PyCharm+PySpark远程调试的环境配置的方法
前言:前两天准备用 Python 在 Spark 上处理量几十G的数据,熟料在利用PyCharm进行PySpark远程调试时掉入深坑,特写此博文以帮助同样深处坑中的bigdata&machine learning fans早日出坑。
Version :Spark 1.5.0、Python 2.7.14
1. 远程Spark集群环境
首先Spark集群要配置好且能正常启动,版本号可以在Spark对应版本的官方网站查到,注意:Spark 1.5.0作为一个比较古老的版本,不支持Python 3.6+;另外Spark集群的每个节点的Python版本必须保持一致。这里只讲如何加入pyspark远程调试所需要修改的部分。在$SPARK_HOME/conf/spark-env.sh中添加一行:
export PYSPARK_PYTHON=/home/hadoop/anaconda2/bin/python2
这里的Python路径是集群上Python版本的路径,我这里是用的anaconda安装的Python2,所以路路径如上。正常启动Spark集群后,在命令行输入pyspark后回车,能正确进入到pyspark shell。
2. 本地PyCharm配置
首先将Spark集群的spark-1.5.0部署包拷贝到本地机器,并在/etc/hosts(Linux类机器)或C:\Windows\System32….\hosts(Windows机器)中加入Spark集群Master节点的IP与主机名的映射;本地正确安装Spark集群同版本Python;
安装py4j
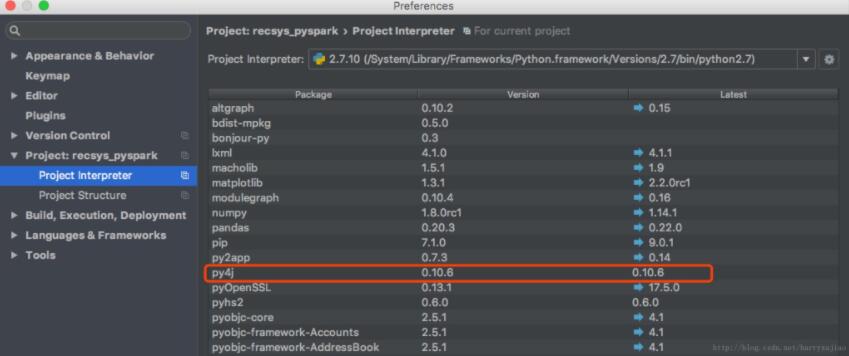
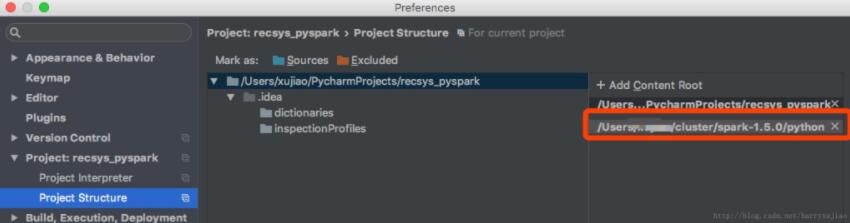
添加spark-1.5.0/python目录
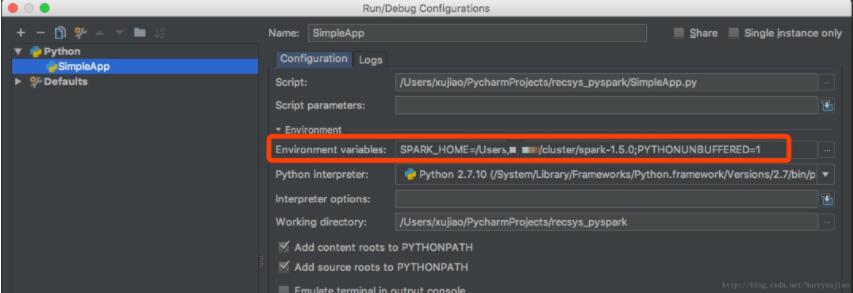
新建一个Python文件Simple,编辑Edit Configurations添加SPARK_HOME变量
写一个类似下面的简单测试程序
# -*- encoding: UTF-8 -*-
# @auther:Mars
# @datetime:2018-03-01
from pyspark import SparkContext
sc = SparkContext("spark://master:7077","Simple APP")
logData = sc.textFile("hdfs://master:9000/README.md").cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print("Lines with a: %i, lines with b: %i"%(numAs, numBs))
sc.stop()
运行可以得到看到下图,就OK了~
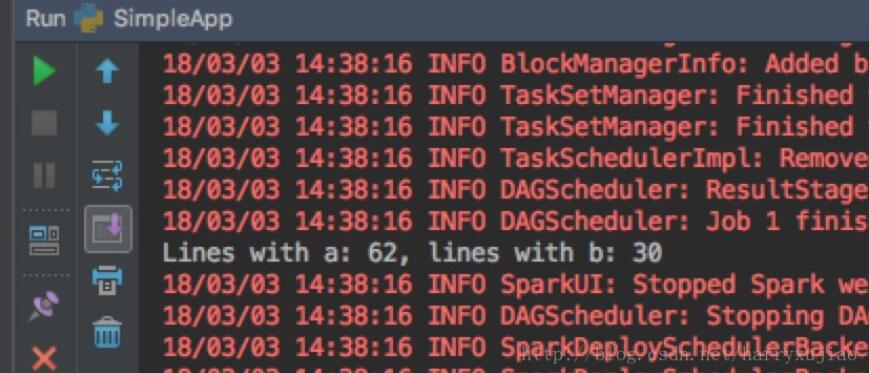
切记,1)本地与Spark集群的版本要一致;2)程序中不要用IP地址(不信可以试试,如果你用IP地址不报错,请告知我~谢谢)
以上这篇PyCharm+PySpark远程调试的环境配置的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

