Python爬虫实战:分析《战狼2》豆瓣影评
刚接触python不久,做一个小项目来练练手。前几天看了《战狼2》,发现它在最新上映的电影里面是排行第一的,如下图所示。准备把豆瓣上对它的影评做一个分析。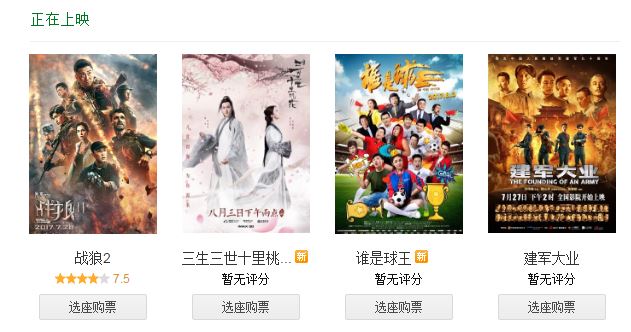
目标总览
主要做了三件事:
- 抓取网页数据
- 清理数据
- 用词云进行展示
使用的python版本是3.5.
一、抓取网页数据
第一步要对网页进行访问,python中使用的是urllib库。代码如下:
from urllib import request
resp = request.urlopen('https://movie.douban.com/nowplaying/hangzhou/')
html_data = resp.read().decode('utf-8')
其中https://movie.douban.com/nowp…是豆瓣最新上映的电影页面,可以在浏览器中输入该网址进行查看。
html_data是字符串类型的变量,里面存放了网页的html代码。输入print(html_data)可以查看,如下图所示:

第二步,需要对得到的html代码进行解析,得到里面提取我们需要的数据。在python中使用BeautifulSoup库进行html代码的解析。(注:如果没有安装此库,则使用pip install BeautifulSoup进行安装即可!)BeautifulSoup使用的格式如下:
BeautifulSoup(html,"html.parser")
第一个参数为需要提取数据的html,第二个参数是指定解析器,然后使用find_all()读取html标签中的内容。
但是html中有这么多的标签,该读取哪些标签呢?其实,最简单的办法是我们可以打开我们爬取网页的html代码,然后查看我们需要的数据在哪个html标签里面,再进行读取就可以了。如下图所示:

从上图中可以看出在div id=”nowplaying“标签开始是我们想要的数据,里面有电影的名称、评分、主演等信息。所以相应的代码编写如下:
from bs4 import BeautifulSoup as bs
soup = bs(html_data, 'html.parser')
nowplaying_movie = soup.find_all('div', id='nowplaying')
nowplaying_movie_list = nowplaying_movie[0].find_all('li', class_='list-item')
其中nowplaying_movie_list 是一个列表,可以用print(nowplaying_movie_list[0])查看里面的内容,如下图所示:

在上图中可以看到data-subject属性里面放了电影的id号码,而在img标签的alt属性里面放了电影的名字,因此我们就通过这两个属性来得到电影的id和名称。(注:打开电影短评的网页时需要用到电影的id,所以需要对它进行解析),编写代码如下:
nowplaying_list = []
for item in nowplaying_movie_list:
nowplaying_dict = {}
nowplaying_dict['id'] = item['data-subject']
for tag_img_item in item.find_all('img'):
nowplaying_dict['name'] = tag_img_item['alt']
nowplaying_list.append(nowplaying_dict)
其中列表nowplaying_list中就存放了最新电影的id和名称,可以使用print(nowplaying_list)进行查看,如下图所示:
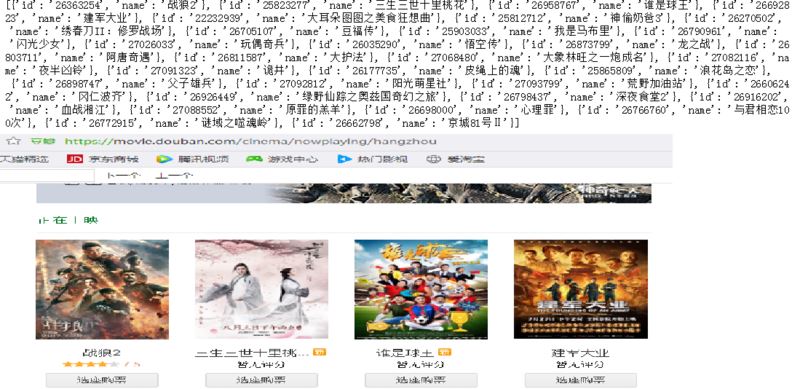
可以看到和豆瓣网址上面是匹配的。这样就得到了最新电影的信息了。接下来就要进行对最新电影短评进行分析了。例如《战狼2》的短评网址为: https://movie.douban.com/subject/26363254/comments?start=0&limit=20
其中26363254就是电影的id,start=0表示评论的第0条评论。
接下来接对该网址进行解析了。打开上图中的短评页面的html代码,我们发现关于评论的数据是在div标签的comment属性下面,如下图所示:
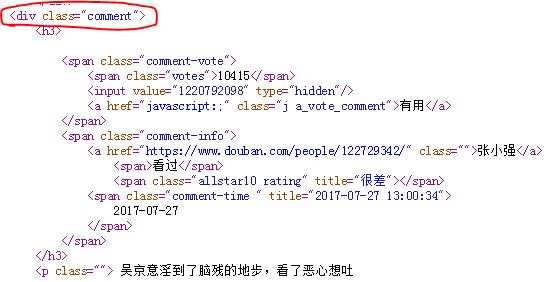
因此对此标签进行解析,代码如下:
requrl = 'https://movie.douban.com/subject/' + nowplaying_list[0]['id'] + '/comments' +'?' +'start=0' + '&limit=20'
resp = request.urlopen(requrl)
html_data = resp.read().decode('utf-8')
soup = bs(html_data, 'html.parser')
comment_div_lits = soup.find_all('div', class_='comment')
此时在comment_div_lits 列表中存放的就是div标签和comment属性下面的html代码了。在上图中还可以发现在p标签下面存放了网友对电影的评论,如下图所示:
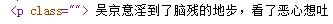
因此对comment_div_lits 代码中的html代码继续进行解析,代码如下:
eachCommentList = [];
for item in comment_div_lits:
if item.find_all('p')[0].string is not None:
eachCommentList.append(item.find_all('p')[0].string)
使用print(eachCommentList)查看eachCommentList列表中的内容,可以看到里面存里我们想要的影评。如下图所示:

好的,至此我们已经爬取了豆瓣最近播放电影的评论数据,接下来就要对数据进行清洗和词云显示了。
二、数据清洗
为了方便进行数据进行清洗,我们将列表中的数据放在一个字符串数组中,代码如下:
comments = '' for k in range(len(eachCommentList)): comments = comments + (str(eachCommentList[k])).strip()
使用print(comments)进行查看,如下图所示:

可以看到所有的评论已经变成一个字符串了,但是我们发现评论中还有不少的标点符号等。这些符号对我们进行词频统计时根本没有用,因此要将它们清除。所用的方法是正则表达式。python中正则表达式是通过re模块来实现的。代码如下:
import re pattern = re.compile(r'[u4e00-u9fa5]+') filterdata = re.findall(pattern, comments) cleaned_comments = ''.join(filterdata)
继续使用print(cleaned_comments)语句进行查看,如下图所示:

我们可以看到此时评论数据中已经没有那些标点符号了,数据变得“干净”了很多。
因此要进行词频统计,所以先要进行中文分词操作。在这里我使用的是结巴分词。如果没有安装结巴分词,可以在控制台使用pip install jieba进行安装。(注:可以使用pip list查看是否安装了这些库)。代码如下所示:
import jieba #分词包
import pandas as pd
segment = jieba.lcut(cleaned_comments)
words_df=pd.DataFrame({'segment':segment})
因为结巴分词要用到pandas,所以我们这里加载了pandas包。可以使用words_df.head()查看分词之后的结果,如下图所示:

从上图可以看到我们的数据中有“看”、“太”、“的”等虚词(停用词),而这些词在任何场景中都是高频时,并且没有实际的含义,所以我们要他们进行清除。
我把停用词放在一个stopwords.txt文件中,将我们的数据与停用词进行比对即可(注:只要在百度中输入stopwords.txt,就可以下载到该文件)。去停用词代码如下代码如下:
stopwords=pd.read_csv("stopwords.txt",index_col=False,quoting=3,sep="t",names=['stopword'], encoding='utf-8')#quoting=3全不引用
words_df=words_df[~words_df.segment.isin(stopwords.stopword)]
继续使用words_df.head()语句来查看结果,如下图所示,停用词已经被出去了。

