浅谈Go语言并发机制
Go 语言相比Java等一个很大的优势就是可以方便地编写并发程序。Go 语言内置了 goroutine 机制,使用goroutine可以快速地开发并发程序, 更好的利用多核处理器资源。这篇文章学习goroutine 的应用及其调度实现。
一、Go语言对并发的支持
使用goroutine编程
使用 go 关键字用来创建 goroutine 。将go声明放到一个需调用的函数之前,在相同地址空间调用运行这个函数,这样该函数执行时便会作为一个独立的并发线程。这种线程在Go语言中称作goroutine。
goroutine的用法如下:
//go 关键字放在方法调用前新建一个 goroutine 并执行方法体
go GetThingDone(param1, param2);
//新建一个匿名方法并执行
go func(param1, param2) {
}(val1, val2)
//直接新建一个 goroutine 并在 goroutine 中执行代码块
go {
//do someting...
}
因为 goroutine 在多核 cpu 环境下是并行的。如果代码块在多个 goroutine 中执行,我们就实现了代码并行。
如果需要了解程序的执行情况,怎么拿到并行的结果呢?需要配合使用channel进行。
使用Channel控制并发
Channels用来同步并发执行的函数并提供它们某种传值交流的机制。
通过channel传递的元素类型、容器(或缓冲区)和传递的方向由“<-”操作符指定。
可以使用内置函数 make分配一个channel:
i := make(chan int) // by default the capacity is 0 s := make(chan string, 3) // non-zero capacity r := make(<-chan bool) // can only read from w := make(chan<- []os.FileInfo) // can only write to
配置runtime.GOMAXPROCS
使用下面的代码可以显式的设置是否使用多核来执行并发任务:
runtime.GOMAXPROCS()
GOMAXPROCS的数目根据任务量分配就可以,但是不要大于cpu核数。
配置并行执行比较适合适合于CPU密集型、并行度比较高的情景,如果是IO密集型使用多核的化会增加cpu切换带来的性能损失。
了解了Go语言的并发机制,接下来看一下goroutine 机制的具体实现。
二、区别并行与并发
进程、线程与处理器
在现代操作系统中,线程是处理器调度和分配的基本单位,进程则作为资源拥有的基本单位。每个进程是由私有的虚拟地址空间、代码、数据和其它各种系统资源组成。线程是进程内部的一个执行单元。 每一个进程至少有一个主执行线程,它无需由用户去主动创建,是由系统自动创建的。 用户根据需要在应用程序中创建其它线程,多个线程并发地运行于同一个进程中。
并行与并发
并行与并发(Concurrency and Parallelism)是两个不同的概念,理解它们对于理解多线程模型非常重要。
在描述程序的并发或者并行时,应该说明从进程或者线程的角度出发。
- 并发:一个时间段内有很多的线程或进程在执行,但何时间点上都只有一个在执行,多个线程或进程争抢时间片轮流执行
- 并行:一个时间段和时间点上都有多个线程或进程在执行
非并发的程序只有一个垂直的控制逻辑,在任何时刻,程序只会处在这个控制逻辑的某个位置,也就是顺序执行。如果一个程序在某一时刻被多个CPU流水线同时进行处理,那么我们就说这个程序是以并行的形式在运行。
并行需要硬件支持,单核处理器只能是并发,多核处理器才能做到并行执行。
- 并发是并行的必要条件,如果一个程序本身就不是并发的,也就是只有一个逻辑执行顺序,那么我们不可能让其被并行处理。
- 并发不是并行的充分条件,一个并发的程序,如果只被一个CPU进行处理(通过分时),那么它就不是并行的。