pycharm远程调试openstack代码
本文实例为大家分享了pycharm远程调试openstack的具体代码,供大家参考,具体内容如下 1.安装pycharm专业版 本文安装pycharm 2016.2.3专业版.网上教程较多,这里不做详细介绍,只要到pycharm官网上下载应用程序进行安装即可. 2.pycharm配置 (1)首先按下图1打开tools->deployment->configuration: 图 (2)接下来add server,补充server name以及传输方式SFTP,点击ok,如下图2所示: (3)填
-
pycharm远程调试openstack的图文教程
今天我要讲如何远程调试openstack.首先我们使用的工具是Pycharm. 1.首先介绍一下环境 我的openstack是使用rdo一键安装的,安装在一台centos的虚拟机上,虚拟机的IP地址是192.168.102.129 2.创建流程 首先加载远程python解释器,比如你的openstack安装在虚拟机上,则就是你虚拟机上的python,这里我们以远程调试nova为例. 2.1 首先创建项目路径 2.2 加载远程解释器 设置远程 2.3设置路劲映射 2.4 下载源码到本地 点击红色所
-
Pycharm远程调试openstack的方法
Pycharm对openstack进行远程调试,供大家参考,具体内容如下 总共分三步: 一. 安装samba(非必须的) 二. 安装并配置pycharm 三. 修改openstack的代码(以nova为例) 一.为了实现远程代码的map要首先进行如下设置 1.安装samba(针对Unbuntu14.04,其它版本的安装方式可能略有差别) sudo apt-get install samba sudo apt-get install smbfs sudo apt-get install cifs-
-
PyCharm设置SSH远程调试的方法
一.环境 系统环境:windows10 64位 软件:PyCharm2017.3 本地Python环境:Python2.7 二.配置 2.1配置远程调试 第一步:运行PyCharm,然后点击设置如下图 第二步:添加远程的调试环境(选择SSH远程) 然后进入下面界面添加: 第三步:配置本地到远程主机的同步 然后进入下面页面具体配置同步信息,配置完成以后点击OK即可: 2.2配置编码(解决远程start ssh session乱码问题) 第一步: ----> File --> settings -
-
Pycharm配置远程调试的方法步骤
动机 一些bug由于本地环境和线上环境的不一致可能导致本地无法复现 本地依赖和线上依赖版本不一致也可以导致一些问题 有时一些bug跟数据相关,本地数据无法和线上数据一致 有些三方平台会验证服务器的合法性或者异步回调结果,如微信支付,这时候本地无法测试 如上所诉,要是有一个很方便调试远程服务器的方法,岂不美哉.通过PyCharm我们可以很方便地实现远程调试,下面详细介绍下PyCharm这个牛叉的功能. 使用远程解释器 默认情况下我们在本地开发Python程序时,使用的是本地的Python解释器,如
-
PyCharm+PySpark远程调试的环境配置的方法
