聊聊Python对CSV文件的读取与写入问题
今天天气"刚刚好"(薛之谦么么哒),无聊的我翻到了一篇关于csv文件读取与写入的帖子,作为测试小白的我一直对python情有独钟,顿时心血来潮,决定小搞他一下,分享给那些需要的小白,对于python大神们来说,简直就是小儿科,对于我这种测试小白,看到代码就如同打了鸡血一样,恩恩,好东西,好东西!
csv文件的读取:
前期工作:在定义的py文件里边创建一个excel文件,并另存为csv文件,放入三行数据,我这里是姓名+年龄(可以自己随意写)
首先我们要在python环境里导入csv板块(测试小白的我喜欢用pycharm)

然后我们定义一个csv文件的变量csv_file,然后通过open对此文件进行打开,打开模式采用‘r'(read:读模式),这里不懂的各位小白白可以百度下文件的访问模式
如下图所示:

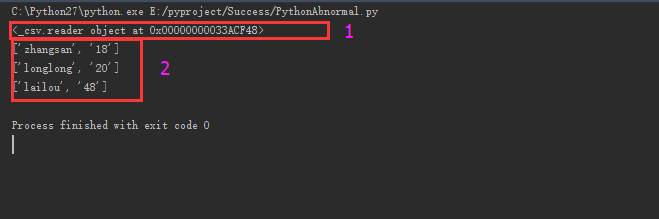
图中打印出来的csv_file只是一个对象的模型(如图中的1),我们需要对这个模型进行遍历打印,通过打印我们可以清晰的看到我们打印的数据
csv文件的写入:
通过上面我们可以对csv的文件进行了读取,各位小白们有没有感觉很简单呢(我当时乐开花了),下面我们就讲一下csv的读取
在开始前我们要定义两组数据,进行下面的写入
stu1 = ['marry',26] stu2 = ['bob',23]
1.写入的第一步同样也是打开文件,因为我们是要写入,所以我们用的模式就是 'a' 模式,追加内容,至于"newline="就是说因为我们的csv文件的类型,如果不加这个东西,当我们写入东西的时候,就会出现空行,这个大家可以尝试着不加试试一下,也可以"老乌龟的屁股"(规定)
out = open('Stu_csv.csv','a', newline='')
2.下面我们定义一个变量进行写入,将刚才的文件变量传进来,dialect就是定义一下文件的类型,我们定义为excel类型
csv_write = csv.writer(out,dialect='excel')
3.然后进行数据的写入啦,啦啦啦,终于要结束了,写入的方法是writerow,通过写入模式对象,调用方法进行写入
csv_write.writerow(stu1) csv_write.writerow(stu2)
4.最后各位小白可以用你们最熟悉的一句语法进行漂亮的收尾,66666
print ("write over")
具体的代码如下:
import csv
#csv 写入
stu1 = ['marry',26]
stu2 = ['bob',23]
#打开文件,追加a
out = open('Stu_csv.csv','a', newline='')
#设定写入模式
csv_write = csv.writer(out,dialect='excel')
#写入具体内容
csv_write.writerow(stu1)
csv_write.writerow(stu2)
print ("write over")
执行结果:
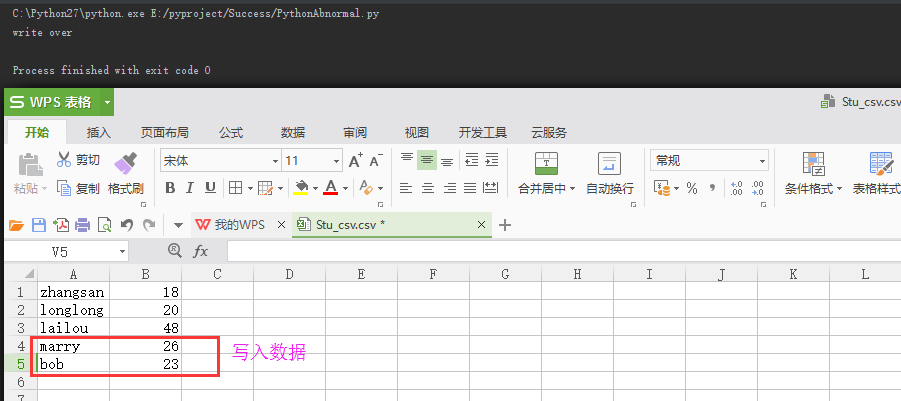
到此这篇关于Python对于CSV文件的读取与写入的文章就介绍到这了,更多相关Python CSV文件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python读取csv文件分隔符设置方法
Windows下的分隔符默认的是逗号,而MAC的分隔符是分号.拿到一份用分号分割的CSV文件,在Win下是无法正确读取的,因为CSV模块默认调用的是Excel的规则. 所以我们在读取文件的时候需要添加分割符变量. import csv import os cwd = os.getcwd() print ("Current folder is %s" % (cwd) ) csvfile = open( cwd + '\data\eclipse\change-metrics.csv','r
-

Python实现序列化及csv文件读取
这篇文章主要介绍了Python实现序列化及csv文件读取,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.python 序列化: 序列化指的是将对象转化为"串行化"数据形式,存储到硬盘或通过网路传输到其他地方,反序列化是指相反的过程,将读取到串行化数据转化成对象.使用pickle模块中的函数,实现序列化和反序列化操作. 序列化使用: pickle.dump(obj,file) obj是被序列化的对象,file指的是存储的文件. pi
-
Python实现读取及写入csv文件的方法示例
