Node.js+jade抓取博客所有文章生成静态html文件的实例
这篇文章,我们就把上文中采集到的所有文章列表的信息整理一下,开始采集文章并且生成静态html文件了.先看下我的采集效果,我的博客目前77篇文章,1分钟不到就全部采集生成完毕了,这里我截了部分的图片,文件名用文章的id生成的,生成的文章,我写了一个简单的静态模板,所有的文章都是根据这个模板生成的.
项目结构:


好了,接下来,我们就来讲解下,这篇文章主要实现的功能:
1,抓取文章,主要抓取文章的标题,内容,超链接,文章id(用于生成静态html文件)
2,根据jade模板生成html文件
一、抓取文章如何实现?
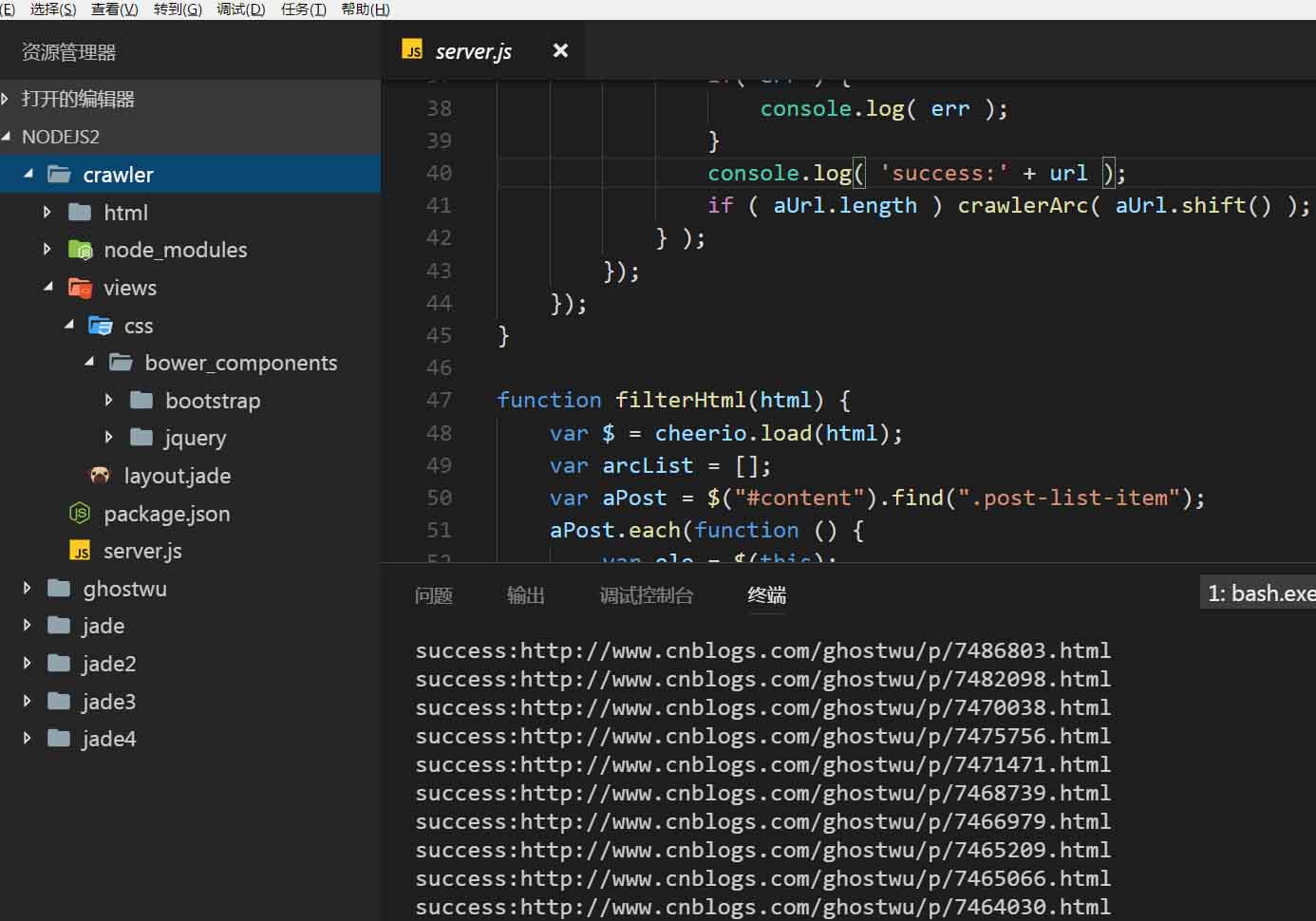
非常简单,跟上文抓取文章列表的实现差不多
function crawlerArc( url ){
var html = '';
var str = '';
var arcDetail = {};
http.get(url, function (res) {
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
arcDetail = filterArticle( html );
str = jade.renderFile('./views/layout.jade', arcDetail );
fs.writeFile( './html/' + arcDetail['id'] + '.html', str, function( err ){
if( err ) {
console.log( err );
}
console.log( 'success:' + url );
if ( aUrl.length ) crawlerArc( aUrl.shift() );
} );
});
});
}
参数url就是文章的地址,把文章的内容抓取完毕之后,调用filterArticle( html ) 过滤出需要的文章信息(id, 标题,超链接,内容),然后用jade的renderFile这个api,实现模板内容的替换,
模板内容替换完之后,肯定就需要生成html文件了, 所以用writeFile写入文件,写入文件时候,用id作为html文件名称。这就是生成一篇静态html文件的实现,
接下来就是循环生成静态html文件了, 就是下面这行:
if ( aUrl.length ) crawlerArc( aUrl.shift() );
aUrl保存的是我的博客所有文章的url, 每次采集完一篇文章之后,就把当前文章的url删除,让下一篇文章的url出来,继续采集
完整的实现代码server.js:
var fs = require( 'fs' );
var http = require( 'http' );
var cheerio = require( 'cheerio' );
var jade = require( 'jade' );
var aList = [];
var aUrl = [];
function filterArticle(html) {
var $ = cheerio.load( html );
var arcDetail = {};
var title = $( "#cb_post_title_url" ).text();
var href = $( "#cb_post_title_url" ).attr( "href" );
var re = /\/(\d+)\.html/;
var id = href.match( re )[1];
var body = $( "#cnblogs_post_body" ).html();
return {
id : id,
title : title,
href : href,
body : body
};
}
function crawlerArc( url ){
var html = '';
var str = '';
var arcDetail = {};
http.get(url, function (res) {
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
arcDetail = filterArticle( html );
str = jade.renderFile('./views/layout.jade', arcDetail );
