python模拟表单提交登录图书馆
本文实例为大家分享了python模拟登录图书馆的具体代码,供大家参考,具体内容如下
模拟表单提交的原理:
我们都知道Http是无状态的,所以当我们提交的数据和浏览器中正常提交一样,那么服务器就会返回和浏览器中一样的响应。所以我们这里来模拟浏览器表单提交登录广东工业大学的图书馆 http://222.200.122.171:7771/login.aspx,获取cookie,我们接下来访问图书馆网站里的其他页面时就带上这个cookie,服务器会认为我是已经登录的用户,回正常返回数据给我。
首先我们先用浏览器查看页面源代码找到要提交的form表单:
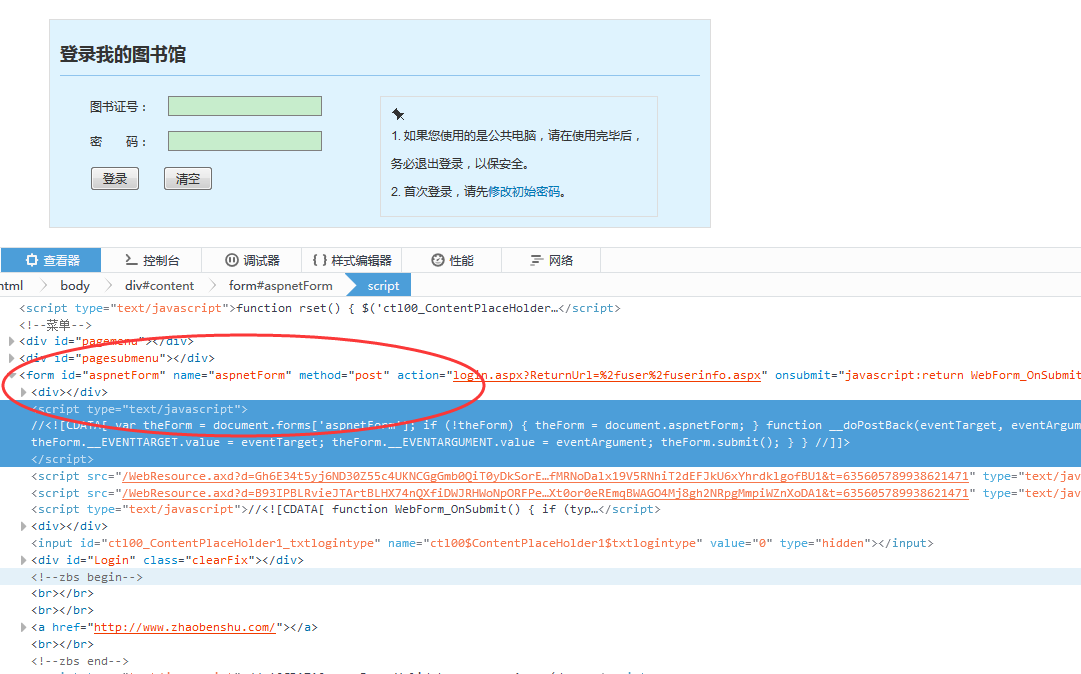
接下来我们要获取表单中的input 包括hidden,因为hidden也会跟着表单一起提交.找到账号和密码对应的name 到时候我们需要用自己的账号填写的.