接下来就要进行词频统计了,代码如下:
import numpy #numpy计算包
words_stat=words_df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size})
words_stat=words_stat.reset_index().sort_values(by=["计数"],ascending=False)
用words_stat.head()进行查看,结果如下:
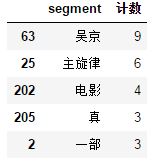
由于我们前面只是爬取了第一页的评论,所以数据有点少,在最后给出的完整代码中,我爬取了10页的评论,所数据还是有参考价值。
三、用词云进行显示
代码如下:
import matplotlib.pyplot as plt
%matplotlib inline
import matplotlib
matplotlib.rcParams['figure.figsize'] = (10.0, 5.0)
from wordcloud import WordCloud#词云包
wordcloud=WordCloud(font_path="simhei.ttf",background_color="white",max_font_size=80) #指定字体类型、字体大小和字体颜色
word_frequence = {x[0]:x[1] for x in words_stat.head(1000).values}
word_frequence_list = []
for key in word_frequence:
temp = (key,word_frequence[key])
word_frequence_list.append(temp)
wordcloud=wordcloud.fit_words(word_frequence_list)
plt.imshow(wordcloud)
其中simhei.ttf使用来指定字体的,可以在百度上输入simhei.ttf进行下载后,放入程序的根目录即可。显示的图像如下:

到此为止,整个项目的介绍就结束了。由于自己也还是个初学者,接触python不久,代码写的并不好。而且第一次写技术博客,表达的有些冗余,请大家多多包涵,有不对的地方,请大家批评指正。以后我也会将自己做的小项目以这种形式写在博客上和大家一起交流!最后贴上完整的代码。
完整代码
#coding:utf-8
__author__ = 'hang'
import warnings
warnings.filterwarnings("ignore")
import jieba #分词包
import numpy #numpy计算包
import codecs #codecs提供的open方法来指定打开的文件的语言编码,它会在读取的时候自动转换为内部unicode
import re
import pandas as pd
import matplotlib.pyplot as plt
from urllib import request
from bs4 import BeautifulSoup as bs
%matplotlib inline
import matplotlib
matplotlib.rcParams['figure.figsize'] = (10.0, 5.0)
from wordcloud import WordCloud#词云包
#分析网页函数
def getNowPlayingMovie_list():
resp = request.urlopen('https://movie.douban.com/nowplaying/hangzhou/')
html_data = resp.read().decode('utf-8')
soup = bs(html_data, 'html.parser')
nowplaying_movie = soup.find_all('div', id='nowplaying')
nowplaying_movie_list = nowplaying_movie[0].find_all('li', class_='list-item')
nowplaying_list = []
for item in nowplaying_movie_list:
nowplaying_dict = {}
nowplaying_dict['id'] = item['data-subject']
for tag_img_item in item.find_all('img'):
nowplaying_dict['name'] = tag_img_item['alt']
nowplaying_list.append(nowplaying_dict)
return nowplaying_list
#爬取评论函数
def getCommentsById(movieId, pageNum):
eachCommentList = [];
if pageNum>0:
start = (pageNum-1) * 20
else:
return False
requrl = 'https://movie.douban.com/subject/' + movieId + '/comments' +'?' +'start=' + str(start) + '&limit=20'
print(requrl)
resp = request.urlopen(requrl)
html_data = resp.read().decode('utf-8')
soup = bs(html_data, 'html.parser')
comment_div_lits = soup.find_all('div', class_='comment')
for item in comment_div_lits:
if item.find_all('p')[0].string is not None:
eachCommentList.append(item.find_all('p')[0].string)
return eachCommentList
def main():
#循环获取第一个电影的前10页评论
commentList = []
NowPlayingMovie_list = getNowPlayingMovie_list()
for i in range(10):
num = i + 1
commentList_temp = getCommentsById(NowPlayingMovie_list[0]['id'], num)
commentList.append(commentList_temp)
#将列表中的数据转换为字符串
comments = ''
for k in range(len(commentList)):
comments = comments + (str(commentList[k])).strip()
#使用正则表达式去除标点符号
pattern = re.compile(r'[u4e00-u9fa5]+')
filterdata = re.findall(pattern, comments)
cleaned_comments = ''.join(filterdata)
#使用结巴分词进行中文分词
segment = jieba.lcut(cleaned_comments)
words_df=pd.DataFrame({'segment':segment})
#去掉停用词
stopwords=pd.read_csv("stopwords.txt",index_col=False,quoting=3,sep="t",names=['stopword'], encoding='utf-8')#quoting=3全不引用
words_df=words_df[~words_df.segment.isin(stopwords.stopword)]
#统计词频
words_stat=words_df.groupby(by=['segment'])['segment'].agg({"计数":numpy.size})
words_stat=words_stat.reset_index().sort_values(by=["计数"],ascending=False)
#用词云进行显示
wordcloud=WordCloud(font_path="simhei.ttf",background_color="white",max_font_size=80)
word_frequence = {x[0]:x[1] for x in words_stat.head(1000).values}
word_frequence_list = []
for key in word_frequence:
temp = (key,word_frequence[key])
word_frequence_list.append(temp)
wordcloud=wordcloud.fit_words(word_frequence_list)
plt.imshow(wordcloud)
#主函数
main()
结果显示如下:

上图基本反映了《战狼2》这部电影的情况。
总结
以上所述是小编给大家介绍的Python爬虫实战:分析《战狼2》豆瓣影评,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
您可能感兴趣的文章:
- Python多线程爬虫实战_爬取糗事百科段子的实例
- Python 3实战爬虫之爬取京东图书的图片详解
- Python3实战之爬虫抓取网易云音乐的热门评论
- python爬虫实战之最简单的网页爬虫教程
- python爬虫框架scrapy实战之爬取京东商城进阶篇
- python爬虫实战之爬取京东商城实例教程
- Python中urllib+urllib2+cookielib模块编写爬虫实战
- Python爬虫框架Scrapy实战之批量抓取招聘信息
相关推荐
-

Python中urllib+urllib2+cookielib模块编写爬虫实战
超文本传输协议http构成了万维网的基础,它利用URI(统一资源标识符)来识别Internet上的数据,而指定文档地址的URI被称为URL(既统一资源定位符),常见的URL指向文件.目录或者执行复杂任务的对象(如数据库查找,internet搜索),而爬虫实质上正是通过对这些url进行访问.操作,从而获取我们想要的内容.对于没有商业需求的我们而言,想要编写爬虫的话,使用urllib,urllib2与cookielib三个模块便可以完成很多需求了. 首先要说明的是,urllib2并非是urllib的
-
Python3实战之爬虫抓取网易云音乐的热门评论
前言 之前刚刚入门python爬虫,有大概半个月时间没有写python了,都快遗忘了.于是准备写个简单的爬虫练练手,我觉得网易云音乐最优特色的就是其精准的歌曲推荐和独具特色的用户评论,于是写了这个抓取网易云音乐热歌榜里的热评的爬虫.我也是刚刚入门爬虫,有什么意见和问题欢迎提出,大家一起共同进步. 废话就不多说了-下面来一起看看详细的介绍吧. 我们的目标是爬取网易云中的热歌排行榜中所有歌曲的热门评论. 这样既可以减少我们需要爬取的工作量,又可以保存到高质量的评论. 实现分析 首先,我们打开网易云网
-
Python爬虫框架Scrapy实战之批量抓取招聘信息
网络爬虫抓取特定网站网页的html数据,但是一个网站有上千上万条数据,我们不可能知道网站网页的url地址,所以,要有个技巧去抓取网站的所有html页面.Scrapy是纯Python实现的爬虫框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便- Scrapy 使用wisted这个异步网络库来处理网络通讯,架构清晰,并且包含了各种中间件接口,可以灵活的完成各种需求.整体架构如下图所示: 绿线是数据流向,首先从初始URL 开始,Scheduler 会将其
-
Python 3实战爬虫之爬取京东图书的图片详解
前言 最近工作中遇到一个需求,需要将京东上图书的图片下载下来,假如我们想把京东商城图书类的图片类商品图片全部下载到本地,通过手工复制粘贴将是一项非常庞大的工程,此时,可以用Python网络爬虫实现,这类爬虫称为图片爬虫,接下来,我们将实现该爬虫. 实现分析 首先,打开要爬取的第一个网页,这个网页将作为要爬取的起始页面.我们打开京东,选择图书分类,由于图书所有种类的图书有很多,我们选择爬取所有编程语言的图书图片吧,网址为:https://list.jd.com/list.html?cat=1713
-
python爬虫实战之最简单的网页爬虫教程
前言 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.最近对python爬虫有了强烈地兴趣,在此分享自己的学习路径,欢迎大家提出建议.我们相互交流,共同进步.话不多说了,来一起看看详细的介绍: 1.开发工具 笔者使用的工具是sublime text3,它的短小精悍(可能男人们都不喜欢这个词)使我十分着迷.推荐大家使用,当然如果你的电脑配置不错,pycharm可能更加适合你. sublime text3
-