fs.writeFile( './html/' + arcDetail['id'] + '.html', str, function( err ){
if( err ) {
console.log( err );
}
console.log( 'success:' + url );
if ( aUrl.length ) crawlerArc( aUrl.shift() );
} );
});
});
}
function filterHtml(html) {
var $ = cheerio.load(html);
var arcList = [];
var aPost = $("#content").find(".post-list-item");
aPost.each(function () {
var ele = $(this);
var title = ele.find("h2 a").text();
var url = ele.find("h2 a").attr("href");
ele.find(".c_b_p_desc a").remove();
var entry = ele.find(".c_b_p_desc").text();
ele.find("small a").remove();
var listTime = ele.find("small").text();
var re = /\d{4}-\d{2}-\d{2}\s*\d{2}[:]\d{2}/;
listTime = listTime.match(re)[0];
arcList.push({
title: title,
url: url,
entry: entry,
listTime: listTime
});
});
return arcList;
}
function nextPage( html ){
var $ = cheerio.load(html);
var nextUrl = $("#pager a:last-child").attr('href');
if ( !nextUrl ) return getArcUrl( aList );
var curPage = $("#pager .current").text();
if( !curPage ) curPage = 1;
var nextPage = nextUrl.substring( nextUrl.indexOf( '=' ) + 1 );
if ( curPage < nextPage ) crawler( nextUrl );
}
function crawler(url) {
http.get(url, function (res) {
var html = '';
res.on('data', function (chunk) {
html += chunk;
});
res.on('end', function () {
aList.push( filterHtml(html) );
nextPage( html );
});
});
}
function getArcUrl( arcList ){
for( var key in arcList ){
for( var k in arcList[key] ){
aUrl.push( arcList[key][k]['url'] );
}
}
crawlerArc( aUrl.shift() );
}
var url = 'http://www.cnblogs.com/ghostwu/';
crawler( url );
layout.jade文件:
doctype html
html
head
meta(charset='utf-8')
title jade+node.js express
link(rel="stylesheet", href='./css/bower_components/bootstrap/dist/css/bootstrap.min.css')
body
block header
div.container
div.well.well-lg
h3 ghostwu的博客
p js高手之路
block container
div.container
h3
a(href="#{href}" rel="external nofollow" ) !{title}
p !{body}
block footer
div.container
footer 版权所有 - by ghostwu
后续的打算:
1,采用mongodb入库
2,支持断点采集
3,采集图片
4,采集小说
等等....
