用Python实现BP神经网络(附代码)
用Python实现出来的机器学习算法都是什么样子呢? 前两期线性回归及逻辑回归项目已发布(见文末链接),今天来讲讲BP神经网络。
BP神经网络
全部代码
https://github.com/lawlite19/MachineLearning_Python/blob/master/NeuralNetwok/NeuralNetwork.py
神经网络model
先介绍个三层的神经网络,如下图所示
输入层(input layer)有三个units(
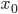
为补上的bias,通常设为1)
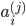
表示第j层的第i个激励,也称为为单元unit
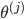
为第j层到第j+1层映射的权重矩阵,就是每条边的权重
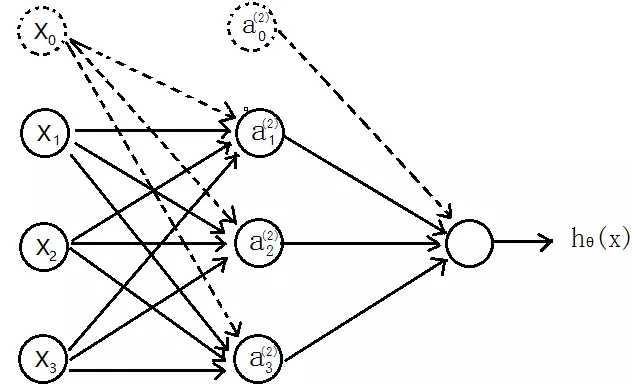
所以可以得到:
隐含层:
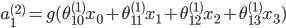
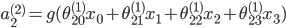
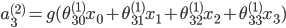
输出层
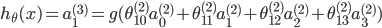
,
其中,S型函数

,也成为激励函数
可以看出
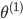
为3x4的矩阵,
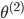
为1x4的矩阵
==》j+1的单元数x(j层的单元数+1)
代价函数
假设最后输出的
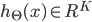
,即代表输出层有K个单元
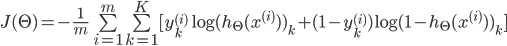
,
其中,
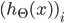
代表第i个单元输出与逻辑回归的代价函数
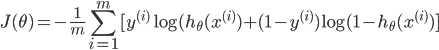
差不多,就是累加上每个输出(共有K个输出)
正则化
L-->所有层的个数
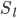
-->第l层unit的个数
正则化后的代价函数为
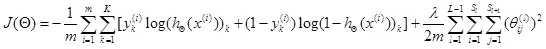
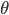
共有L-1层,然后是累加对应每一层的theta矩阵,注意不包含加上偏置项对应的theta(0)
正则化后的代价函数实现代码:
# 代价函数
def nnCostFunction(nn_params,input_layer_size,hidden_layer_size,num_labels,X,y,Lambda):
length = nn_params.shape[0] # theta的中长度
# 还原theta1和theta2
Theta1 = nn_params[0:hidden_layer_size*(input_layer_size+1)].reshape(hidden_layer_size,input_layer_size+1)
Theta2 = nn_params[hidden_layer_size*(input_layer_size+1):length].reshape(num_labels,hidden_layer_size+1)
# np.savetxt("Theta1.csv",Theta1,delimiter=',')
m = X.shape[0]
class_y = np.zeros((m,num_labels)) # 数据的y对应0-9,需要映射为0/1的关系
# 映射y
for i in range(num_labels):
class_y[:,i] = np.int32(y==i).reshape(1,-1) # 注意reshape(1,-1)才可以赋值
'''去掉theta1和theta2的第一列,因为正则化时从1开始'''
Theta1_colCount = Theta1.shape[1]
Theta1_x = Theta1[:,1:Theta1_colCount]
Theta2_colCount = Theta2.shape[1]
Theta2_x = Theta2[:,1:Theta2_colCount]
# 正则化向theta^2
term = np.dot(np.transpose(np.vstack((Theta1_x.reshape(-1,1),Theta2_x.reshape(-1,1)))),np.vstack((Theta1_x.reshape(-1,1),Theta2_x.reshape(-1,1))))
