分享5个数据处理更加灵活的pandas调用函数方法
目录
- 0. 数据预览
- 1. apply
- 2. applymap
- 3. map
- 4. agg
- 5. pipe
0. 数据预览
这里的数据是虚构的语数外成绩,大家在演示的时候拷贝一下就好啦。
import pandas as pd df = pd.read_clipboard() df
|
姓名 |
语文 |
数学 |
英语 |
性别 |
总分 |
|
0 |
才哥 |
91 |
95 |
92 |
1 |
|
1 |
小明 |
82 |
93 |
91 |
1 |
|
2 |
小华 |
82 |
87 |
94 |
1 |
|
3 |
小草 |
96 |
55 |
88 |
0 |
|
4 |
小红 |
51 |
41 |
70 |
0 |
|
5 |
小花 |
58 |
59 |
40 |
0 |
|
6 |
小龙 |
70 |
55 |
59 |
1 |
|
7 |
杰克 |
53 |
44 |
42 |
1 |
|
8 |
韩梅梅 |
45 |
51 |
67 |
0 |
1. apply
apply可以对DataFrame类型数据按照列或行进行函数处理,默认情况下是按照列(单独对Series亦可)。
在案例数据中,比如我们想将性别列中的1替换为男,0替换为女,那么可以这样搞定。
先自定义一个函数,这个函数有一个参数 s(Series类型数据)。
def getSex(s): if s==1: return '男' elif s==0: return '女'
上述函数还有更简洁写法,这里方便理解采用最直观的写法哈。
然后,我们直接使用apply去调用这个函数即可。
df['性别'].apply(getSex)
可以看到输出结果如下:
0 男
1 男
2 男
3 女
4 女
5 女
6 男
7 男
8 女
Name: 性别, dtype: object
当然,我们也可以直接用调用匿名函数lambda的形式:
df['性别'].apply( lambda s: '男' if s==1 else '女' )
可以看到结果是一样的:
0 男
1 男
2 男
3 女
4 女
5 女
6 男
7 男
8 女
Name: 性别, dtype: object
以上是单纯根据一列的值条件进行的数据处理,我们也可以根据多列组合条件(可以了解为按行)进行处理,需要注意这种情况下需要指定参数axis=1,具体看下面案例。
案例中,我们认为总分高于200且数学分数高于90为高分
# 多列条件组合 df['level'] = df.apply(lambda df: '高分' if df['总分']>=200 and df['数学']>=90 else '其他', axis=1) df

同样,上述用apply调用的函数都是自定义的,实际上我们也可以调用内置或者pandas/numpy等自带的函数。
比如,求语数外和总分最高分:
# python内置的函数 df[['语文','数学','英语','总分']].apply(max)
语文 96
数学 95
英语 94
总分 278
dtype: int64
求语数外和总分平均分:
# numpy自带的函数 import numpy as np df[['语文','数学','英语','总分']].apply(np.mean)
语文 69.777778
数学 64.444444
英语 71.444444
总分 205.666667
dtype: float64
2. applymap
applymap则是对每个元素的函数处理,变量是每个元素值。
比如对语数外三科超过90分认为是科目高分
df[['语文','数学','英语']].applymap(lambda x:'高分' if x>=90 else '其他')
|
语文 |
数学 |
英语 |
|
0 |
高分 |
高分 |
|
1 |
其他 |
高分 |
|
2 |
其他 |
其他 |
|
3 |
高分 |
其他 |
|
4 |
其他 |
其他 |
|
5 |
其他 |
其他 |
|
6 |
其他 |
其他 |
|
7 |
其他 |
其他 |
|
8 |
其他 |
其他 |
3. map
map则是根据输入对应关系映射值返回最终数据,作用于某一列。传入的值可以是字典,键值为原始值,值为需要替换的值。也可以传入一个函数或者字符格式化表达式等等。
以上面性别列中的1替换为男,0替换为女为例,还可以通过map来实现
df['性别'].map({1:'男', 0:'女'})
输出结果也是一致的:
0 男
1 男
2 男
3 女
4 女
5 女
6 男
7 男
8 女
Name: 性别, dtype: object
比如总分列想变成格式化字符:
df['总分'].map('总分:{}分'.format)
0 总分:278分
1 总分:266分
2 总分:263分
3 总分:239分
4 总分:162分
5 总分:157分
6 总分:184分
7 总分:139分
8 总分:163分
Name: 总分, dtype: object
4. agg
agg一般用于聚合,在分组或透视操作中常见到,用法是和apply比较接近。
比如,求语数外和总分的最高分、最低分和平均分
df[['语文','数学','英语','总分']].agg(['max','min','mean'])
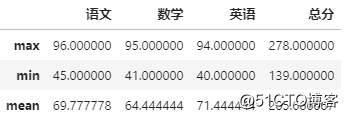
我们还可以对不同的列进行不同的运算(用字典形式指定)
# 语文最高分、数学最低分和英文最高最低分
df.agg({'语文':['max'],'数学':'min','英语':['max','min']})

