Python爬虫的两套解析方法和四种爬虫实现过程
对于大多数朋友而言,爬虫绝对是学习 python 的最好的起手和入门方式。因为爬虫思维模式固定,编程模式也相对简单,一般在细节处理上积累一些经验都可以成功入门。本文想针对某一网页对 python 基础爬虫的两大解析库( BeautifulSoup 和 lxml )和几种信息提取实现方法进行分析,以开 python 爬虫之初见。
基础爬虫的固定模式
笔者这里所谈的基础爬虫,指的是不需要处理像异步加载、验证码、代理等高阶爬虫技术的爬虫方法。一般而言,基础爬虫的两大请求库 urllib 和 requests 中 requests 通常为大多数人所钟爱,当然 urllib 也功能齐全。两大解析库 BeautifulSoup 因其强大的 HTML 文档解析功能而备受青睐,另一款解析库 lxml 在搭配 xpath 表达式的基础上也效率提高。就基础爬虫来说,两大请求库和两大解析库的组合方式可以依个人偏好来选择。
笔者喜欢用的爬虫组合工具是:
- requests + BeautifulSoup
- requests + lxml
同一网页爬虫的四种实现方式
笔者以腾讯新闻首页的新闻信息抓取为例。
首页外观如下:

比如说我们想抓取每个新闻的标题和链接,并将其组合为一个字典的结构打印出来。首先查看 HTML 源码确定新闻标题信息组织形式。
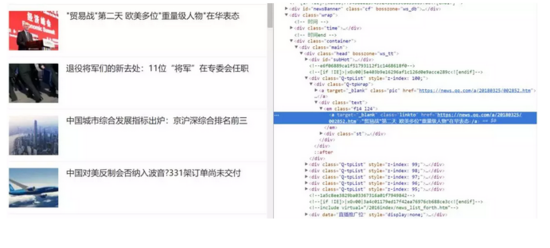
可以目标信息存在于 em 标签下 a 标签内的文本和 href 属性中。可直接利用 requests 库构造请求,并用 BeautifulSoup 或者 lxml 进行解析。
方式一: requests + BeautifulSoup + select css选择器
# select method
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}
url = 'http://news.qq.com/'
Soup = BeautifulSoup(requests.get(url=url, headers=headers).text.encode("utf-8"), 'lxml')
em = Soup.select('em[class="f14 l24"] a')
for i in em:
title = i.get_text()
link = i['href']
print({'标题': title,
'链接': link
})
很常规的处理方式,抓取效果如下:

方式二: requests + BeautifulSoup + find_all 进行信息提取
# find_all method
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}
url = 'http://news.qq.com/'
Soup = BeautifulSoup(requests.get(url=url, headers=headers).text.encode("utf-8"), 'lxml')
em = Soup.find_all('em', attrs={'class': 'f14 l24'})for i in em:
title = i.a.get_text()
link = i.a['href']
print({'标题': title,
'链接': link
})
同样是 requests + BeautifulSoup 的爬虫组合,但在信息提取上采用了 find_all 的方式。效果如下:

方式三: requests + lxml/etree + xpath 表达式
# lxml/etree method
import requests
from lxml import etree
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}
url = 'http://news.qq.com/'
html = requests.get(url = url, headers = headers)
con = etree.HTML(html.text)
title = con.xpath('//em[@class="f14 l24"]/a/text()')
link = con.xpath('//em[@class="f14 l24"]/a/@href')
for i in zip(title, link):
print({'标题': i[0],
'链接': i[1]
})
使用 lxml 库下的 etree 模块进行解析,然后使用 xpath 表达式进行信息提取,效率要略高于 BeautifulSoup + select 方法。这里对两个列表的组合采用了 zip 方法。python学习交流群:125240963效果如下:

方式四: requests + lxml/html/fromstring + xpath 表达式
# lxml/html/fromstring method
import requests
import lxml.html as HTML
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}
url = 'http://news.qq.com/'
con = HTML.fromstring(requests.get(url = url, headers = headers).text)
title = con.xpath('//em[@class="f14 l24"]/a/text()')
link = con.xpath('//em[@class="f14 l24"]/a/@href')
for i in zip(title, link):
print({'标题': i[0],'链接': i[1]
})
跟方法三类似,只是在解析上使用了 lxml 库下的 html.fromstring 模块。抓取效果如下:

很多人觉得爬虫有点难以掌握,因为知识点太多,需要懂前端、需要python熟练、还需要懂数据库,更不用说正则表达式、XPath表达式这些。其实对于一个简单网页的数据抓取,不妨多尝试几种抓取方案,举一反三,也更能对python爬虫有较深的理解。长此以往,对于各类网页结构都有所涉猎,自然经验丰富,水到渠成。
总结
以上所述是小编给大家介绍的Python爬虫的两套解析方法和四种爬虫实现过程,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-

python中数据爬虫requests库使用方法详解
一.什么是Requests Requests 是Python语编写,基于urllib,采Apache2 Licensed开源协议的 HTTP 库.它urllib 更加方便,可以节约我们大量的工作,完全满足HTTP测试需求. 一句话--requests是python实现的简单易用的HTTP库 二.安装Requests库 进入命令行win+R执行 命令:pip install requests 项目导入:import requests 三.各种请求方式 直接上代码,不明白可以查看我的urllib的基
-
Python网络爬虫与信息提取(实例讲解)
课程体系结构: 1.Requests框架:自动爬取HTML页面与自动网络请求提交 2.robots.txt:网络爬虫排除标准 3.BeautifulSoup框架:解析HTML页面 4.Re框架:正则框架,提取页面关键信息 5.Scrapy框架:网络爬虫原理介绍,专业爬虫框架介绍 理念:The Website is the API ... Python语言常用的IDE工具 文本工具类IDE: IDLE.Notepad++.Sublime Text.Vim & Emacs.Atom.Komodo E
-
基于python实现的抓取腾讯视频所有电影的爬虫
我搜集了国内10几个电影网站的数据,里面近几十W条记录,用文本没法存,mongodb学习成本非常低,安装.下载.运行起来不会花你5分钟时间. # -*- coding: utf-8 -*- # by awakenjoys. my site: www.dianying.at import re import urllib2 from bs4 import BeautifulSoup import string, time import pymongo NUM = 0 #全局变量,电影数量 m_ty
-
Python 通过requests实现腾讯新闻抓取爬虫的方法
最近也是学习了一些爬虫方面的知识.以我自己的理解,通常我们用浏览器查看网页时,是通过浏览器向服务器发送请求,然后服务器响应以后返回一些代码数据,再经过浏览器解析后呈现出来.而爬虫则是通过程序向服务器发送请求,并且将服务器返回的信息,通过一些处理后,就能得到我们想要的数据了. 以下是前段时间我用python写的一个爬取TX新闻标题及其网址的一个简单爬虫: 首先需要用到python中requests(方便全面的http请求库)和 BeautifulSoup(html解析库). 通过pip来安装这两个
-
Python使用requests及BeautifulSoup构建爬虫实例代码
本文研究的主要是Python使用requests及BeautifulSoup构建一个网络爬虫,具体步骤如下. 功能说明 在Python下面可使用requests模块请求某个url获取响应的html文件,接着使用BeautifulSoup解析某个html. 案例 假设我要http://maoyan.com/board/4猫眼电影的top100电影的相关信息,如下截图: 获取电影的标题及url. 安装requests和BeautifulSoup 使用pip工具安装这两个工具. pip install
-
Python爬虫的两套解析方法和四种爬虫实现过程
对于大多数朋友而言,爬虫绝对是学习 python 的最好的起手和入门方式.因为爬虫思维模式固定,编程模式也相对简单,一般在细节处理上积累一些经验都可以成功入门.本文想针对某一网页对 python 基础爬虫的两大解析库( BeautifulSoup 和 lxml )和几种信息提取实现方法进行分析,以开 python 爬虫之初见. 基础爬虫的固定模式 笔者这里所谈的基础爬虫,指的是不需要处理像异步加载.验证码.代理等高阶爬虫技术的爬虫方法.一般而言,基础爬虫的两大请求库 urllib 和
-
php解析xml 的四种简单方法(附实例)
XML处理是开发过程中经常遇到的,PHP对其也有很丰富的支持,本文只是对其中某几种解析技术做简要说明,包括:Xml parser, SimpleXML, XMLReader, DOMDocument. 1. XML Expat Parser: XML Parser使用Expat XML解析器.Expat是一种基于事件的解析器,它把XML文档视为一系列事件.当某个事件发生时,它调用一个指定的函数处理它.Expat是无验证的解析器,忽略任何链接到文档的DTD.但是,如果文档的形式不好,则会以一个错误