'''正向传播,每次需要补上一列1的偏置bias'''
a1 = np.hstack((np.ones((m,1)),X))
z2 = np.dot(a1,np.transpose(Theta1))
a2 = sigmoid(z2)
a2 = np.hstack((np.ones((m,1)),a2))
z3 = np.dot(a2,np.transpose(Theta2))
h = sigmoid(z3)
'''代价'''
J = -(np.dot(np.transpose(class_y.reshape(-1,1)),np.log(h.reshape(-1,1)))+np.dot(np.transpose(1-class_y.reshape(-1,1)),np.log(1-h.reshape(-1,1)))-Lambda*term/2)/m
return np.ravel(J)
反向传播BP
上面正向传播可以计算得到J(θ),使用梯度下降法还需要求它的梯度
BP反向传播的目的就是求代价函数的梯度
假设4层的神经网络,
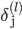
记为-->l层第j个单元的误差
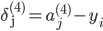
《===》

(向量化)
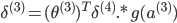
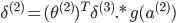
没有
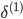
,因为对于输入没有误差
因为S型函数
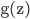
的倒数为:
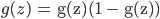
,
所以上面的
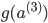
和
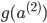
可以在前向传播中计算出来
反向传播计算梯度的过程为:

(
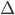
是大写的
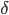
)
for i=1-m:-
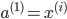
-正向传播计算
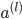
(l=2,3,4...L)
-反向计算
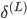
、
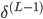
...
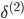
;
-
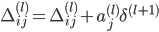
-
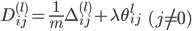
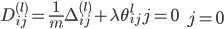
最后
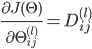
,即得到代价函数的梯度
实现代码:
# 梯度 def nnGradient(nn_params,input_layer_size,hidden_layer_size,num_labels,X,y,Lambda): length = nn_params.shape[0] Theta1 = nn_params[0:hidden_layer_size*(input_layer_size+1)].reshape(hidden_layer_size,input_layer_size+1) Theta2 = nn_params[hidden_layer_size*(input_layer_size+1):length].reshape(num_labels,hidden_layer_size+1) m = X.shape[0] class_y = np.zeros((m,num_labels)) # 数据的y对应0-9,需要映射为0/1的关系 # 映射y for i in range(num_labels): class_y[:,i] = np.int32(y==i).reshape(1,-1) # 注意reshape(1,-1)才可以赋值 '''去掉theta1和theta2的第一列,因为正则化时从1开始''' Theta1_colCount = Theta1.shape[1] Theta1_x = Theta1[:,1:Theta1_colCount] Theta2_colCount = Theta2.shape[1] Theta2_x = Theta2[:,1:Theta2_colCount] Theta1_grad = np.zeros((Theta1.shape)) #第一层到第二层的权重 Theta2_grad = np.zeros((Theta2.shape)) #第二层到第三层的权重 Theta1[:,0] = 0; Theta2[:,0] = 0; '''正向传播,每次需要补上一列1的偏置bias''' a1 = np.hstack((np.ones((m,1)),X)) z2 = np.dot(a1,np.transpose(Theta1)) a2 = sigmoid(z2) a2 = np.hstack((np.ones((m,1)),a2)) z3 = np.dot(a2,np.transpose(Theta2)) h = sigmoid(z3) '''反向传播,delta为误差,''' delta3 = np.zeros((m,num_labels)) delta2 = np.zeros((m,hidden_layer_size)) for i in range(m): delta3[i,:] = h[i,:]-class_y[i,:] Theta2_grad = Theta2_grad+np.dot(np.transpose(delta3[i,:].reshape(1,-1)),a2[i,:].reshape(1,-1)) delta2[i,:] = np.dot(delta3[i,:].reshape(1,-1),Theta2_x)*sigmoidGradient(z2[i,:]) Theta1_grad = Theta1_grad+np.dot(np.transpose(delta2[i,:].reshape(1,-1)),a1[i,:].reshape(1,-1)) '''梯度''' grad = (np.vstack((Theta1_grad.reshape(-1,1),Theta2_grad.reshape(-1,1)))+Lambda*np.vstack((Theta1.reshape(-1,1),Theta2.reshape(-1,1))))/m return np.ravel(grad)
BP可以求梯度的原因
实际是利用了链式求导法则
因为下一层的单元利用上一层的单元作为输入进行计算
大体的推导过程如下,最终我们是想预测函数与已知的y非常接近,求均方差的梯度沿着此梯度方向可使代价函数最小化。可对照上面求梯度的过程。

求误差更详细的推导过程:
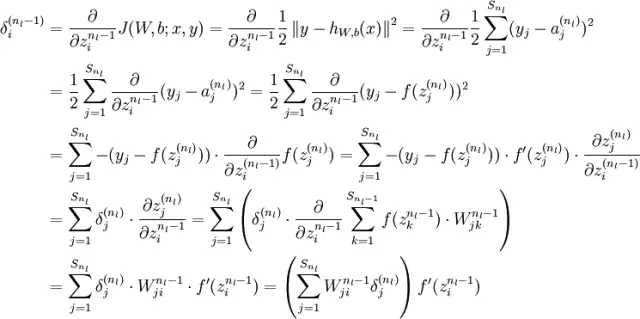
梯度检查
检查利用BP求的梯度是否正确
利用导数的定义验证:
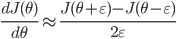
求出来的数值梯度应该与BP求出的梯度非常接近
验证BP正确后就不需要再执行验证梯度的算法了
实现代码:
# 检验梯度是否计算正确 # 检验梯度是否计算正确 def checkGradient(Lambda = 0): '''构造一个小型的神经网络验证,因为数值法计算梯度很浪费时间,而且验证正确后之后就不再需要验证了''' input_layer_size = 3 hidden_layer_size = 5 num_labels = 3 m = 5 initial_Theta1 = debugInitializeWeights(input_layer_size,hidden_layer_size); initial_Theta2 = debugInitializeWeights(hidden_layer_size,num_labels) X = debugInitializeWeights(input_layer_size-1,m) y = 1+np.transpose(np.mod(np.arange(1,m+1), num_labels))# 初始化y y = y.reshape(-1,1) nn_params = np.vstack((initial_Theta1.reshape(-1,1),initial_Theta2.reshape(-1,1))) #展开theta '''BP求出梯度''' grad = nnGradient(nn_params, input_layer_size, hidden_layer_size, num_labels, X, y, Lambda) '''使用数值法计算梯度''' num_grad = np.zeros((nn_params.shape[0])) step = np.zeros((nn_params.shape[0])) e = 1e-4 for i in range(nn_params.shape[0]): step[i] = e loss1 = nnCostFunction(nn_params-step.reshape(-1,1), input_layer_size, hidden_layer_size, num_labels, X, y, Lambda) loss2 = nnCostFunction(nn_params+step.reshape(-1,1), input_layer_size, hidden_layer_size, num_labels, X, y, Lambda) num_grad[i] = (loss2-loss1)/(2*e) step[i]=0 # 显示两列比较 res = np.hstack((num_grad.reshape(-1,1),grad.reshape(-1,1))) print res
权重的随机初始化