python爬虫框架scrapy实战之爬取京东商城进阶篇
前言 之前的一篇文章已经讲过怎样获取链接,怎样获得参数了,详情请看python爬取京东商城普通篇,本文将详细介绍利用python爬虫框架scrapy如何爬取京东商城,下面话不多说了,来看看详细的介绍吧. 代码详解 1.首先应该构造请求,这里使用scrapy.Request,这个方法默认调用的是start_urls构造请求,如果要改变默认的请求,那么必须重载该方法,这个方法的返回值必须是一个可迭代的对象,一般是用yield返回. 代码如下: def start_requests(self): fo
-
Python多线程爬虫实战_爬取糗事百科段子的实例
多线程爬虫:即程序中的某些程序段并行执行, 合理地设置多线程,可以让爬虫效率更高 糗事百科段子普通爬虫和多线程爬虫 分析该网址链接得出: https://www.qiushibaike.com/8hr/page/页码/ 多线程爬虫也就和JAVA的多线程差不多,直接上代码 ''' #此处代码为普通爬虫 import urllib.request import urllib.error import re headers = ("User-Agent","Mozilla/5.0
-
python爬虫实战之爬取京东商城实例教程
前言 本文主要介绍的是利用python爬取京东商城的方法,文中介绍的非常详细,下面话不多说了,来看看详细的介绍吧. 主要工具 scrapy BeautifulSoup requests 分析步骤 1.打开京东首页,输入裤子将会看到页面跳转到了这里,这就是我们要分析的起点 2.我们可以看到这个页面并不是完全的,当我们往下拉的时候将会看到图片在不停的加载,这就是ajax,但是当我们下拉到底的时候就会看到整个页面加载了60条裤子的信息,我们打开chrome的调试工具,查找页面元素时可以看到每条裤子的信
-
Python爬虫实战:分析《战狼2》豆瓣影评
刚接触python不久,做一个小项目来练练手.前几天看了<战狼2>,发现它在最新上映的电影里面是排行第一的,如下图所示.准备把豆瓣上对它的影评做一个分析. 目标总览 主要做了三件事: 抓取网页数据 清理数据 用词云进行展示 使用的python版本是3.5. 一.抓取网页数据 第一步要对网页进行访问,python中使用的是urllib库.代码如下: from urllib import request resp = request.urlopen('https://movie.douban.co
-
Python爬虫实战之使用Scrapy爬取豆瓣图片
使用Scrapy爬取豆瓣某影星的所有个人图片 以莫妮卡·贝鲁奇为例 1.首先我们在命令行进入到我们要创建的目录,输入 scrapy startproject banciyuan 创建scrapy项目 创建的项目结构如下 2.为了方便使用pycharm执行scrapy项目,新建main.py from scrapy import cmdline cmdline.execute("scrapy crawl banciyuan".split()) 再edit configuration 然后
-
Python爬虫实战案例之爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一起期待吧!! 这个案例的视频地址在这里 https://v.douyu.com/show/a2JEMJj3e3mMNxml 项目目标 爬取喜马拉雅音频数据 受害者地址 https://www.ximalaya.com/ 本文知识点: 1.系统分析网页性质 2.多层数据解析 3.海量音频数据保存 环境
-
Python爬虫实战之爬取携程评论
一.分析数据源 这里的数据源是指html网页?还是Aajx异步.对于爬虫初学者来说,可能不知道怎么判断,这里辰哥也手把手过一遍. 提示:以下操作均不需要登录(当然登录也可以) 咱们先在浏览器里面搜索携程,然后在携程里面任意搜索一个景点:长隆野生动物世界,这里就以长隆野生动物世界为例,讲解如何去爬取携程评论数据. 页面下方则是评论数据 从上面两张图可以看出,点击评论下一页,浏览器的链接没有变化,说明数据是Ajax异步请求.因此我们就找到了数据是异步加载过来的,这时候需要去network里面是查
