Pandas筛选DataFrame含有空值的数据行的实现
目录
- 数据准备
- 1.筛选指定单列中有空值的数据行
- 2.筛选指定多列中/全部列中满足所有列有空值的数据行
- 3.筛选指定多列中/全部列中满足任意一列有空值的数据行
数据准备
import pandas as pd
df = pd.DataFrame([['ABC','Good',1],
['FJZ',None,2],
['FOC','Good',None]
],columns=['Site','Remark','Quantity'])
df
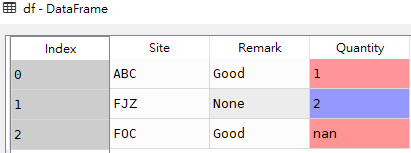
注意:上述Remark字段中的数据类型为字符串str类型,空值取值为'None',Quantity字段中的数据类型为数值型,空值取值为nan
1.筛选指定单列中有空值的数据行
# 语法 df[pd.isnull(df[col])] df[df[col].isnull()]
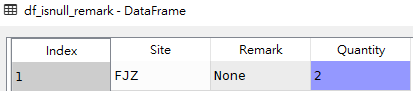
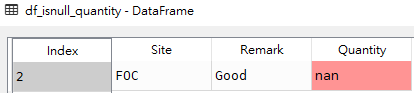
# 获取Remark字段为None的行 df_isnull_remark = df[df['Remark'].isnull()] # 获取Quantity字段为None的行 df_isnull_quantity = df[df['Quantity'].isnull()]
df_isnull_remark
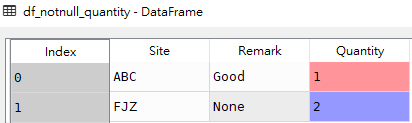
df_isnull_quantity
提示
筛选指定单列中没有空值的数据行
# 语法 df[pd.notnull(df[col])] df[df[col].notnull()]
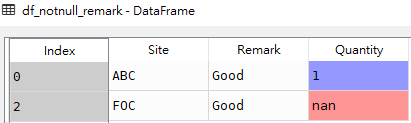
# 获取Remark字段为非None的行 df_notnull_remark = df[df['Remark'].notnull()] # 获取Quantity字段为非None的行 df_notnull_quantity = df[df['Quantity'].notnull()]
df_notnull_remark
df_notnull_quantity
2.筛选指定多列中/全部列中满足所有列有空值的数据行
# 语法 df[df[[cols]].isnull().all(axis=1)] df[pd.isnull(df[[cols]]).all(axis=1)]
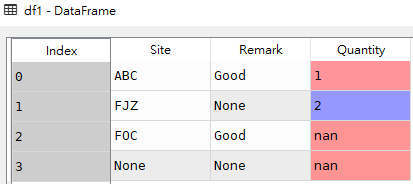
在df基础上增加一行生成df1
df1 = pd.DataFrame([['ABC','Good',1],
['FJZ',None,2],
['FOC','Good',None],
[None,None,None]
],columns=['Site','Remark','Quantity'])
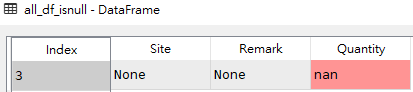
# 获取df1所有列有空值的数据行 all_df_isnull = df1[df1[['Site','Remark','Quantity']].isnull().all(axis=1)]
all_df_isnull
提示
筛选指定多列中/全部列中满足所有列没有空值的数据行
# 语法 df[df[[cols]].notnull().all(axis=1)] df[pd.notnull(df[[cols]]).all(axis=1)]
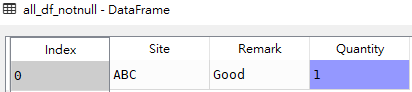
# 获取df1所有列没有空值的数据行 all_df_notnull = df1[df1[['Site','Remark','Quantity']].notnull().all(axis=1)]
all_df_notnull
3.筛选指定多列中/全部列中满足任意一列有空值的数据行
# 语法 df[df[[cols]].isnull().any(axis=1)] df[pd.isnull(df[[cols]]).any(axis=1)]
df1(数据源)
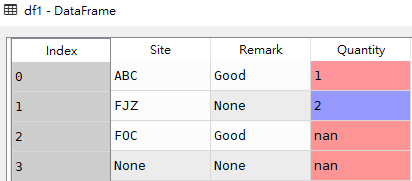
# 获取df1所有列中满足任意一列有空值的数据行 any_df_isnull = df1[df1[['Site','Remark','Quantity']].isnull().any(axis=1)]
any_df_isnull