本文实例讲述了Python实现读取及写入csv文件的方法.分享给大家供大家参考,具体如下: 新建csvData.csv文件,数据如下: 具体代码如下: # coding:utf-8 import csv # 读取csv文件方式1 csvFile = open("csvData.csv", "r") reader = csv.reader(csvFile) # 返回的是迭代类型 data = [] for item in reader: print(item) dat
-
python读取当前目录下的CSV文件数据
在处理数据的时候,经常会碰到CSV类型的文件,下面将介绍如何读取当前目录下的CSV文件,步骤如下 1.获取当前目录所有的CSV文件名称: #创建一个空列表,存储当前目录下的CSV文件全称 file_name = [] #获取当前目录下的CSV文件名 def name(): #将当前目录下的所有文件名称读取进来 a = os.listdir() for j in a: #判断是否为CSV文件,如果是则存储到列表中 if os.path.splitext(j)[1] == '.csv': file_
-
教你用Python读取CSV文件的5种方式
目录 第一招:简单的读取 第二招:用nametuple 第三招:用tuple类型转换 第四招:用DictReader 第五招:用字典转换 典型的数据集stocks.csv: 一个股票的数据集,其实就是常见的表格数据.有股票代码,价格,日期,时间,价格变动和成交量.这个数据集其实就是一个表格数据,有自己的头部和身体. 第一招:简单的读取 我们先来看一种简单读取方法,先用csv.reader()函数读取文件的句柄f生成一个csv的句柄,其实就是一个迭代器,我们看一下这个reader的源码: 喂给re
-
使用python读取csv文件快速插入数据库的实例
如下所示: # -*- coding:utf-8 -*- # auth:ckf # date:20170703 import pandas as pd import cStringIO import warnings from sqlalchemy import create_engine import sys reload(sys) sys.setdefaultencoding('utf8') warnings.filterwarnings('ignore') engine = create_
-
Python读取csv文件实例解析
这篇文章主要介绍了Python读取csv文件实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 创建一个csv文件,命名为data.csv,文本内容如下: root,123456,login successfully root,wrong,wrong password wrong,123456,nonexistent username ,123456,username is null root,,password is null 使用Exc
-
python读取csv文件指定行的2种方法详解
csv是Comma-Separated Values的缩写,是用文本文件形式储存的表格数据,比如如下的表格 就可以存储为csv文件,文件内容是: No.,Name,Age,Score 1,Apple,12,98 2,Ben,13,97 3,Celia,14,96 4,Dave,15,95 假设上述csv文件保存为"A.csv",如何用Python像操作Excel一样提取其中的一行,也就是一条记录,利用Python自带的csv模块,有2种方法可以实现: 方法一:reader 第一种方法使
-
聊聊Python对CSV文件的读取与写入问题
今天天气"刚刚好"(薛之谦么么哒),无聊的我翻到了一篇关于csv文件读取与写入的帖子,作为测试小白的我一直对python情有独钟,顿时心血来潮,决定小搞他一下,分享给那些需要的小白,对于python大神们来说,简直就是小儿科,对于我这种测试小白,看到代码就如同打了鸡血一样,恩恩,好东西,好东西! csv文件的读取: 前期工作:在定义的py文件里边创建一个excel文件,并另存为csv文件,放入三行数据,我这里是姓名+年龄(可以自己随意写) 首先我们要在python环境里导入csv板块(
-
Python从csv文件中读取数据及提取数据的方法
目录 1.从csv文件中读取数据 2.数据切割 数据保存在csv文件中 1.从csv文件中读取数据 参数header=None的有无 (1)没有header=None--直接将csv表中的第一行当作表头 # 读取数据 import pandas as pd data = pd.read_csv("data1.csv") print(data) 打印结果为: (2)有header=None--自动添加第一行当作表头 # 读取数据 import pandas as pd data = pd
-
Python 文本文件与csv文件的读取与写入