当然也支持自定义函数的调用
5. pipe
以上四个调用函数的方法,我们发现被调用的函数的参数就是 DataFrame或Serise数据,如果我们被调用的函数还需要别的参数,那么该如何做呢?
所以,pipe就出现了。
pipe又称管道方法,可以将我们的处理分析过程标准化、流程化。它在调用函数的时候可以带被调用函数的其他参数,这样就方便自定义函数的功能扩展了。
比如,我们需要获取总分大于n,性别为sex的同学的数据,其中n和sex是可变参数,那么用apply等就不太好处理。这个时候,就可以用到pipe方法来搞事了!
我们先定义一个函数:
# 定义一个函数,总分大于等于n,性别为sex的同学数据(sex为2表示不分性别) def total(df, n, sex): dfT = df.copy() if sex == 2: return dfT[(dfT['总分']>=n)] else: return dfT[(dfT['总分']>=n) & (dfT['性别']==sex)]
如果我们要找到总分大于200,不分性别的学生成绩,可以这样:
df.pipe(total,200,2)

再找总分大于150,性别为男生(1)的学生成绩,可以这样:
df.pipe(total,150,1)

再找总分大于200,性别为女生(0)的学生成绩,可以这样:
df.pipe(total,200,0)

以上就是本次我们介绍的5种调用函数的方法,这些操作技巧可以让我们在处理数据时更加灵活自如
到此这篇关于分享5个数据处理更加灵活的pandas调用函数方法的文章就介绍到这了,更多相关pandas调用函数方法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python调用Pandas实现Excel读取
目录 开头先BB两句 操作过程 安装Python Pandas安装包 上手使用 创建Excel,写入数据 完整代码 开头先BB两句 基本上来说,每周五写的周报都是这个套路. 突然想用Python智能化办公,修改Excel表格. 先不考虑,合并单元格,修改表格样式的操作.就先做个简单的读写. 操作过程 安装Python 工欲善其事必先利其器,首先做好准备工作,开发环境必不可少. 直接官网下载安装包,我使用的是3.6.5版本.下载安装后,配置环境变量. 开发工具,我就直接用的vscode,安装了一个
-
分享5个数据处理更加灵活的pandas调用函数方法
目录 0. 数据预览 1. apply 2. applymap 3. map 4. agg 5. pipe 0. 数据预览 这里的数据是虚构的语数外成绩,大家在演示的时候拷贝一下就好啦. import pandas as pd df = pd.read_clipboard() df 姓名 语文 数学 英语 性别 总分 0 才哥 91 95 92 1 1 小明 82 93 91 1 2 小华 82 87 94 1 3 小草 96 55 88 0 4 小红 51 41 70 0 5 小花 58 59
-
Python Pandas常用函数方法总结
初衷 NumPy.Pandas.Matplotlib.SciPy 等可以说是最最最常用的 Python 库了.我们在使用 Python 库的时候,通常会遇到两种情况.以 Pandas 举例. 我想对 Pandas 数据结构的数据实现某种操作,但是我不知道或者说在我的印象里似乎已经不记得是否有这样的函数方法,如果有,又该用哪个方法呢? 我想实现某种数据操作,我记得我用过或者见过某个函数可以实现这个功能,但是我死活想不起来那个函数叫啥了.或者,我想起来了哪个函数可以实现这个功能,但是我想知道是否有更
-
Python数据处理的26个Pandas实用技巧总结
目录 从剪贴板中创建DataFram 将DataFrame划分为两个随机的子集 多种类型过滤DataFrame DataFrame筛选数量最多类别 处理缺失值 一个字符串划分成多列 Series扩展成DataFrame 对多个函数进行聚合 聚合结果与DataFrame组合 选取行和列的切片 MultiIndexedSeries重塑 创建数据透视表 连续数据转类别数据 StyleaDataFrame 额外技巧 ProfileaDataFrame 大家好,今天给大家分享一篇 pandas 实用技巧,
-
pandas apply 函数 实现多进程的示例讲解