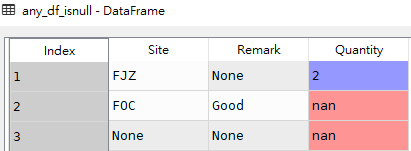
提示
筛选指定多列中/全部列中满足任意一列没有空值的数据行
# 语法 df[df[[cols]].notnull().any(axis=1)] df[pd.notnull(df[[cols]]).any(axis=1)]
# 获取df1所有列中满足任意一列没有空值的数据行 any_df_notnull = df1[df1[['Site','Remark','Quantity']].notnull().any(axis=1)]
any_df_notnull
Numpy里边查找NaN值的话,使用np.isnan()
Pabdas里边查找NaN值的话,使用.isna()或.isnull()
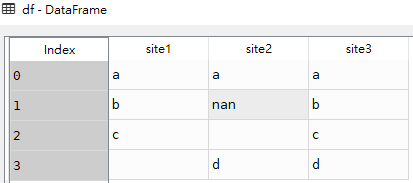
import pandas as pd
import numpy as np
df = pd.DataFrame({'site1': ['a', 'b', 'c', ''],
'site2': ['a', np.nan, '', 'd'],
'site3': ['a', 'b', 'c', 'd']})
df
df['contact_site'] = df['site1'] + df['site2'] + df['site3']
新增数据列后的df
res1 = df[df['site2'].isnull()] res2 = df[df['site2'].isna()] res3 = df[df['site2']=='']
res1

res2

res3

注意:res1和res2的结果相同,说明.isna()和.isnull()的作用等效
到此这篇关于Pandas筛选DataFrame含有空值的数据行的实现的文章就介绍到这了,更多相关Pandas筛选DataFrame空值行内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python pandas.DataFrame 找出有空值的行
0.摘要 pandas中DataFrame类型中,找出所有有空值的行,可以使用.isnull()方法和.any()方法. 1.找出含有空值的行 方法:DataFrame[DataFrame.isnull().T.any()] 其中,isnull()能够判断数据中元素是否为空值:T为转置:any()判断该行是否有空值. import pandas as pd import numpy as np n = np.arange(20, dtype=float).reshape(5,4) n[2,3]
-

Pandas筛选DataFrame含有空值的数据行的实现
目录 数据准备 1.筛选指定单列中有空值的数据行 2.筛选指定多列中/全部列中满足所有列有空值的数据行 3.筛选指定多列中/全部列中满足任意一列有空值的数据行 数据准备 import pandas as pd df = pd.DataFrame([['ABC','Good',1], ['FJZ',None,2], ['FOC','Good',None] ],columns=['Site','Remark','Quantity']) df 注意:上述Remark字段中的数据类型为字符串str类型,
-
Pandas 筛选和删除目标值所在的行的实现
目录 1.筛选出目标值所在行 单列筛选 多列筛选 2.删除目标值所在的行 扩展补充案例:删除列为指定值所在的行 1.筛选出目标值所在行 单列筛选 # df[列名].isin([目标值])对当前列中存在目标值的行会返回True,不存在的返回False df[df[列名].isin([目标值])] 练习案例 import pandas as pd df_bom_data = pd.DataFrame([['A123',1200,5], ['B456',550,2], ['C437',500,10],
-
pandas将DataFrame的几列数据合并成为一列
目录 1.1 方法归纳 1.2 .str.cat函数详解 1.2.1 语法格式: 1.2.2 参数说明: 1.2.3 核心功能: 1.2.4 常见范例: 1.1 方法归纳 使用 + 直接将多列合并为一列(合并列较少): 使用pandas.Series.str.cat方法,将多列合并为一列(合并列较多): 范例如下: dataframe["newColumn"] = dataframe["age"].map(str) + dataframe["phone&q