神经网络不能像逻辑回归那样初始化theta为0,因为若是每条边的权重都为0,每个神经元都是相同的输出,在反向传播中也会得到同样的梯度,最终只会预测一种结果。
所以应该初始化为接近0的数
实现代码
# 随机初始化权重theta def randInitializeWeights(L_in,L_out): W = np.zeros((L_out,1+L_in)) # 对应theta的权重 epsilon_init = (6.0/(L_out+L_in))**0.5 W = np.random.rand(L_out,1+L_in)*2*epsilon_init-epsilon_init # np.random.rand(L_out,1+L_in)产生L_out*(1+L_in)大小的随机矩阵 return W
预测
正向传播预测结果
实现代码
# 预测
def predict(Theta1,Theta2,X):
m = X.shape[0]
num_labels = Theta2.shape[0]
#p = np.zeros((m,1))
'''正向传播,预测结果'''
X = np.hstack((np.ones((m,1)),X))
h1 = sigmoid(np.dot(X,np.transpose(Theta1)))
h1 = np.hstack((np.ones((m,1)),h1))
h2 = sigmoid(np.dot(h1,np.transpose(Theta2)))
'''
返回h中每一行最大值所在的列号
- np.max(h, axis=1)返回h中每一行的最大值(是某个数字的最大概率)
- 最后where找到的最大概率所在的列号(列号即是对应的数字)
'''
#np.savetxt("h2.csv",h2,delimiter=',')
p = np.array(np.where(h2[0,:] == np.max(h2, axis=1)[0]))
for i in np.arange(1, m):
t = np.array(np.where(h2[i,:] == np.max(h2, axis=1)[i]))
p = np.vstack((p,t))
return p
输出结果
梯度检查:

随机显示100个手写数字

显示theta1权重
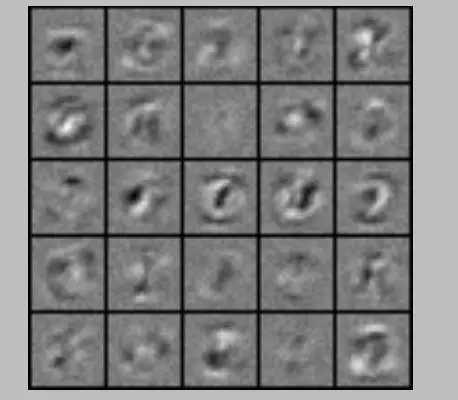
训练集预测准确度
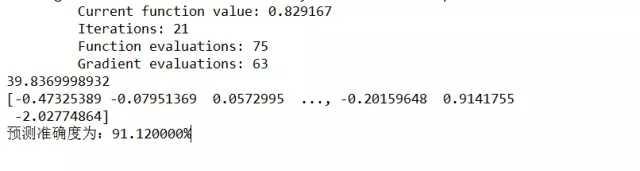
归一化后训练集预测准确度

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python使用numpy实现BP神经网络
本文完全利用numpy实现一个简单的BP神经网络,由于是做regression而不是classification,因此在这里输出层选取的激励函数就是f(x)=x.BP神经网络的具体原理此处不再介绍. import numpy as np class NeuralNetwork(object): def __init__(self, input_nodes, hidden_nodes, output_nodes, learning_rate): # Set number of nodes in i
-
神经网络(BP)算法Python实现及应用
本文实例为大家分享了Python实现神经网络算法及应用的具体代码,供大家参考,具体内容如下 首先用Python实现简单地神经网络算法: import numpy as np # 定义tanh函数 def tanh(x): return np.tanh(x) # tanh函数的导数 def tan_deriv(x): return 1.0 - np.tanh(x) * np.tan(x) # sigmoid函数 def logistic(x): return 1 / (1 + np.exp(-x)
-

Python实现的三层BP神经网络算法示例
本文实例讲述了Python实现的三层BP神经网络算法.分享给大家供大家参考,具体如下: 这是一个非常漂亮的三层反向传播神经网络的python实现,下一步我准备试着将其修改为多层BP神经网络. 下面是运行演示函数的截图,你会发现预测的结果很惊人! 提示:运行演示函数的时候,可以尝试改变隐藏层的节点数,看节点数增加了,预测的精度会否提升 import math import random import string random.seed(0) # 生成区间[a, b)内的随机数 def rand(
-
BP神经网络原理及Python实现代码
