elasticsearch索引index之engine读写控制结构实现
目录
- engine的实现结构
- Engine类的方法:
- 如index方法的实现:
- 总结
engine的实现结构
elasticsearch对于索引中的数据操作如读写get等接口都封装在engine中,同时engine还封装了索引的读写控制,如流量、错误处理等。engine是离lucene最近的一部分。
engine的实现结构如下所示:
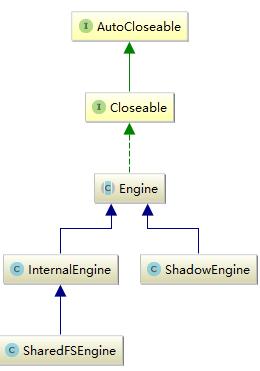
engine接口有三个实现类,主要逻辑都在InternalEngine中。
ShadowEngine之实现了engine接口的部分读方法,主要用于对于索引的读操作。
shardFSEngine在InternalEngine的基础上实现了recovery方法,它的功能跟InternalEngine基本相同只是它的recovery过程有区别,不会对Translog和index进行快照存储。
Engine类定义了一些index操作的主要方法和内部类,方法如create,index等。内部类如index,delete等。这些方法的实现是在子类中,这些方法的参数是这些内部类。
Engine类的方法:
public abstract void create(Create create) throws EngineException;
public abstract void index(Index index) throws EngineException;
public abstract void delete(Delete delete) throws EngineException;
public abstract void delete(DeleteByQuery delete) throws EngineException;
这些抽象方法都在子类中实现,它们的参数都是一类,这些都是Engine的内部类,这些内部类类似于实体类,没有相关逻辑只是由很多filed及get方法构成。如Create和Index都继承自IndexOperation,它们所有信息都存储到IndexOperation的相关Field中,IndexOperation如下所示:
public static abstract class IndexingOperation implements Operation {
private final DocumentMapper docMapper;
private final Term uid;
private final ParsedDocument doc;
private long version;
private final VersionType versionType;
private final Origin origin;
private final boolean canHaveDuplicates;
private final long startTime;
private long endTime;
………………
}
无论是Index还是Create,相关数据和配置都在doc中,根据doc和docMapper就能够获取本次操作的所有信息,另外的一些字段如version,uid都是在类初始化时构建。这样传给实际方法的是一个class,在方法内部根据需求获取到相应的数据
如index方法的实现:
private void innerIndex(Index index) throws IOException {
synchronized (dirtyLock(index.uid())) {
final long currentVersion;
VersionValue versionValue = versionMap.getUnderLock(index.uid().bytes());
if (versionValue == null) {
currentVersion = loadCurrentVersionFromIndex(index.uid());
} else {
if (engineConfig.isEnableGcDeletes() && versionValue.delete() && (engineConfig.getThreadPool().estimatedTimeInMillis() - versionValue.time()) > engineConfig.getGcDeletesInMillis()) {
currentVersion = Versions.NOT_FOUND; // deleted, and GC
} else {
currentVersion = versionValue.version();
}
}
long updatedVersion;
long expectedVersion = index.version();
if (index.versionType().isVersionConflictForWrites(currentVersion, expectedVersion)) {
if (index.origin() == Operation.Origin.RECOVERY) {
return;
} else {
throw new VersionConflictEngineException(shardId, index.type(), index.id(), currentVersion, expectedVersion);
}
}
updatedVersion = index.versionType().updateVersion(currentVersion, expectedVersion);
index.updateVersion(updatedVersion);
if (currentVersion == Versions.NOT_FOUND) {
// document does not exists, we can optimize for create
index.created(true);
if (index.docs().size() > 1) {
indexWriter.addDocuments(index.docs(), index.analyzer());
} else {
indexWriter.addDocument(index.docs().get(0), index.analyzer());
}
} else {
if (versionValue != null) {
index.created(versionValue.delete()); // we have a delete which is not GC'ed...