-
python Pandas之DataFrame索引及选取数据
目录 1.索引是什么 1.1 认识索引 1.2 自定义索引 2. 索引的简单使用 2.1 列索引 2.2 行索引 2.2.1 使用[ ] 2.2.2 使用.loc()和.iloc() 1.索引是什么 1.1 认识索引 先创建一个简单的DataFrame. myList = [['a', 10, 1.1], ['b', 20, 2.2], ['c', 30, 3.3], ['d', 40, 4.4]] df1 = pd.DataFrame(data = myList) print(df1) ---
-
pandas.DataFrame删除/选取含有特定数值的行或列实例
1.删除/选取某列含有特殊数值的行 import pandas as pd import numpy as np a=np.array([[1,2,3],[4,5,6],[7,8,9]]) df1=pd.DataFrame(a,index=['row0','row1','row2'],columns=list('ABC')) print(df1) df2=df1.copy() #删除/选取某列含有特定数值的行 #df1=df1[df1['A'].isin([1])] #df1[df1['A'].
-
python pandas中DataFrame类型数据操作函数的方法
python数据分析工具pandas中DataFrame和Series作为主要的数据结构. 本文主要是介绍如何对DataFrame数据进行操作并结合一个实例测试操作函数. 1)查看DataFrame数据及属性 df_obj = DataFrame() #创建DataFrame对象 df_obj.dtypes #查看各行的数据格式 df_obj['列名'].astype(int)#转换某列的数据类型 df_obj.head() #查看前几行的数据,默认前5行 df_obj.tail() #查看后几
-
python pandas dataframe 按列或者按行合并的方法
concat 与其说是连接,更准确的说是拼接.就是把两个表直接合在一起.于是有一个突出的问题,是横向拼接还是纵向拼接,所以concat 函数的关键参数是axis . 函数的具体参数是: concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False) objs 是需要拼接的对象集合,一般为列表或者字典 axis=0 是
-
Python实现删除某列中含有空值的行的示例代码
客户需求 查看销售人员不为空值的行 数据存储情况如图: 代码实现 import pandas as pd data = pd.read_excel('test.xlsx',sheet_name='Sheet1') datanota = data[data['销售人员'].notna()] print(datanota) 输出结果 D:\Python\Anaconda\python.exe D:/Python/test/EASdeal/test.py 城市 销售金额 销售人员 0 北京 10000
-
在Pandas中DataFrame数据合并,连接(concat,merge,join)的实例
最近在工作中,遇到了数据合并.连接的问题,故整理如下,供需要者参考~ 一.concat:沿着一条轴,将多个对象堆叠到一起 concat方法相当于数据库中的全连接(union all),它不仅可以指定连接的方式(outer join或inner join)还可以指定按照某个轴进行连接.与数据库不同的是,它不会去重,但是可以使用drop_duplicates方法达到去重的效果. concat(objs, axis=0, join='outer', join_axes=None, ignore_ind
-
浅谈pandas筛选出表中满足另一个表所有条件的数据方法
今天记录一下pandas筛选出一个表中满足另一个表中所有条件的数据.例如: list1 结构:名字,ID,颜色,数量,类型. list1 = [['a',1,255,100,'03'],['a',2,481,50,'06'],['a',47,255,500,'03'],['b',3,1,50,'11']] list2结构:名字,类型,颜色. list2 = [['a','03',255],['a','06',481]] 如何在list1中找出所有与list2中匹配的元素?要得到下面的结果:lis