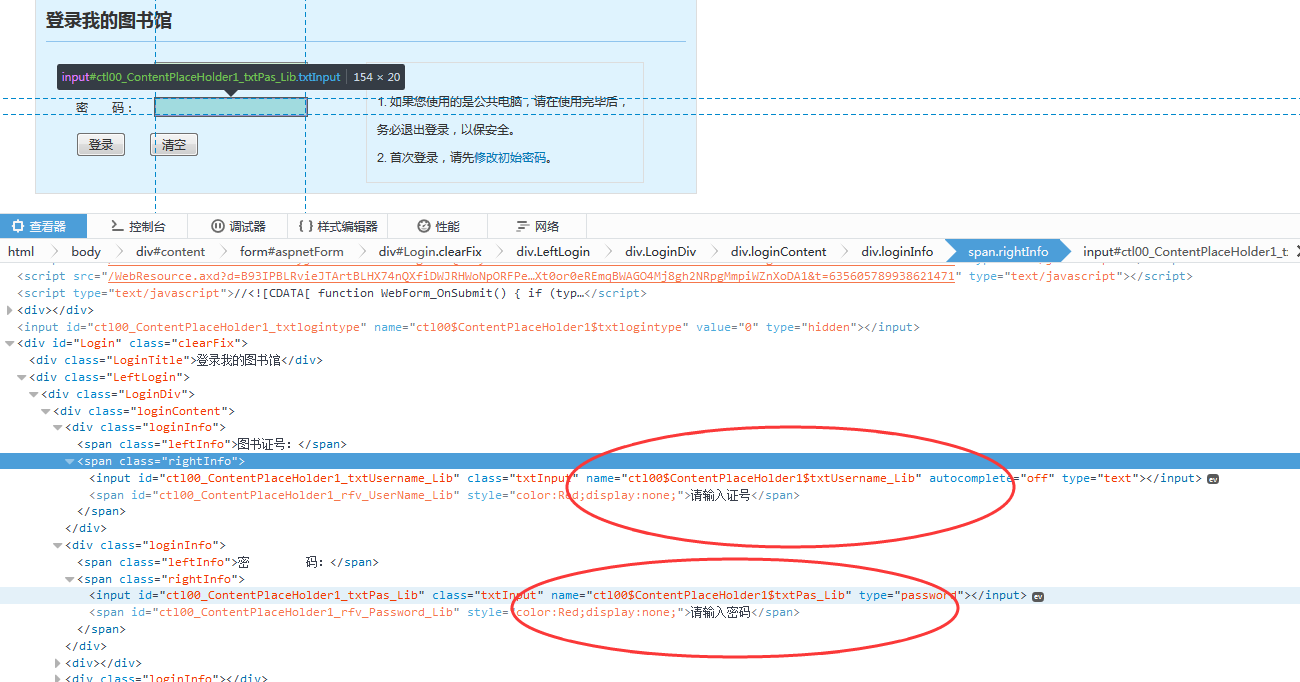
获取到所有的要提交的表单内容后,将账号和密码替换成自己的账号和密码,提交请求.获取cookie并保存在cookie中。
代码如下(Python2.7版本 和Python3都其实都差不多):
# -*- coding:utf-8 -*-
import urllib
import urllib2
import cookielib
import bs4
result = urllib2.urlopen("http://222.200.122.171:7771/login.aspx")
soup = bs4.BeautifulSoup(result, "html.parser")
logindiv = soup.find("form", attrs={"name": "aspnetForm"})
Allinput = logindiv.findAll("input")
inputData = {}
for oneinput in Allinput:
if oneinput.has_attr('name'):
if oneinput.has_attr('value'):
inputData[oneinput['name']] = oneinput['value']
else:
inputData[oneinput['name']] = ""
inputData['ctl00$ContentPlaceHolder1$txtPas_Lib'] = '*****'
inputData['ctl00$ContentPlaceHolder1$txtUsername_Lib'] = '*******'
filename = 'cookie.txt'
# 声明一个MozillaCookieJar对象实例来保存cookie,之后写入文件
cookie = cookielib.MozillaCookieJar(filename)
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie))
postdata = urllib.urlencode(inputData)
result2 = opener.open("http://222.200.122.171:7771/login.aspx", postdata)
cookie.save(ignore_discard=True, ignore_expires=True)
#登录后 要访问的url
bookUrl = "http://222.200.122.171:7771/user/userinfo.aspx"
result=opener.open(bookUrl)
print result.read()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- Python Requests模拟登录实现图书馆座位自动预约
- Python爬虫模拟登录带验证码网站
- python采用requests库模拟登录和抓取数据的简单示例
- Python使用Socket(Https)Post登录百度的实现代码
- python使用rsa加密算法模块模拟新浪微博登录
- 用Python实现web端用户登录和注册功能的教程
- Python实现模拟登录及表单提交的方法
- 使用Python中的cookielib模拟登录网站
- python实现网站的模拟登录
- Python的Flask框架中实现简单的登录功能的教程
相关推荐
-
python实现网站的模拟登录
本文主要用python实现了对网站的模拟登录.通过自己构造post数据来用Python实现登录过程. 当你要模拟登录一个网站时,首先要搞清楚网站的登录处理细节(发了什么样的数据,给谁发等...).我是通过HTTPfox来抓取http数据包来分析该网站的登录流程.同时,我们还要分析抓到的post包的数据结构和header,要根据提交的数据结构和heander来构造自己的post数据和header. 分析结束后,我们要构造自己的HTTP数据包,并发送给指定url.我们通过urllib2等几个模块提供
-
Python Requests模拟登录实现图书馆座位自动预约
本文实例为大家分享了Python实现图书馆座位自动预约的具体代码,供大家参考,具体内容如下 配置 通过公网主机定时运行脚本,并发送邮件到自己的qq邮箱,这样在微信就会有消息提示是否预约成功 vim /etc/crontab 设置每到早上7:01自动运行脚本即可 程序流程 (以yuyue.juneberry.cn网站为例) get访问登录页面,获取cookie和表单里面的隐藏post字段 构造登录post数据,加入从表单里面拿到的隐藏post字段 post构造后的数据,模拟登录,激活cookie(
-
python使用rsa加密算法模块模拟新浪微博登录