前言: 在进行数据处理的时候,我们经常会用到 pandas .但是 pandas 本身好像并没有提供多进程的机制.本文将介绍如何来自己实现 pandas (apply 函数)的多进程执行.其中,我们主要借助 joblib库,这个库为python 提供了一个非常简洁方便的多进程实现方法. 所以,本文将按照下面的安排展开,前面可能比较啰嗦,若只是想知道怎么用可直接看第三部分: - 首先简单介绍 pandas 中的分组聚合操作 groupby. - 然后简单介绍 joblib 的使用方法. - 最后,
-
使用Pandas的Series方法绘制图像教程
通常绘制二维曲线的时候可以使用matplotlib,不过如果电脑上安装了pandas的话可以直接使用Series的绘图方法进行图像的绘制. pandas绘制图像其实也是给予matplotlib的绘图功能处理相应的数据,最终绘制出相应的曲线. 在图形对象创建并操作之后还需要调用matplotlib的图像显示方法才能够最终显示出绘制的图像. 编写代码如下: import pandas as pd from pandas import Series,DataFrame import numpy as
-
Python基于numpy灵活定义神经网络结构的方法
本文实例讲述了Python基于numpy灵活定义神经网络结构的方法.分享给大家供大家参考,具体如下: 用numpy可以灵活定义神经网络结构,还可以应用numpy强大的矩阵运算功能! 一.用法 1). 定义一个三层神经网络: '''示例一''' nn = NeuralNetworks([3,4,2]) # 定义神经网络 nn.fit(X,y) # 拟合 print(nn.predict(X)) #预测 说明: 输入层节点数目:3 隐藏层节点数目:4 输出层节点数目:2 2).定义一个五层神经网络:
-
pandas值替换方法
如下所示: import pandas as pd from pandas import * import numpy as np data = Series([1,-999,2,-999,-1000,3]) print(data.replace(-999,np.nan)) print(data.replace([-999,-1000],np.nan)) print(data.replace([-999,-1000],[np.nan,0])) print(data.replace({-999:n
-
对pandas replace函数的使用方法小结
语法:replace(self, to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad', axis=None) 使用方法如下: import numpy as np import pandas as pd df = pd.read_csv('emp.csv') df #Series对象值替换 s = df.iloc[2]#获取行索引为2数据 #单值替换 s.replace('?',np.
-
Python pandas自定义函数的使用方法示例
本文实例讲述了Python pandas自定义函数的使用方法.分享给大家供大家参考,具体如下: 自定义函数的使用 import numpy as np import pandas as pd # todo 将自定义的函数作用到dataframe的行和列 或者Serise的行上 ser1 = pd.Series(np.random.randint(-10,10,5),index=list('abcde')) df1 = pd.DataFrame(np.random.randint(-10,10,(
-
Pandas Shift函数的基础入门学习笔记
Pandas Shift函数基础 在使用Pandas的过程中,有时会遇到shift函数,今天就一起来彻底学习下.先来看看帮助文档是怎么说的: >>> import pandas >>> help(pandas.DataFrame.shift) Help on function shift in module pandas.core.frame: shift(self, periods=1, freq=None, axis=0) Shift index by desire