-
python爬虫实战之制作属于自己的一个IP代理模块
一.使用PyChram的正则 首先,小编讲的不是爬取ip,而是讲了解PyCharm的正则,这里讲的正则不是Python的re模块哈! 而是PyCharm的正则功能,我们在PyChram的界面上按上Ctrl+R,可以发现,这里出现两行输入框 现在如果小编想把如下数据转换成一个字典存储 读者也许会一个一去改,但是小编只需在上述的那两个输入框内,输入一串字符串即可. 只需在第一个输入框中,输入(.*) : (.*) 在第二个输入框中,输入"$1":"$2",,看看效果如何
-
Python爬虫实战之用selenium爬取某旅游网站
一.selenium实战 这里我们只会用到很少的selenium语法,我这里就不补充别的用法了,以实战为目的 二.打开艺龙网 可以直接点击这里进入:艺龙网 这里是主页 三.精确目标 我们的目标是,鹤壁市,所以我们应该先点击搜索框,然后把北京删掉,替换成鹤壁市,那么怎么通过selenium实现呢? 打开pycharm,新建一个叫做艺龙网的py文件,先导包: from selenium import webdriver import time # 导包 driver = webdriver.Chro
-
Python爬虫实战之爬取京东商品数据并实实现数据可视化
一.开发工具 Python版本:3.6.4 相关模块: DecryptLogin模块: argparse模块: 以及一些python自带的模块. 二.环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.原理简介 原理其实挺简单的,首先,我们利用之前开源的DecryptLogin库来实现一下微博的模拟登录操作: '''模拟登录京东''' @staticmethod def login(): lg = login.Login() infos_return, session
-
Python爬虫实战项目掌握酷狗音乐的加密过程
1.前言 小编在这里讲一下,下面的内容仅供学习参考,切莫用于商业活动,一经被相关人员发现,本小编概不负责!读者切记切记. 2.获取音乐播放列表 其实,这就是小编要讲的重点,因为就是这部分用到了加密. 我们在搜索栏上输入我们想听的音乐,小编输入:刺客 是不是看到了一系列音乐,怎样得到这些音乐的一些信息呢?(这里指的音乐信息是指音乐的hash值和音乐的album_id值[这两个参数在获取音乐的下载链接那里会用到],当然还包括音乐的名称[不然怎么区别呢?]). 由于这一系列音乐是动态加载出来的,也就是
-
Python爬虫实战之批量下载快手平台视频数据
知识点 requests json re pprint 开发环境: 版 本:anaconda5.2.0(python3.6.5) 编辑器:pycharm 案例实现步骤: 一. 数据来源分析 (只有当你找到数据来源的时候, 才能通过代码实现) 1.确定需求 (要爬取的内容是什么?) 爬取某个关键词对应的视频 保存mp4 2.通过开发者工具进行抓包分析 分析数据从哪里来的(找出真正的数据来源)? 静态加载页面 笔趣阁为例 动态加载页面 开发者工具抓数据包 [付费VIP完整版]只要看了就能学会的教程,
-
Python爬虫实战之虎牙视频爬取附源码
目录 知识点 开发环境 分析目标url 开始代码 最开始还是线导入所需模块 数据请求 获取视频标题以及url地址 获取视频id 保存数据 调用函数 运行代码,得到数据 知识点 爬虫基本流程 re正则表达式简单使用 requests json数据解析方法 视频数据保存 开发环境 Python 3.8 Pycharm 爬虫基本思路流程: (重点) [无论任何网站 任何数据内容 都是按照这个流程去分析] 1.确定需求 (爬取的内容是什么东西?) 都通过开发者工具进行抓包分析 分析视频播放url地址 是