目录 一.文本文件读取与写入 1读取文件的read()方法 2读取文件的readline()方法 3读取文件的readlines()方法 4写入文件的write()方法 5写入文件的writelines()方法 二.csv文件读取与写入 一.文本文件读取与写入 1 读取文件的 read() 方法 file_object.read([size]) file_object 表示文件对象 size 表示读取数据的长度,单位是字节,如果size省略则读至文件尾 返回值是读取到的字符串 2 读取文件的 r
-
Python 文本文件与csv文件的读取与写入
目录 一.文本文件读取与写入 1 读取文件的 read() 方法 2 读取文件的 readline() 方法 3 读取文件的 readlines() 方法 4 写入文件的 write() 方法 5 写入文件的 writelines() 方法 二.csv文件读取与写入 一.文本文件读取与写入 1 读取文件的 read() 方法 file_object.read([size]) file_object 表示文件对象 size 表示读取数据的长度,单位是字节,如果size省略则读至文件尾 返回值是读取
-
Python基于csv模块实现读取与写入csv数据的方法
本文实例讲述了Python基于csv模块实现读取与写入csv数据的方法.分享给大家供大家参考,具体如下: 通过csv模块可以轻松读取格式为csv的文件,而且csv模块是python内置的,不需要下载就可以直接用. 一.准备csv文件 文件名是 e:\t.csv,文件内容: org_id,org_name,state,emp_id 1,销售1,'1',123 2,销售2,'0',321 3,销售3,'1',231 1,,'1',1234 二.读取csv数据 代码非常简单: # -*- coding
-
使用Python对Dicom文件进行读取与写入的实现
Pydicom 单张影像的读取 使用 pydicom.dcmread() 函数进行单张影像的读取,返回一个pydicom.dataset.FileDataset对象. import os import pydicom # 调用本地的 dicom file folder_path = r"D:\Files\Data\Materials" file_name = "PA1_0001.dcm" file_path = os.path.join(folder_path,fi
-
python读写csv文件实例代码
Python读取与写入CSV文件需要导入Python自带的CSV模块,然后通过CSV模块中的函数csv.reader()与csv.writer()来进行CSV文件的读取与写入. 写入CSV文件 import csv # 需要import csv的文件包 out=open("aa.csv",'wb') # 注意这里如果以'w'的形式打开,每次写入的数据中间就会多一个空行,所以要用'wb' csv_write=csv.write(out,dialect='excel') # 下面进行具体的
-
python导入csv文件出现SyntaxError问题分析
背景 np.loadtxt()用于从文本加载数据. 文本文件中的每一行必须含有相同的数据. *** loadtxt(fname,dtype=<class'float'>,comments='#',delimiter=None,converters=None,skiprows=0,usecols=None,unpack=False,ndmin=0) fname要读取的文件.文件名.或生成器. dtype数据类型,默认float. comments注释. delimiter分隔符,默认是空格. s
-
Python中文件的读取和写入操作
从文件中读取数据 读取整个文件 这里假设在当前目录下有一个文件名为'pi_digits.txt'的文本文件,里面的数据如下: 3.1415926535 8979323846 2643383279 with open('pi_digits.txt') as f: # 默认模式为'r',只读模式 contents = f.read() # 读取文件全部内容 print contents # 输出时在最后会多出一行(read()函数到达文件末会返回一个空字符,显示出空字符就是一个空行) print '
-
python读csv文件时指定行为表头或无表头的方法
pd.read_csv()方法中header参数,默认为0,标签为0(即第1行)的行为表头.若设置为-1,则无表头.示例如下: (1)不设置header参数(默认)时: df1 = pd.read_csv('target.csv',encoding='utf-8') df1 (2)header=1时: import pandas as pd df2 = pd.read_csv('target.csv',encoding='utf-8',header=1) df2 (3)header=-1时(可用