Python中免验证跳转到内容页的实例代码
相信很多人在浏览网页时,经常会碰到需要输入验证码才可以继续浏览的情况吧,遇到这种问题,大多数人只能进行繁琐的注册验证,今天小编教大家只要使用python就可以免验证方法。
以经常用到的解答网站——上学吧为例,在网站里点击答案页面,会显示验证后才可以查看提示,下面就使用python实现跳过验证码。
我们需要通过python构造随机的 X-Forwarded-For 信息来绕过 ASP 网站的 IP 检测,可以实现对输入的网址正确性进行检查、对验证码核验不通过时的处理等等。
python免验证跳转页面代码如下:
# 绕过验证码无限次获取上学吧题目答案
# 上学吧网址:https://www.shangxueba.com/ask
import os
import random
import requests
import urllib3
urllib3.disable_warnings() # 这句和上面一句是为了忽略 https 安全验证警告,参考:https://www.cnblogs.com/ljfight/p/9577783.html
from bs4 import BeautifulSoup
from PIL import Image
def get_verifynum(session): # 网址的验证码逻辑是先去这个网址获取验证码图片,提交计算结果到另外一个网址进行验证。
r = session.get("https://www.shangxueba.com/ask/VerifyCode2.aspx", verify=False) # HTTPS 请求进行 SSL 验证或忽略 SSL 验证才能请求成功,忽略方式为 verify=False。参考:https://www.cnblogs.com/ljfight/p/9577783.html
with open('temp.png','wb+') as f:
f.write(r.content)
image = Image.open('temp.png')
image.show() # 调用系统的图片查看软件打开验证码图片,如果不能打开,可以自己找到 temp.png 打开。
verifynum = input("\n请输入验证码图片中的计算结果:")
image.close()
os.remove("temp.png")
return verifynum
def get_question(session):
r = session.get(link)
soup = BeautifulSoup(r.content, "html.parser")
description = soup.find(attrs={"name":"description"})['content'] # 抓取题干内容
return description
def get_answer(session, verifynum, dataid):
data1 = {
"Verify": verifynum,
"action": "CheckVerify",
}
session.post("https://www.shangxueba.com/ask/ajax/GetZuiJia.aspx", data=data1) # 核查验证码正确性
data2 = {
"phone":"",
"dataid": dataid,
"action": "submitVerify",
"siteid": "1001",
"Verify": verifynum,
}
r = session.post("https://www.shangxueba.com/ask/ajax/GetZuiJia.aspx", data=data2)
soup = BeautifulSoup(r.content, "html.parser")
ans = soup.find('h6')
print("\n" + '-'*45)
if(ans): # 只有验证码核查通过才会显示答案
print("\n题目:" + get_question(session))
print(ans.text)
else:
print('\n没有找到答案!请检查验证码或网址是否输入有误!\n')
print('-'*45)
if __name__ == '__main__':
s = requests.session()
while True:
s.headers.update({"X-Forwarded-For":"%d.%d.%d.%d"%(random.randint(120,125),random.randint(1,200),random.randint(1,200),random.randint(1,200))}) # 这一句是整个程序的关键,通过修改 X-Forwarded-For 信息来欺骗 ASP 站点对于 IP 的验证。
link = input("\n请输入上学吧网站上某道题目的网址,例如:https://www.shangxueba.com/ask/8952241.html\n\n请输入:").strip() # 过滤首尾的空格
if(link[0:31] != "https://www.shangxueba.com/ask/" or link[-4:] != "html"):
print("\n网址输入有误!请重新输入!\n")
continue
dataid = link.split("/")[-1].replace(r".html","") # 提取网址最后的数字部分
if(dataid.isdigit()): # 根据格式,dataid 应该全部为数字,判断字符串是否全部为数字,返回 True 或者 False
verifynum = get_verifynum(s)
get_answer(s, verifynum, dataid)
else:
print("\n网址输入有误!请重新输入!\n")
continue
注意:其中 requests 和 beautifulsoup 两个库需要另外安装,建议使用 pip 方式安装:
pip install requests
pip install beautifulsoup4
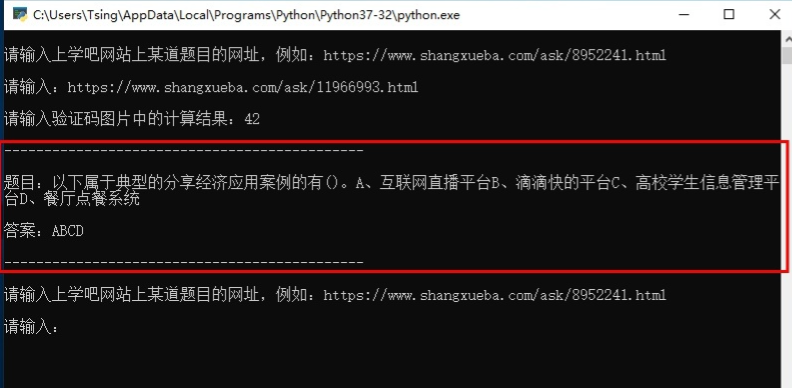
Python 脚本运行流程:
首先复制上学吧某道题目的网址,类似以下格式:
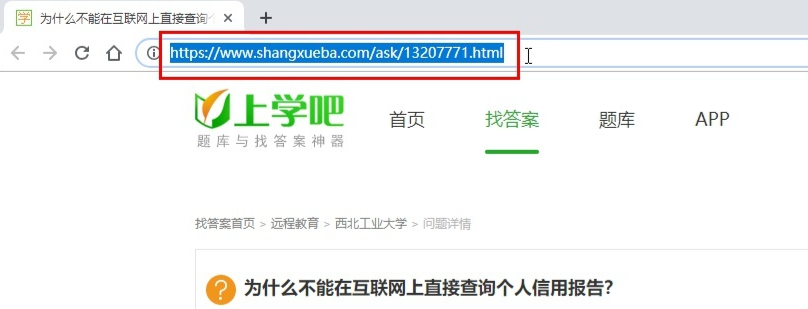
然后运行python脚本,复制粘贴网址。
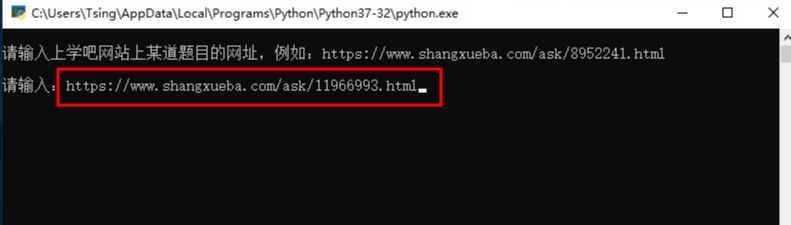
按Enter键,自动下载验证码图片存为 temp.png,然后自动读取图片并展示,也可以手动打开同目录下的 temp.png 图片。
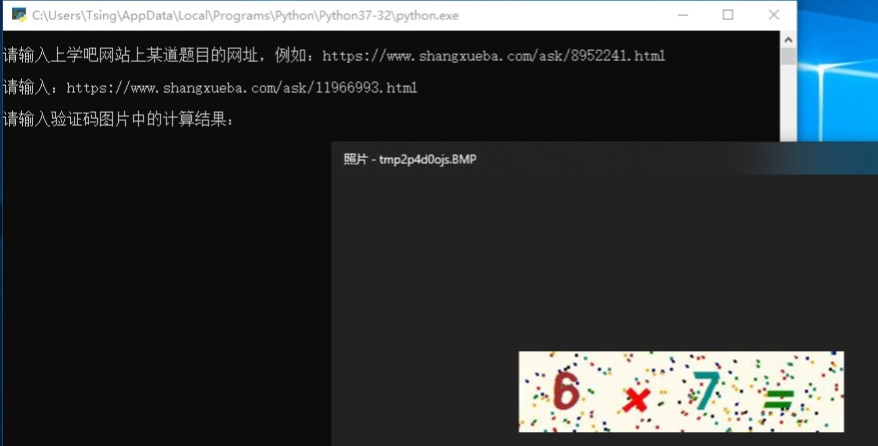
最后在命令行窗口输入验证码图片中的计算结果即可获取题目详情以及正确答案。
到此这篇关于Python中免验证跳转到内容页的实例代码的文章就介绍到这了,更多相关Python如何免验证跳转到内容页内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python中免验证跳转到内容页的实例代码
相信很多人在浏览网页时,经常会碰到需要输入验证码才可以继续浏览的情况吧,遇到这种问题,大多数人只能进行繁琐的注册验证,今天小编教大家只要使用python就可以免验证方法. 以经常用到的解答网站--上学吧为例,在网站里点击答案页面,会显示验证后才可以查看提示,下面就使用python实现跳过验证码. 我们需要通过python构造随机的 X-Forwarded-For 信息来绕过 ASP 网站的 IP 检测,可以实现对输入的网址正确性进行检查.对验证码核验不通过时的处理等等. python免验证跳转页
-
Vue利用路由钩子token过期后跳转到登录页的实例
在Vue2.0中的路由钩子主要是用来拦截导航,让它完成跳转或前取消,可以理解为路由守卫. 分为全局导航钩子,单个路由独享的钩子,组件内钩子. 三种 类型的钩子只是用的地方不一样,都接受一个函数作为参数,函数传入三个参数,分别为to,from,next. 其中next有三个方法 (1)next(); //默认路由 (2)next(false); //阻止路由跳转 (3)next({path:'/'}); //阻止默认路由,跳转到指定路径 这里我使用了组件内钩子进行判断token过期后跳转到登录页,
-

yii2分页之实现跳转到具体某页的实例代码
先上图看效果,大家感觉还错请参考功能怎么实现的! 从上图中不难看出,我们制定跳转到某页的功能是基于linkpager之上的扩展,这根我们之前实现的分页扩展明显不同,之前的明显就是重写了!当然,这都不重要,我们看看GoLinkPager的具体实现!名字起的有点lower,不重要! 1.在frontend\components目录新建GoLinkPager类文件 2.该类继承yii\widgets\LinkPager;,如下: namespace frontend\components; use y