举一个例子,编写一个最简单的顺序结构程序输出"Hello World",它就是非并发的,如果在程序中增加多线程,每个线程打印一个"Hello World",那么这个程序就是并发的。如果运行时只给这个程序分配单个CPU,这个并发程序还不是并行的,需要部署在多核处理器上,才能实现程序的并行。
三、几种不同的多线程模型
用户线程与内核级线程
线程的实现可以分为两类:用户级线程(User-LevelThread, ULT)和内核级线程(Kemel-LevelThread, KLT)。用户线程由用户代码支持,内核线程由操作系统内核支持。
多线程模型
多线程模型即用户级线程和内核级线程的不同连接方式。
(1)多对一模型(M : 1)
将多个用户级线程映射到一个内核级线程,线程管理在用户空间完成。 此模式中,用户级线程对操作系统不可见(即透明)。

优点: 这种模型的好处是线程上下文切换都发生在用户空间,避免的模态切换(mode switch),从而对于性能有积极的影响。
缺点:所有的线程基于一个内核调度实体即内核线程,这意味着只有一个处理器可以被利用,在多处理器环境下这是不能够被接受的,本质上,用户线程只解决了并发问题,但是没有解决并行问题。如果线程因为 I/O 操作陷入了内核态,内核态线程阻塞等待 I/O 数据,则所有的线程都将会被阻塞,用户空间也可以使用非阻塞而 I/O,但是不能避免性能及复杂度问题。
(2) 一对一模型(1:1)
将每个用户级线程映射到一个内核级线程。

每个线程由内核调度器独立的调度,所以如果一个线程阻塞则不影响其他的线程。
优点:在多核处理器的硬件的支持下,内核空间线程模型支持了真正的并行,当一个线程被阻塞后,允许另一个线程继续执行,所以并发能力较强。
缺点:每创建一个用户级线程都需要创建一个内核级线程与其对应,这样创建线程的开销比较大,会影响到应用程序的性能。
(3)多对多模型(M : N)
内核线程和用户线程的数量比为 M : N,内核用户空间综合了前两种的优点。
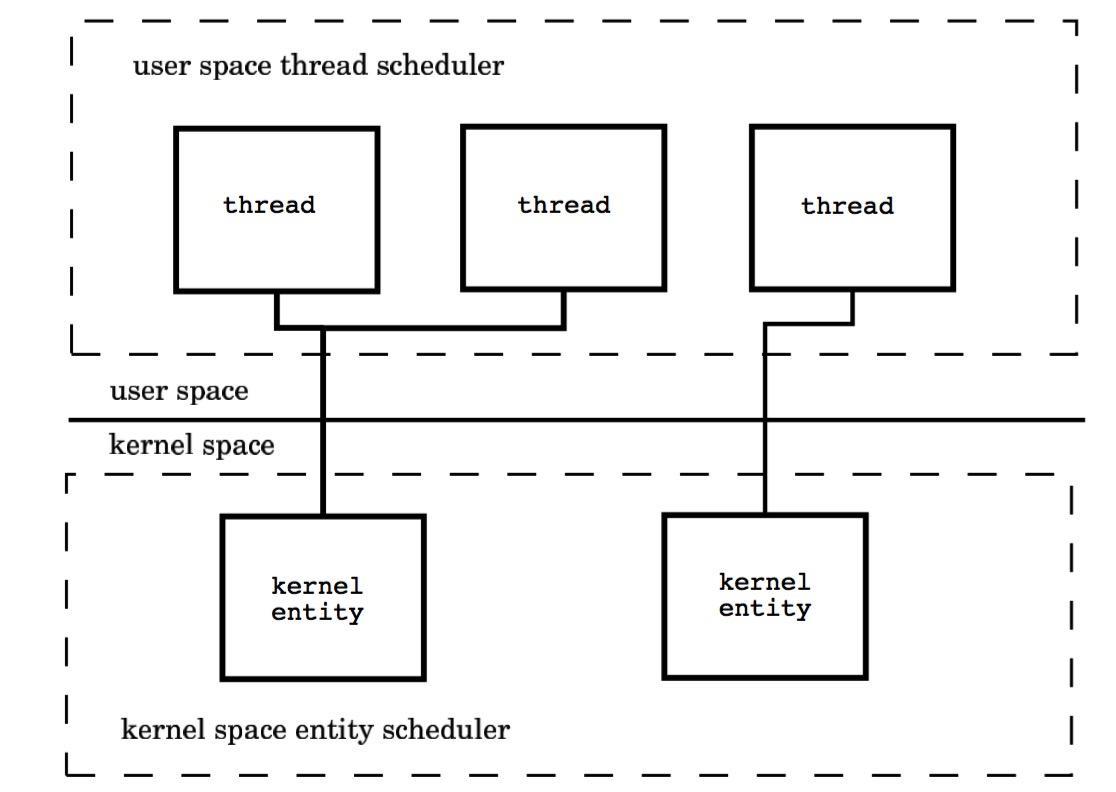
这种模型需要内核线程调度器和用户空间线程调度器相互操作,本质上是多个线程被绑定到了多个内核线程上,这使得大部分的线程上下文切换都发生在用户空间,而多个内核线程又可以充分利用处理器资源。
四、goroutine机制的调度实现
goroutine机制实现了M : N的线程模型,goroutine机制是协程(coroutine)的一种实现,golang内置的调度器,可以让多核CPU中每个CPU执行一个协程。
理解goroutine机制的原理,关键是理解Go语言scheduler的实现。
调度器是如何工作的
Go语言中支撑整个scheduler实现的主要有4个重要结构,分别是M、G、P、Sched, 前三个定义在runtime.h中,Sched定义在proc.c中。
- Sched结构就是调度器,它维护有存储M和G的队列以及调度器的一些状态信息等。
- M结构是Machine,系统线程,它由操作系统管理的,goroutine就是跑在M之上的;M是一个很大的结构,里面维护小对象内存cache(mcache)、当前执行的goroutine、随机数发生器等等非常多的信息。
- P结构是Processor,处理器,它的主要用途就是用来执行goroutine的,它维护了一个goroutine队列,即runqueue。Processor是让我们从N:1调度到M:N调度的重要部分。
- G是goroutine实现的核心结构,它包含了栈,指令指针,以及其他对调度goroutine很重要的信息,例如其阻塞的channel。
Processor的数量是在启动时被设置为环境变量GOMAXPROCS的值,或者通过运行时调用函数GOMAXPROCS()进行设置。Processor数量固定意味着任意时刻只有GOMAXPROCS个线程在运行go代码。
