Python3 常用数据标准化方法详解
数据标准化是机器学习、数据挖掘中常用的一种方法。包括我自己在做深度学习方面的研究时,数据标准化是最基本的一个步骤。
数据标准化主要是应对特征向量中数据很分散的情况,防止小数据被大数据(绝对值)吞并的情况。
另外,数据标准化也有加速训练,防止梯度爆炸的作用。
下面是从李宏毅教授视频中截下来的两张图。

左图表示未经过数据标准化处理的loss更新函数,右图表示经过数据标准化后的loss更新图。可见经过标准化后的数据更容易迭代到最优点,而且收敛更快。
一、[0, 1] 标准化
[0, 1] 标准化是最基本的一种数据标准化方法,指的是将数据压缩到0~1之间。
标准化公式如下

代码实现
def MaxMinNormalization(x, min, max): """[0,1] normaliaztion""" x = (x - min) / (max - min) return x
或者
def MaxMinNormalization(x): """[0,1] normaliaztion""" x = (x - np.min(x)) / (np.max(x) - np.min(x)) return x
二、Z-score标准化
Z-score标准化是基于数据均值和方差的标准化化方法。标准化后的数据是均值为0,方差为1的正态分布。这种方法要求原始数据的分布可以近似为高斯分布,否则效果会很差。
标准化公式如下

下面,我们看看为什么经过这种标准化方法处理后的数据为是均值为0,方差为1

代码实现
def ZscoreNormalization(x, mean_, std_): """Z-score normaliaztion""" x = (x - mean_) / std_ return x
或者
def ZscoreNormalization(x): """Z-score normaliaztion""" x = (x - np.mean(x)) / np.std(x) return x
补充:Python数据预处理:彻底理解标准化和归一化
数据预处理
数据中不同特征的量纲可能不一致,数值间的差别可能很大,不进行处理可能会影响到数据分析的结果,因此,需要对数据按照一定比例进行缩放,使之落在一个特定的区域,便于进行综合分析。
常用的方法有两种:
最大 - 最小规范化:对原始数据进行线性变换,将数据映射到[0,1]区间
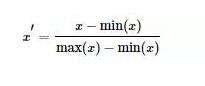
Z-Score标准化:将原始数据映射到均值为0、标准差为1的分布上
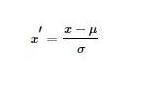
为什么要标准化/归一化?
提升模型精度:标准化/归一化后,不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
加速模型收敛:标准化/归一化后,最优解的寻优过程明显会变得平缓,更容易正确的收敛到最优解。
如下图所示:


哪些机器学习算法需要标准化和归一化
1)需要使用梯度下降和计算距离的模型要做归一化,因为不做归一化会使收敛的路径程z字型下降,导致收敛路径太慢,而且不容易找到最优解,归一化之后加快了梯度下降求最优解的速度,并有可能提高精度。比如说线性回归、逻辑回归、adaboost、xgboost、GBDT、SVM、NeuralNetwork等。需要计算距离的模型需要做归一化,比如说KNN、KMeans等。
2)概率模型、树形结构模型不需要归一化,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率,如决策树、随机森林。

彻底理解标准化和归一化

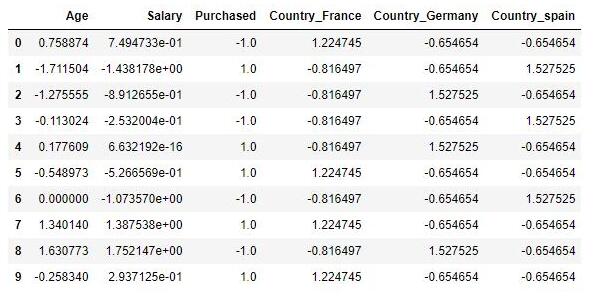
示例数据集包含一个自变量(已购买)和三个因变量(国家,年龄和薪水),可以看出用薪水范围比年龄宽的多,如果直接将数据用于机器学习模型(比如KNN、KMeans),模型将完全有薪水主导。
#导入数据
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('Data.csv')
缺失值均值填充,处理字符型变量
df['Salary'].fillna((df['Salary'].mean()), inplace= True) df['Age'].fillna((df['Age'].mean()), inplace= True) df['Purchased'] = df['Purchased'].apply(lambda x: 0 if x=='No' else 1) df=pd.get_dummies(data=df, columns=['Country'])