-
php 解析xml 的四种方法详细介绍
php 解析xml 的四种方法 XML处理是开发过程中经常遇到的,PHP对其也有很丰富的支持,本文只是对其中某几种解析技术做简要说明,包括:Xml parser, SimpleXML, XMLReader, DOMDocument. 1. XML Expat Parser: XML Parser使用Expat XML解析器.Expat是一种基于事件的解析器,它把XML文档视为一系列事件.当某个事件发生时,它调用一个指定的函数处理它.Expat是无验证的解析器,忽略任何链接到文档的DTD.但是,如
-
Python字典删除键值对和元素的四种方法(小结)
目录 1.del删除字典本身 2.pop()删除字典键值对 3.popitem()删除字典键值对 4.clear()删除字典键值对:清空字典中的所有内容,但是不删除字典本身,del删除字典本身 在删除每个字典的时候有些方法和删除其他拥有独立内存的数据使用的方法是一样的,比如del,直接清空内存,clear()是值清除变量值.字典的删除我们从字典对象本身和字典中的键值对两个方面出发,来学习一下. 1.del删除字典本身 del就是从内存级别删除字典本身,让这个字典对象彻底消失.同时也可以删除字典
-
Python中字典(dict)合并的四种方法总结
本文主要给大家介绍了关于Python中字典(dict)合并的四种方法,分享出来供大家参考学习,话不多说了,来一起看看详细的介绍: 字典是Python语言中唯一的映射类型. 映射类型对象里哈希值(键,key)和指向的对象(值,value)是一对多的的关系,通常被认为是可变的哈希表. 字典对象是可变的,它是一个容器类型,能存储任意个数的Python对象,其中也可包括其他容器类型. 字典类型与序列类型的区别: 1. 存取和访问数据的方式不同. 2. 序列类型只用数字类型的键(从序列的开始按数值顺序索引
-
Python获取当前页面内所有链接的四种方法对比分析
本文实例讲述了Python获取当前页面内所有链接的四种方法.分享给大家供大家参考,具体如下: ''' 得到当前页面所有连接 ''' import requests import re from bs4 import BeautifulSoup from lxml import etree from selenium import webdriver url = 'http://www.testweb.com' r = requests.get(url) r.encoding = 'gb2312'
-
Java 不使用第三方变量交换两个变量值的四种方法详解
目录 变量本身交换数值 算术运算 指针地址操作 位运算 简单总结 哈喽,大家好,我是阿Q.前几天有个小伙伴去面试,被面试官的一个问题劝退了:请说出几种不使用第三方变量交换两个变量值的方法. 问题有点绕,好不容易缕清了面试官的问题,却发现答不上来.一时间尴尬无比,只能硬着头皮说不会. 遇到交换变量值的问题,通常我们的做法是:定义一个新的变量,借助它完成交换. 代码如下: t = a; a = b; b = t; 但问题的重点是"不使用第三方变量",那就变得"可爱"起来
-
基于node.js依赖express解析post请求四种数据格式
node.js依赖express解析post请求四种数据格式 分别是这四种: www-form-urlencoded form-data application/json text/xml 1.www-form-urlencoded 这是http的post请求默认的数据格式,需要body-parser中间件的支持 服务器端的demo: var express = require('express'); var app = express(); var bodyParser = require('
-
springboot启动前执行方法的四种方式总结
目录 第一种 @PostConstruct注解 第二种 实现InitializingBean接口 第三种 实现BeanPostProcessor接口 第四种 在启动类run之前执行方法 总结 第一种 @PostConstruct注解 @Configuration public class Test1 { @Autowired private Environment environment; @PostConstruct public void test(){ String propert
-
Java解析XML的四种方式
xml文件 <?xml version="1.0" encoding="utf-8" ?> <class> <student> <firstname>cxx1</firstname> <lastname>Bob1</lastname> <nickname>stars1</nickname> <marks>85</marks> </