本文主要讲如何不依赖TenserFlow等高级API实现一个简单的神经网络来做分类,所有的代码都在下面:在构造的数据(通过程序构造)上做了验证,经过1个小时的训练分类的准确率可以达到97%. 完整的结构化代码见于:链接地址 先来说说原理 网络构造 上面是一个简单的三层网络:输入层包含节点X1 , X2:隐层包含H1,H2:输出层包含O1. 输入节点的数量要等于输入数据的变量数目. 隐层节点的数量通过经验来确定. 如果只是做分类,输出层一般一个节点就够了. 从输入到输出的过程 1.输入节点的输出等
-
用Python实现BP神经网络(附代码)
用Python实现出来的机器学习算法都是什么样子呢? 前两期线性回归及逻辑回归项目已发布(见文末链接),今天来讲讲BP神经网络. BP神经网络 全部代码 https://github.com/lawlite19/MachineLearning_Python/blob/master/NeuralNetwok/NeuralNetwork.py 神经网络model 先介绍个三层的神经网络,如下图所示 输入层(input layer)有三个units( 为补上的bias,通常设为1) 表示第j层的第i个
-
python实现BP神经网络回归预测模型
神经网络模型一般用来做分类,回归预测模型不常见,本文基于一个用来分类的BP神经网络,对它进行修改,实现了一个回归模型,用来做室内定位.模型主要变化是去掉了第三层的非线性转换,或者说把非线性激活函数Sigmoid换成f(x)=x函数.这样做的主要原因是Sigmoid函数的输出范围太小,在0-1之间,而回归模型的输出范围较大.模型修改如下: 代码如下: #coding: utf8 '''' author: Huangyuliang ''' import json import random impo
-
基于python的BP神经网络及异或实现过程解析
BP神经网络是最简单的神经网络模型了,三层能够模拟非线性函数效果. 难点: 如何确定初始化参数? 如何确定隐含层节点数量? 迭代多少次?如何更快收敛? 如何获得全局最优解? ''' neural networks created on 2019.9.24 author: vince ''' import math import logging import numpy import random import matplotlib.pyplot as plt ''' neural network
-
python 使用Tensorflow训练BP神经网络实现鸢尾花分类
Hello,兄弟们,开始搞深度学习了,今天出第一篇博客,小白一枚,如果发现错误请及时指正,万分感谢. 使用软件 Python 3.8,Tensorflow2.0 问题描述 鸢尾花主要分为狗尾草鸢尾(0).杂色鸢尾(1).弗吉尼亚鸢尾(2). 人们发现通过计算鸢尾花的花萼长.花萼宽.花瓣长.花瓣宽可以将鸢尾花分类. 所以只要给出足够多的鸢尾花花萼.花瓣数据,以及对应种类,使用合适的神经网络训练,就可以实现鸢尾花分类. 搭建神经网络 输入数据是花萼长.花萼宽.花瓣长.花瓣宽,是n行四列的矩阵. 而输
-
Python实现疫情通定时自动填写功能(附代码)
自疫情始,学校就要求学生每天在学校内系统填写个人每日疫情相关情况,称为疫情通. 但是,由于个人原因,出现了下图情况. 记性太差,人又懒,于是决定用Python实现自动化定时任务. 1.核心模块 打开IEChrome. 打开网页按下F12拿到请求头和请求体. (假装此处有图片) Pycharm启动! 根据拿到的请求头和请求体,完成核心代码编写. url = "https://xxcapp.xidian.edu.cn/ncov/wap/default/save" headers = {'C
-
Python完美还原超级玛丽游戏附代码与视频
目录 导语
-
五个Python迷你版小程序附代码
一.石头剪刀布游戏 目标:创建一个命令行游戏,游戏者可以在石头.剪刀和布之间进行选择,与计算机PK.如果游戏者赢了,得分就会添加,直到结束游戏时,最终的分数会展示给游戏者. 提示:接收游戏者的选择,并且与计算机的选择进行比较.计算机的选择是从选择列表中随机选取的.如果游戏者获胜,则增加1分. import random choices = ["Rock", "Paper", "Scissors"] computer = random.choice
-
Python实现修改图片分辨率(附代码)
目录 前言 环境依赖 代码 验证一下 前言 本文提供将图片分辨率调整的python代码,一如既往的实用主义. 环境依赖 ffmpeg环境安装,可以参考:windows ffmpeg安装部署 ffmpy安装: pip install ffmpy -i https://pypi.douban.com/simple 代码 不废话,上代码. #!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2021/12/11 21:43 # @Author