最大 - 最小规范化
from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() scaler.fit(df) scaled_features = scaler.transform(df) df_MinMax = pd.DataFrame(data=scaled_features, columns=["Age", "Salary","Purchased","Country_France","Country_Germany", "Country_spain"])

Z-Score标准化
from sklearn.preprocessing import StandardScaler sc_X = StandardScaler() sc_X = sc_X.fit_transform(df) sc_X = pd.DataFrame(data=sc_X, columns=["Age", "Salary","Purchased","Country_France","Country_Germany", "Country_spain"])
import seaborn as sns
import matplotlib.pyplot as plt
import statistics
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
fig,axes=plt.subplots(2,3,figsize=(18,12))
sns.distplot(df['Age'], ax=axes[0, 0])
sns.distplot(df_MinMax['Age'], ax=axes[0, 1])
axes[0, 1].set_title('归一化方差:% s '% (statistics.stdev(df_MinMax['Age'])))
sns.distplot(sc_X['Age'], ax=axes[0, 2])
axes[0, 2].set_title('标准化方差:% s '% (statistics.stdev(sc_X['Age'])))
sns.distplot(df['Salary'], ax=axes[1, 0])
sns.distplot(df_MinMax['Salary'], ax=axes[1, 1])
axes[1, 1].set_title('MinMax:Salary')
axes[1, 1].set_title('归一化方差:% s '% (statistics.stdev(df_MinMax['Salary'])))
sns.distplot(sc_X['Salary'], ax=axes[1, 2])
axes[1, 2].set_title('StandardScaler:Salary')
axes[1, 2].set_title('标准化方差:% s '% (statistics.stdev(sc_X['Salary'])))
可以看出归一化比标准化方法产生的标准差小,使用归一化来缩放数据,则数据将更集中在均值附近。这是由于归一化的缩放是“拍扁”统一到区间(仅由极值决定),而标准化的缩放是更加“弹性”和“动态”的,和整体样本的分布有很大的关系。
所以归一化不能很好地处理离群值,而标准化对异常值的鲁棒性强,在许多情况下,它优于归一化。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