参考这篇传播很广的博客:http://morsmachine.dk/go-scheduler
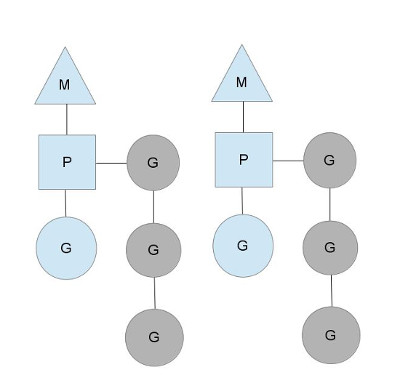
我们分别用三角形,矩形和圆形表示Machine Processor和Goroutine。

在单核处理器的场景下,所有goroutine运行在同一个M系统线程中,每一个M系统线程维护一个Processor,任何时刻,一个Processor中只有一个goroutine,其他goroutine在runqueue中等待。一个goroutine运行完自己的时间片后,让出上下文,回到runqueue中。 多核处理器的场景下,为了运行goroutines,每个M系统线程会持有一个Processor。
在正常情况下,scheduler会按照上面的流程进行调度,但是线程会发生阻塞等情况,看一下goroutine对线程阻塞等的处理。
线程阻塞
当正在运行的goroutine阻塞的时候,例如进行系统调用,会再创建一个系统线程(M1),当前的M线程放弃了它的Processor,P转到新的线程中去运行。

runqueue执行完成
当其中一个Processor的runqueue为空,没有goroutine可以调度。它会从另外一个上下文偷取一半的goroutine。

五、对并发实现的进一步思考
Go语言的并发机制还有很多值得探讨的,比如Go语言和Scala并发实现的不同,Golang CSP 和Actor模型的对比等。
了解并发机制的这些实现,可以帮助我们更好的进行并发程序的开发,实现性能的最优化。
关于三种多线程模型,可以关注一下Java语言的实现。
我们知道Java通过JVM封装了底层操作系统的差异,而不同的操作系统可能使用不同的线程模型,例如Linux和windows可能使用了一对一模型,solaris和unix某些版本可能使用多对多模型。JVM规范里没有规定多线程模型的具体实现,1:1(内核线程)、N:1(用户态线程)、M:N(混合)模型的任何一种都可以。谈到Java语言的多线程模型,需要针对具体JVM实现,比如Oracle/Sun的HotSpot VM,默认使用1:1线程模型。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
GO语言并发编程之互斥锁、读写锁详解
在本节,我们对Go语言所提供的与锁有关的API进行说明.这包括了互斥锁和读写锁.我们在第6章描述过互斥锁,但却没有提到过读写锁.这两种锁对于传统的并发程序来说都是非常常用和重要的. 一.互斥锁 互斥锁是传统的并发程序对共享资源进行访问控制的主要手段.它由标准库代码包sync中的Mutex结构体类型代表.sync.Mutex类型(确切地说,是*sync.Mutex类型)只有两个公开方法--Lock和Unlock.顾名思义,前者被用于锁定当前的互斥量,而后者则被用来对当前的互斥量进行解锁. 类型sy
-
Go语言如何并发超时处理详解
实现原理: 并发一个函数,等待1s后向timeout写入数据,在select中如果1s之内有数据向其他channel写入则会顺利执行,如果没有,这是timeout写入了数据,则我们知道超时了. 实现代码: package main import "fmt" import "time" func main() { ch := make(chan int, 1) timeout := make(chan bool, 1) // 并发执行一个函数,等待1s后向timeou
-
如何利用Golang写出高并发代码详解
前言 之前一直对Golang如何处理高并发http请求的一头雾水,这几天也查了很多相关博客,似懂非懂,不知道具体代码怎么写 下午偶然在开发者头条APP上看到一篇国外技术人员的一篇文章用Golang处理每分钟百万级请求,看完文章中的代码,自己写了一遍代码,下面自己写下自己的体会 核心要点 将请求放入队列,通过一定数量(例如CPU核心数)goroutine组成一个worker池(pool),workder池中的worker读取队列执行任务 实例代码 以下代码笔者根据自己的理解进行了简化,主要是表达出
