并对其执行某些操作:高级版本的 Stream
-
MySQL InnoDB锁类型及锁原理实例解析
目录 锁 共享锁 排他锁 意向锁 记录锁 间隙锁 临键锁 死锁 死锁产生条件 行锁发生死锁 表锁发生死锁 锁的释放 事务阻塞 死锁的避免 锁的日志 行锁的原理 不带任何索引的表 带主键索引的表 带唯一索引的表 结论 1.表必定有索引 2.唯一索引数据行加锁,主键索引同样被锁 锁 锁是用来解决事务对数据的并发访问的问题的.MyISAM支持表锁,InnoDB同时支持表锁和行锁. 表加锁语法: lock tables xxx read; lock tables xxx write; unlock ta
-
Vuejs第六篇之Vuejs与form元素实例解析
本文是小编结合官方文档整理的一篇细致代码更多更全的详细教程,非常适合新手学习,感兴趣的朋友一起看看吧! 资料来于官方文档: http://cn.vuejs.org/guide/forms.html 表单绑定 ①常见绑定方法: [1]文本输入框绑定: [2]textarea绑定(类似[1]): [3]radio选中值绑定: [4]checkbox绑定(自动捆绑数组,无需name): [5]select绑定: [6]select multiple多选选中框绑定: [7]动态绑定(以上不同类型但同一个