-
python批量替换页眉页脚实例代码
简介 本文分享的实例代码主要通过python语言实现批量替换页眉页脚的操作功能,具体如下. 代码 #!/usr/bin/env python # -*- coding: utf-8 -*- import win32com,os,sys,re from win32com.client import Dispatch, constants # 打开新的文件 suoyou = os.listdir('d:\\daizhuan') #print suoyou for i in suoyou: wenji
-
Vue实现未登录跳转到登录页的示例代码
1.登录页登录成功时将服务端返回的标识存放起来 2.在router中给不需要登录的页面设置 meta : { auth : false },如首页 3.使用路由前置守卫beforEach,由于给路由设置了meta : { auth : false },如果是符合该属性时则不需要跳转登录页 4.接下来根据token是否存入到localstorage来进行判断或者cookie是否存入客户端做判断,这里在vuex中做处理 如果token和cookie不存在时则需要跳转到登录页 5.在axios中响应拦
-
python将字典内容存入mysql实例代码
本文主要研究的是python将字典内容存入mysql,分享了实现代码,具体介绍如下. 1.背景 项目需要,用python实现了将字典内容存入本地的mysql数据库.比如说有个字典dic={"a":"b","c":"d"},存入数据库效果图如下: 2.代码 ''''' Insert items into database @author: hakuri ''' import MySQLdb def InsertData(Tabl
-
Session过期后自动跳转到登录页面的实例代码
最近做了一个项目其中有需求,要实现自动登录功能,通过查阅相关资料,打算用session监听来做,下面给大家列出了配置监听器的方法: 1.在项目的web.xml文件中添加如下代码: <!--添加Session监听器--> <listener> <listener-class> 监听器路径 </listener-class> </listener> 2.编写java类. public class SessionListener implements
-
Java发送带html标签内容的邮件实例代码
如下所示: package test; import javax.mail.internet.InternetAddress; import javax.mail.internet.MimeMessage; import javax.mail.internet.MimeUtility; import javax.mail.Session; import javax.mail.MessagingException; import javax.mail.Transport; public class
-
利用Python实现Windows下的鼠标键盘模拟的实例代码
本文介绍了利用Python实现Windows下的鼠标键盘模拟的实例代码,分享给大家 本来用按键精灵是可以实现我的需求,而且更简单,但既然学python ,就看一下呗. 依赖: PyUserInput pip install PyUserInput PyUserInput 依赖 pyhook,所以还得安装 pyhook.按需下载,下载地址. 我是 win10 64 位 python 2.7,用的是第二个,下载之后用解压软件打开,把 pyHook放到C:\Python27\Lib\site-pack
-
python 打印出所有的对象/模块的属性(实例代码)
实例如下: import sys def print_all(module_): modulelist = dir(module_) length = len(modulelist) for i in range(0,length,1): print getattr(module_,modulelist[i]) print_all(sys) 以上这篇python 打印出所有的对象/模块的属性(实例代码)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.