-
Golang极简入门教程(三):并发支持
Golang 运行时(runtime)管理了一种轻量级线程,被叫做 goroutine.创建数十万级的 goroutine 是没有问题的.范例: 复制代码 代码如下: package main import ( "fmt" "time" ) func say(s string) { for i := 0; i < 5; i++ { time.Sleep(100 * time.Millisecond)
-
使用google-perftools优化nginx在高并发时的性能的教程(完整版)
注意:本教程仅适用于Linux. 下面为大家介绍google-perftools的安装,并配置Nginx和MySQL支持google-perftools. 首先,介绍如何优化Nginx: 1,首先下载并安装google-perftools: 注意,如果是64位系统: 那么你需要做:1)先安装libunwind或者2)在configure时添加--enable-frame-pointers. 那么首先说说如何安装libunwind: 复制代码 代码如下: wget http://download.
-

Go并发编程实践
前言 并发编程一直是Golang区别与其他语言的很大优势,也是实际工作场景中经常遇到的.近日笔者在组内分享了我们常见的并发场景,及代码示例,以期望大家能在遇到相同场景下,能快速的想到解决方案,或者是拿这些方案与自己实现的比较,取长补短.现整理出来与大家共享. 简单并发场景 很多时候,我们只想并发的做一件事情,比如测试某个接口的是否支持并发.那么我们就可以这么做: func RunScenario1() { count := 10 var wg sync.WaitGroup for i := 0;
-
Go语言并发技术详解
有人把Go比作21世纪的C语言,第一是因为Go语言设计简单,第二,21世纪最重要的就是并行程序设计,而Go从语言层面就支持了并行. goroutine goroutine是Go并行设计的核心.goroutine说到底其实就是线程,但是它比线程更小,十几个goroutine可能体现在底层就是五六个线程,Go语言内部帮你实现了这些goroutine之间的内存共享.执行goroutine只需极少的栈内存(大概是4~5KB),当然会根据相应的数据伸缩.也正因为如此,可同时运行成千上万个并发任务.goro
-
Go语言并发模型的2种编程方案
概述 我一直在找一种好的方法来解释 go 语言的并发模型: 不要通过共享内存来通信,相反,应该通过通信来共享内存 但是没有发现一个好的解释来满足我下面的需求: 1.通过一个例子来说明最初的问题 2.提供一个共享内存的解决方案 3.提供一个通过通信的解决方案 这篇文章我就从这三个方面来做出解释. 读过这篇文章后你应该会了解通过通信来共享内存的模型,以及它和通过共享内存来通信的区别,你还将看到如何分别通过这两种模型来解决访问和修改共享资源的问题. 前提 设想一下我们要访问一个银行账号: 复制代码 代
-
浅谈Go语言并发机制
Go 语言相比Java等一个很大的优势就是可以方便地编写并发程序.Go 语言内置了 goroutine 机制,使用goroutine可以快速地开发并发程序, 更好的利用多核处理器资源.这篇文章学习goroutine 的应用及其调度实现. 一.Go语言对并发的支持 使用goroutine编程 使用 go 关键字用来创建 goroutine .将go声明放到一个需调用的函数之前,在相同地址空间调用运行这个函数,这样该函数执行时便会作为一个独立的并发线程.这种线程在Go语言中称作goroutine.