详解python实现数据归一化处理的方式:(0,1)标准化
在机器学习过程中,对数据的处理过程中,常常需要对数据进行归一化处理,下面介绍(0, 1)标准化的方式,简单的说,其功能就是将预处理的数据的数值范围按一定关系"压缩"到(0,1)的范围类. 通常(0, 1)标注化处理的公式为: 即将样本点的数值减去最小值,再除以样本点数值最大与最小的差,原理公式就是这么基础. 下面看看使用python语言来编程实现吧 import numpy as np import matplotlib.pyplot as plt def noramlization(
-
python数据分析数据标准化及离散化详解
本文为大家分享了python数据分析数据标准化及离散化的具体内容,供大家参考,具体内容如下 标准化 1.离差标准化 是对原始数据的线性变换,使结果映射到[0,1]区间.方便数据的处理.消除单位影响及变异大小因素影响. 基本公式为: x'=(x-min)/(max-min) 代码: #!/user/bin/env python #-*- coding:utf-8 -*- #author:M10 import numpy as np import pandas as pd import matplo
-
python数据预处理之数据标准化的几种处理方式
何为标准化: 在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析.数据标准化也就是统计数据的指数化.数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面.数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果.数据无量纲化处理主要解决数据的可比性. 几种标准化方法: 归一化Max-Min min-max标准化方
-
Python3 常用数据标准化方法详解
数据标准化是机器学习.数据挖掘中常用的一种方法.包括我自己在做深度学习方面的研究时,数据标准化是最基本的一个步骤. 数据标准化主要是应对特征向量中数据很分散的情况,防止小数据被大数据(绝对值)吞并的情况. 另外,数据标准化也有加速训练,防止梯度爆炸的作用. 下面是从李宏毅教授视频中截下来的两张图. 左图表示未经过数据标准化处理的loss更新函数,右图表示经过数据标准化后的loss更新图.可见经过标准化后的数据更容易迭代到最优点,而且收敛更快. 一.[0, 1] 标准化 [0, 1] 标准化是最基
-
一个Python优雅的数据分块方法详解
目录 1.背景 2.islice 2.1示例 2.2只指定步长 3.iter 3.1常规使用 3.2进阶使用 4.islice 和 iter 组合使用 5.总结 1.背景 看到这个标题你可能想一个分块能有什么难度?还值得细说吗,最近确实遇到一个有意思的分块函数,写法比较巧妙优雅,所以写一个分享. 日前在做需求过程中有一个对大量数据分块处理的场景,具体来说就是几十万量级的数据,分批处理,每次处理100个.这时就需要一个分块功能的代码,刚好项目的工具库中就有一个分块的函数.拿过函数来用,发现还挺好用
-
AJAX实现JSON与XML数据交换方法详解
目录 1.JS中如何创建和访问JSON对象 2.基于JSON的数据交换 3.基于XML的数据交换 1.JS中如何创建和访问JSON对象 (1)在javascript语言中怎么创建一个json对象,语法是什么? "属性名" : 属性值,"属性名" : 属性值.........的格式! 注意:属性值的数据类型随意:可能是数字,可能是布尔类型,可能是字符串,可能是数组,也可能是一个json对象..... <!DOCTYPE html> <html lan
-
Mongodb中MapReduce实现数据聚合方法详解
Mongodb是针对大数据量环境下诞生的用于保存大数据量的非关系型数据库,针对大量的数据,如何进行统计操作至关重要,那么如何从Mongodb中统计一些数据呢? 在Mongodb中,给我们提供了三种用于数据聚合的方式: (1)简单的用户聚合函数: (2)使用aggregate进行统计: (3)使用mapReduce进行统计: 今天我们首先来讲讲mapReduce是如何统计,在后续的文章中,将另起文章进行相关说明. MapReduce是啥呢?以我的理解,其实就是对集合中的各个满足条件的文档进行预处理
-
Android通过json向MySQL中读写数据的方法详解【读取篇】
本文实例讲述了Android通过json向MySQL中读取数据的方法.分享给大家供大家参考,具体如下: 首先 要定义几个解析json的方法parseJsonMulti,代码如下: private void parseJsonMulti(String strResult) { try { Log.v("strResult11","strResult11="+strResult); int index=strResult.indexOf("[");
-
vuejs动态组件给子组件传递数据的方法详解
通过子组件定义时候的props可以支持父组件给子组件传递数据,这些定义的props在子组件的标签中使用绑定属性即可,但是如果使用的是<component>动态组件,这个时候就没有显式的子组件标签,要给子组件传递数据需要在<component> 中进行绑定 <div class="app" id="deviceready"> <component :is="currentView" :user_name.s
-
PHP中filter函数校验数据的方法详解
介绍PHP中filter函数校验数据的方法详解,PHP过滤器包含两种类型:Validation用来验证验证项是否合法 .Sanitization用来格式化被验证的项目,因此它可能会修改验证项的值,将不合法的字符删除. input_filters_list() 用来列出当前系统所支持的所有过滤器. 复制代码 代码如下: <?php foreach(filter_list() as $id => $filter) { echo $filter.' '.filter_id($filter).
-
Android通过json向MySQL中读写数据的方法详解【写入篇】
本文实例讲述了Android通过json向MySQL中写入数据的方法.分享给大家供大家参考,具体如下: 先说一下如何通过json将Android程序中的数据上传到MySQL中: 首先定义一个类JSONParser.Java类,将json上传数据的方法封装好,可以直接在主程序中调用该类,代码如下 public class JSONParser { static InputStream is = null; static JSONObject jObj = null; static String j
-
对python xlrd读取datetime类型数据的方法详解
使用xlrd读取出来的时间字段是类似41410.5083333的浮点数,在使用时需要转换成对应的datetime类型,下面代码是转换的方法: 首先需要引入xldate_as_tuple函数 from xlrd import xldate_as_tuple 使用方法如下: #d是从excel中读取出来的浮点数 xldate_as_tuple(d,0) xldate_as_tuple第二个参数有两种取值,0或者1,0是以1900-01-01为基准的日期,而1是1904-01-01为基准的日期.该函数
-
对python抓取需要登录网站数据的方法详解
scrapy.FormRequest login.py class LoginSpider(scrapy.Spider): name = 'login_spider' start_urls = ['http://www.login.com'] def parse(self, response): return [ scrapy.FormRequest.from_response( response, # username和password要根据实际页面的表单的name字段进行修改 formdat