}
if (index.docs().size() > 1) {
indexWriter.updateDocuments(index.uid(), index.docs(), index.analyzer());//获取IndexOperation中doc中字段更新索引
} else {
indexWriter.updateDocument(index.uid(), index.docs().get(0), index.analyzer());
}
}
Translog.Location translogLocation = translog.add(new Translog.Index(index));//写translog
versionMap.putUnderLock(index.uid().bytes(), new VersionValue(updatedVersion, translogLocation));
indexingService.postIndexUnderLock(index);
}
}
这就是Engine中create、index这些方法的实现方式。后面分析索引过程中会有更加详细说明。Engine中还有获取索引状态(元数据)及索引操作的方法如merge。这些方法也是在子类中调用lucene的相关接口,跟create,index,get很类似。因为没有深入Engine的方法实现,因此这里的分析比较简单,后面的分析会涉及这里面很多方法。
总结
这里只是从结构上对indexEngine进行了简单说明,它里面的方法是es对lucene索引操作方法的封装,只是增加了一下处理方面的逻辑如写translog,异常处理等。它的操作对象是shard,es所有对shard的写操作都是通过Engine来实现,后面的分析会有所体现。
以上就是elasticsearch索引index之engine读写控制结构实现的详细内容,更多关于elasticsearch索引index engine读写控制的资料请关注我们其它相关文章!
相关推荐
-
Elasticsearch索引的分片分配Recovery使用讲解
目录 什么是recovery? 减少集群full restart造成的数据来回拷贝 减少主副本之间的数据复制 特大热索引为何恢复慢 什么是recovery? 在elasticsearch中,recovery指的是一个索引的分片分配到另外一个节点的过程,一般在快照恢复.索引复制分片的变更.节点故障或重启时发生,由于master节点保存整个集群相关的状态信息,因此可以判断哪些分片需要再分配及分配到哪个节点,例如: 如果某个主分片在,而复制分片所在的节点挂掉了,那么master需要另行选择一个可用节点
-

elasticsearch索引index数据功能源码示例
从本篇开始,对elasticsearch的介绍将进入数据功能部分(index),这一部分包括索引的创建,管理,数据索引及搜索等相关功能.对于这一部分的介绍,首先对各个功能模块的分析,然后详细分析数据索引和搜索的整个流程. 这一部分从代码包结构上可以分为:index, indices及lucene(common)几个部分.index包中的代码主要是各个功能对应于lucene的底层操作,它们的操作对象是index的shard,是elasticsearch对lucene各个功能的扩展和封装.indic
-
elasticsearch数据信息索引操作action support示例分析
目录 抽象类分析 doExecute方法 performOperation代码 master的相关操作 总结 抽象类分析 Action这一部分主要是数据(索引)的操作和部分集群信息操作. 所有的请求通过client转发到对应的action上然后再由对应的TransportAction来执行相关请求.如果请求能在本机上执行则在本机上执行,否则使用Transport进行转发到对应的节点.action support部分是对action的抽象,所有的具体action都继承了support action
-
Elasticsearch Recovery索引分片分配详解
目录 基础知识点 减少集群Full Restart造成的数据来回拷贝 减少主副本之间的数据复制 特大热索引为何恢复慢 其他Recovery相关的专家级设置 基础知识点 在Eleasticsearch中recovery指的就是一个索引的分片分配到另外一个节点的过程:一般在快照恢复.索引副本数变更.节点故障.节点重启时发生.由于master保存整个集群的状态信息,因此可以判断出哪些shard需要做再分配,以及分配到哪个结点,例如: 如果某个shard主分片在,副分片所在结点挂了,那么选择另外一个可用
-
elasticsearch源码分析index action实现方式
目录 action的作用 TransportAction的类图 OperationTransportHandler的代码 primary操作的方法 总结 action的作用 上一篇从结构上分析了action的,本篇将以index action为例仔分析一下action的实现方式. 再概括一下action的作用:对于每种功能(如index)action都会包括两个基本的类*action(IndexAction)和Transport*action(TransportIndexAction),前者类中
-
elasticsearch索引index之Translog数据功能分析
目录 跟大多数分布式系统一样,es也通过临时写入写操作来保证数据安全.因为lucene索引过程中,数据会首先据缓存在内存中直到达到一个量(文档数或是占用空间大小)才会写入到磁盘.这就会带来一个风险,如果在写入磁盘前系统崩溃,那么这些缓存数据就会丢失.es通过translog解决了这个问题,每次写操作都会写入一个临时文件translog中,这样如果系统需要恢复数据可以从translog中读取.本篇就主要分析translog的结构及写入方式. 这一部分主要包括两部分translog和tanslogF
-
elasticsearch索引index之engine读写控制结构实现
目录 engine的实现结构 Engine类的方法: 如index方法的实现: 总结 engine的实现结构 elasticsearch对于索引中的数据操作如读写get等接口都封装在engine中,同时engine还封装了索引的读写控制,如流量.错误处理等.engine是离lucene最近的一部分. engine的实现结构如下所示: engine接口有三个实现类,主要逻辑都在InternalEngine中. ShadowEngine之实现了engine接口的部分读方法,主要用于对于索引的读操作.