-
浅谈C语言的字节对齐 #pragma pack(n)2
#pragma pack(n) 这是给编译器用的参数设置,有关结构体字节对齐方式设置, #pragma pack是指定数据在内存中的对齐方式. #pragma pack (n) 作用:C编译器将按照n个字节对齐. #pragma pack () 作用:取消自定义字节对齐方式. #pragma pack (push,1) 作用:是指把原来对齐方式设置压栈,并设新的对齐方式设置为一个字节对齐 #pragma pack(pop)
-
浅谈C++高并发场景下读多写少的优化方案
目录 概述 分析 双缓冲 工程实现上需要攻克的难点 核心代码实现 简单说说golang中双缓冲的实现 相关文献 概述 一谈到高并发的优化方案,往往能想到模块水平拆分.数据库读写分离.分库分表,加缓存.加mq等,这些都是从系统架构上解决.单模块作为系统的组成单元,其性能好坏也能很大的影响整体性能,本文从单模块下读多写少的场景出发,探讨其解决方案,以其更好的实现高并发.不同的业务场景,读和写的频率各有侧重,有两种常见的业务场景: 读多写少:典型场景如广告检索端.白名单更新维护.loadbalance
-
浅谈Redis高并发缓存架构性能优化实战
目录 场景1: 中小型公司Redis缓存架构以及线上问题实战 场景2: 大厂线上大规模商品缓存数据冷热分离实战 场景3: 基于DCL机制解决热点缓存并发重建问题实战 场景4: 突发性热点缓存重建导致系统压力暴增 场景5: 解决大规模缓存击穿导致线上数据库压力暴增 场景6: 黑客工资导致缓存穿透线上数据库宕机 场景7: 大V直播带货导致线上商品系统崩溃原因分析 场景8: Redis分布式锁解决缓存与数据库双写不一致问题实战 场景9: 大促压力暴增导致分布式锁串行争用问题优化 场景10: 利用多级缓
-
浅谈Go语言中的结构体struct & 接口Interface & 反射
结构体struct struct 用来自定义复杂数据结构,可以包含多个字段(属性),可以嵌套: go中的struct类型理解为类,可以定义方法,和函数定义有些许区别: struct类型是值类型. struct定义 type User struct { Name string Age int32 mess string } var user User var user1 *User = &User{} var user2 *User = new(User) struct使用 下面示例中user1和
-
浅谈c语言中一种典型的排列组合算法
c语言中的全排列算法和组合数算法在实际问题中应用非常之广,但算法有许许多多,而我个人认为方法不必记太多,最好只记熟一种即可,一招鲜亦可吃遍天 全排列: #include<stdio.h> void swap(int *p1,int *p2) { int t=*p1; *p1=*p2; *p2=t; } void permutation(int a[],int index,int size) { if(index==size) { for(int i=0;i<size;i++) print
-
浅谈C语言共用体和与结构体的区别
共用体与结构体的区别 共用体: 使用union 关键字 共用体内存长度是内部最长的数据类型的长度. 共用体的地址和内部各成员变量的地址都是同一个地址 结构体大小: 结构体内部的成员,大小等于最后一个成员的偏移量+最后一个成员大小+末尾的填充字节数. 结构体的偏移量:某一个成员的实际地址和结构体首地址之间的距离. 结构体字节对齐:每个成员相对于结构体首地址的偏移量都得是当前成员所占内存大小的整数倍,如果不是会在成员前面加填充字节.结构体的大小是内部最宽的成员的整数倍. 共用体 #include <
-
浅谈C语言的字符串分割
说起来很有意思,自认为对C语言理解得还是比较深刻的.但居然到今天才知道有个strtok函数,试用了一下突然感慨以前做了多少重复劳动.每次需要解析配置文件,每次需要分割字符串,居然都是自己去分割字符串,既累人又容易出错.感概技术学得不够全面啊!这里引用一段strtok用法: The strtok() function returns a pointer to the next "token" in str1, where str2 contains the delimiters that
-
浅谈C语言之字符串处理函数
下面介绍8种基本的常用的字符串处理函数,在数值数组中也常常用到(部分函数).所有的C语言编译系统中一般都提供这些函数. 1.puts函数--输出字符串的函数 一般的形式为puts(字符串组) 作用:将一个字符串输出到终端.如,char一个string,并赋予初值.调用puts(string);进行字符串的输出. 2.gets函数--输入字符串的函数 一般的形式:gets(字符数组) 作用:从终端输入一个字符串到字符数组,并且得到一个函数值成为字符数组的起始地址. gets(str); 键盘输入,
-
浅谈C语言转义字符和格式控制符
转义字符参考: \a:蜂鸣,响铃 \b:回退:向后退一格 \f:换页 \n:换行,光标到下行行首 \r:回车,光标到本行行首 \t:水平制表 \v:垂直制表 \\:反斜杠 \':单引号 \":双引号 \?:问号 \ddd:三位八进制 \xhh:二位十六进制 \0:空字符(NULL),什么都不做 注: 1,\v垂直制表和\f换页符对屏幕没有任何影响,但会影响打印机执行响应操作. 2,\n其实应该叫回车换行.换行只是换一行,不改变光标的横坐标:回车只是回到行首,不改变光标的纵坐标. 3,\t 光标向