PC登录新浪微博时,在客户端用js预先对用户名.密码都进行了加密,而且在POST之前会GET一组参数,这也将作为POST_DATA的一部分.这样,就不能用通常的那种简单方法来模拟POST登录(比如人人网). 通过爬虫获取新浪微博数据,模拟登录是必不可少的. 1.在提交POST请求之前,需要GET获取四个参数(servertime,nonce,pubkey和rsakv),不是之前提到的只是获取简单的servertime,nonce,这里主要是由于js对用户名.密码加密方式改变了. 1.1 由于加密
-
Python使用Socket(Https)Post登录百度的实现代码
登录百度,首先当然是先抓百度的登录包 ,由于是网页登录,最方便的自然是httpwatch了,我使用的测试账号是itiandatest1,密码是itianda,抓包结果: 复制代码 代码如下: POST /?login HTTP/1.1 Accept: image/jpeg, application/x-ms-application, image/gif, application/xaml+xml, image/pjpeg, application/x-ms-xbap, application/v
-
Python实现模拟登录及表单提交的方法
本文实例讲述了Python实现模拟登录及表单提交的方法.分享给大家供大家参考.具体实现方法如下: # -*- coding: utf-8 -*- import re import urllib import urllib2 import cookielib #获取CSDN博客标题和正文 url = "http://blog.csdn.net/[username]/archive/2010/07/05/5712850.aspx" sock = urllib.urlopen(url) ht
-
python采用requests库模拟登录和抓取数据的简单示例
如果你还在为python的各种urllib和urlibs,cookielib 头疼,或者还还在为python模拟登录和抓取数据而抓狂,那么来看看我们推荐的requests,python采集数据模拟登录必备利器! 这也是python推荐的HTTP客户端库: 本文就以一个模拟登录的例子来加以说明,至于采集大家就请自行发挥吧. 代码很简单,主要是展现python的requests库的简单至极,代码如下: s = requests.session() data = {'user':'用户名','pass
-
使用Python中的cookielib模拟登录网站
前面简单提到了 Python 模拟登录的程序,但是没写清楚,这里再补上一个带注释的 Python 模拟登录的示例程序.简单说一下流程:先用cookielib获取cookie,再用获取到的cookie,进入需要登录的网站. # -*- coding: utf-8 -*- # !/usr/bin/python import urllib2 import urllib import cookielib import re auth_url = 'http://www.nowamagic.net/' h
-

用Python实现web端用户登录和注册功能的教程
用户管理是绝大部分Web网站都需要解决的问题.用户管理涉及到用户注册和登录. 用户注册相对简单,我们可以先通过API把用户注册这个功能实现了: _RE_MD5 = re.compile(r'^[0-9a-f]{32}$') @api @post('/api/users') def register_user(): i = ctx.request.input(name='', email='', password='') name = i.name.strip() email = i.email.
-
Python爬虫模拟登录带验证码网站
爬取网站时经常会遇到需要登录的问题,这是就需要用到模拟登录的相关方法.python提供了强大的url库,想做到这个并不难.这里以登录学校教务系统为例,做一个简单的例子. 首先得明白cookie的作用,cookie是某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据.因此我们需要用Cookielib模块来保持网站的cookie. 这个是要登陆的地址 http://202.115.80.153/ 和验证码地址 http://202.115.80.153/CheckCode.
-
Python的Flask框架中实现简单的登录功能的教程
回顾 在前面的系列章节中,我们创建了一个数据库并且学着用用户和邮件来填充,但是到现在我们还没能够植入到我们的程序中. 两章之前,我们已经看到怎么去创建网络表单并且留下了一个实现完全的登陆表单. 在这篇文章中,我们将基于我门所学的网络表单和数据库来构建并实现我们自己的用户登录系统.教程的最后我们小程序会实现新用户注册,登陆和退出的功能. 为了能跟上这章节,你需要前一章节最后部分,我们留下的微博程序.请确保你的程序已经正确安装和运行. 在前面的章节,我们开始配置我们将要用到的Flask扩展.为了登