以上这篇Node.js+jade抓取博客所有文章生成静态html文件的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Nodejs抓取html页面内容(推荐)
废话不多说,直接给大家贴node.js抓取html页面内容的核心代码了. 具体代码如下所示: var http = require("http"); var iconv = require('iconv-lite'); var option = { hostname: "stockdata.stock.hexun.com", path: "/gszl/s601398.shtml" }; var req = http.request(option,
-

Node.js+jade抓取博客所有文章生成静态html文件的实例
这篇文章,我们就把上文中采集到的所有文章列表的信息整理一下,开始采集文章并且生成静态html文件了.先看下我的采集效果,我的博客目前77篇文章,1分钟不到就全部采集生成完毕了,这里我截了部分的图片,文件名用文章的id生成的,生成的文章,我写了一个简单的静态模板,所有的文章都是根据这个模板生成的. 项目结构: 好了,接下来,我们就来讲解下,这篇文章主要实现的功能: 1,抓取文章,主要抓取文章的标题,内容,超链接,文章id(用于生成静态html文件) 2,根据jade模板生成html文件 一.抓取文
-
利用正则表达式抓取博客园列表数据
鉴于我在要完成的asp.net MVC 3 仿照博客园企业系统要用到测试数据,我自己输入太累,所以我就抓取了博客园的部分列表数据,还请dudu不要见怪. 在抓取博客园数据的时候采用了正则表达式,所以有不熟悉正则表达式的朋友可以参考相关资料,其实很容易掌握,就是在具体的实例中会花些时间. 现在我就来把我抓取博客园数据的过程叙述一下,如果有朋友有更好的意见,欢迎提出来. 要使用正则表达式抓取数据,首先就要创建一个正则表达式进行匹配,我推荐使用regulator,这个正则表达式工具,我们可以先使用这个
-
利用Vue.js+Node.js+MongoDB实现一个博客系统(附源码)
前言 这篇文章实现的博客系统使用 Vue 做前端框架,Node + express 做后端,数据库使用的是 MongoDB.实现了用户注册.用户登录.博客管理(文章的修改和删除).文章编辑(Markdown).标签分类等功能. 前端模仿的是 hexo 的经典主题 NexT,本来是想把源码直接拿过来用的,后来发现还不如自己写来得快,就全部自己动手实现成 vue components. 实现的功能 1.文章的编辑,修改,删除 2.支持使用 Markdown 编辑与实时预览 3.支持代码高亮 4.给文
-
[将免费进行到底]在Amazon的一年免费服务器上安装Node.JS, NPM和OurJS博客
这里选用的操作系统是社区版Debian,Debian和Ubuntu的操作指令是一脉相承的,再加上之前玩过一段时间的Raspberry PI,个人比较熟悉,以下的安装过程其实同样适用于树霉派(安装node.js和NPM那一部分). 1) 注册并选型 在aws上注册并绑定信号卡后即可使用亚马逊的一年免费EC2主机,不过配置通常比较低,通常为0.612Mb(linux)和1G(Win)内存. http://aws.amazon.com/ 这里选用的是社区版Debian的版本是 Debian-squee
-
利用Node.js批量抓取高清妹子图片实例教程
前言 写了一个抓取图片的小玩意,分享一下. Github地址:https://github.com/focalhot/node.js-crawler (本地下载) 示例代码 //依赖模块 var fs = require('fs'); var request = require("request"); var cheerio = require("cheerio"); var mkdirp = require('mkdirp'); //目标网址 var url =
-
使用HtmlAgilityPack XPath 表达式抓取博客园数据的实现代码
Web 前端代码 复制代码 代码如下: <%@ Page Language="C#" AutoEventWireup="true" CodeFile="Default.aspx.cs" Inherits="_Default" %> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.
-
基于JQuery的抓取博客园首页RSS的代码
效果图:实现代码: 复制代码 代码如下: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http
-
Node.js+jade+mongodb+mongoose实现爬虫分离入库与生成静态文件的方法
接着这篇文章Node.js+jade抓取博客所有文章生成静态html文件的实例继续,在这篇文章中实现了采集与静态文件的生成,在实际的采集项目中, 应该是先入库再选择性的生成静态文件. 那么我选择的数据库是mongodb,为什么用这个数据库,因为这个数据库是基于集合,数据的操作基本是json,与dom模块cheerio具有非常大的亲和力,cheerio处理过滤出来的数据,可以直接插入mongodb,不需要经过任何的处理,非常的便捷,当然跟node.js的亲和力那就不用说了,更重要的是,性能很棒.这
-
JS实现新浪博客左侧的Blog管理菜单效果代码
本文实例讲述了JS实现新浪博客左侧的Blog管理菜单效果代码.分享给大家供大家参考,具体如下: 这里介绍新浪博客左侧的Blog管理菜单,我们变通一下,如果你在设计程序,那么本款菜单用到后台管理中想必应该很合适吧,图片是调用新浪的,用了比较多的图片,你用的时候最好是下载到本地,以免新浪哪天改版了,你就傻了. 运行效果截图如下: 在线演示地址如下: http://demo.jb51.net/js/2015/js-sina-blog-left-menu-style-codes/ 具体代码如下: <ht
-
详解Python爬虫爬取博客园问题列表所有的问题
一.准备工作 首先,本文使用的技术为 python+requests+bs4,没有了解过可以先去了解一下. 我们的需求是将博客园问题列表中的所有问题的题目爬取下来. 二.分析: 首先博客园问题列表页面右键点击检查 通过Element查找问题所对应的属性或标签 可以发现在div class ="one_entity"中存在页面中分别对应每一个问题 接着div class ="news_item"中h2标签下是我们想要拿到的数据 三.代码实现 首先导入requests和