-
elasticsearch索引index之merge底层机制的合并讲解
merge是lucene的底层机制,merge过程会将index中的segment进行合并,生成更大的segment,提高搜索效率.segment是lucene索引的一种存储结构,每个segment都是一部分数据的完整索引,它是lucene每次flush或merge时候形成.每次flush就是将内存中的索引写出一个独立segment的过程.所以随着数据的不断增加,会形成越来越多的segment.因为segment是不可变的,删除操作不会改变segment内部数据,只是会在另外的地方记录某些数据删
-
elasticsearch索引index之Mapping实现关系结构示例
目录 Mapping的实现关系结构 parse方法 部分Field Mapping的实现关系结构 Lucene索引的一个特点就filed,索引以field组合.这一特点为索引和搜索提供了很大的灵活性.elasticsearch则在Lucene的基础上更近一步,它可以是 no scheme.实现这一功能的秘密就Mapping.Mapping是对索引各个字段的一种预设,包括索引与分词方式,是否存储等,数据根据字段名在Mapping中找到对应的配置,建立索引.这里将对Mapping的实现结构简单分析,
-
elasticsearch索引index之put mapping的设置分析
目录 mapping的设置过程 put mapping updateTask响应 总结 mapping的设置过程 mapping机制使得elasticsearch索引数据变的更加灵活,近乎于no schema.mapping可以在建立索引时设置,也可以在后期设置. 后期设置可以是修改mapping(无法对已有的field属性进行修改,一般来说只是增加新的field)或者对没有mapping的索引设置mapping. put mapping操作必须是master节点来完成,因为它涉及到集群mate
-
elasticsearch索引创建create index集群matedata更新
目录 创建索引更新集群index matedata 首先创建index的create方法 从indice中获取对应的IndexService 总结 创建索引更新集群index matedata 创建索引需要创建索引并且更新集群index matedata,这一过程在MetaDataCreateIndexService的createIndex方法中完成.这里会提交一个高优先级,AckedClusterStateUpdateTask类型的task.索引创建需要即时得到反馈,异常这个task需要返回,
-
elasticsearch索引的创建过程index create逻辑分析
目录 索引的创建过程 materOperation方法实现 clusterservice处理 建立索引 修改配置 总结 索引的创建过程 从本篇开始,就进入了Index的核心代码部分.这里首先分析一下索引的创建过程.elasticsearch中的索引是多个分片的集合,它只是逻辑上的索引,并不具备实际的索引功能,所有对数据的操作最终还是由每个分片完成. 创建索引的过程,从elasticsearch集群上来说就是写入索引元数据的过程,这一操作只能在master节点上完成.这是一个阻塞式动作,在加上分配
-
在vue中,v-for的索引index在html中的使用方法
如下所示: 以上这篇在vue中,v-for的索引index在html中的使用方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: vue.js指令v-for使用及索引获取 Vuejs在v-for中,利用index来对第一项添加class的方法 Vue.js常用指令汇总(v-if.v-for等)
-
详解c#索引(Index)和范围(Range)
范围和索引为访问序列中的单个元素或范围提供了简洁的语法. 在本教程中,你将了解: 对某个序列中的范围使用该语法. 了解每个序列开头和末尾的设计决策. 了解 Index 和 Range 类型的应用场景. 对索引和范围的语言支持 此语言支持依赖于两个新类型和两个新运算符: System.Index 表示一个序列索引. 来自末尾运算符 ^ 的索引,指定一个索引与序列末尾相关. System.Range 表示序列的子范围. 范围运算符 ..,用于指定范围的开始和末尾,就像操作数一样. 让我们从索引规则开