前言:前两天准备用 Python 在 Spark 上处理量几十G的数据,熟料在利用PyCharm进行PySpark远程调试时掉入深坑,特写此博文以帮助同样深处坑中的bigdata&machine learning fans早日出坑. Version :Spark 1.5.0.Python 2.7.14 1. 远程Spark集群环境 首先Spark集群要配置好且能正常启动,版本号可以在Spark对应版本的官方网站查到,注意:Spark 1.5.0作为一个比较古老的版本,不支持Python 3.6+
-
Hadoop 使用IntelliJ IDEA 进行远程调试代码的配置方法
一 .前言 昨天晚上遇到一个奇葩的问题, 搞好的环境DataNode启动报错. 报错信息提示的模棱两可,没办法定位原因. 办法,开启远程调试- 注意 : 开启远程调试的代码,必须与本地idea的代码必须保持一致. 二 .服务器端配置 2.1. 设置启动远程debug端口 修改 服务器上的配置文件 ${HADOOP_HOME}/etc/hadoop/hadoop-env.sh 增加 环境变量即可. 组件 环境变量设置 NameNode export HADOOP_NAMENODE_OPTS="-a
-
pycharm下pyqt4安装及环境配置的教程
一.安装 首先根据自己的python版本下载pyqt4离线包,现在连接:https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyqt4 比如我地python版本是python3.5.2,我选择PyQt4‑4.11.4‑cp35‑cp35m‑win_amd64.whl 在whl文件路径下,使用pip指令安装 pip install PyQt4‑4.11.4‑cp35‑cp35m‑win_amd64.whl 静待安装完成即可 二.pycharm下环境配置 找到:F
-
使用virtualenv创建Python环境及PyQT5环境配置的方法
一.写在前面 从学 Python 的第一天起,我就知道了使用 pip 命令来安装包,从学习爬虫到学习 Web 开发,安装的库越来越多,从 requests 到 lxml,从 Django 到 Flask,各种各样的库都处在一个 Python 环境之中. 这种做法对于我这种懒人来说是再适合不过的了,但是这样也是会有问题的.第一个问题在于 Pycharm 的加载速度变得慢了,因为要导入太多包了,而其中很多包对于很多程序来说根本用不上.第二个问题在于很多模块之间是有版本要求的,都需要特定的版本才能执行
-
vscode通过Remote SSH远程连接及离线配置的方法
安装 1.先安装vscode,然后在扩展中搜索Remote SSH插件并安装. 2.我要连接远程Ubuntu系统的服务器,所以需要在服务器上安装ssh并配置: 1)安装ssh服务端:apt-get install openssh-server 2) 确认ssh-server是否启动:ps -e | grep ssh 3) 如果ssh没有启动,则需要启动ssh-server:/etc/init.d/ssh start 4) 如果ssh启动了,重启一下:/etc/in
-
React + webpack 环境配置的方法步骤
本文介绍了React + webpack 环境配置的方法步骤,分享给大家,具体如下: 安装配置Babel babel-preset-es2015 ES6语法包,使代码可以随意地使用ES6的新特性. babel-preset-react React语法包,专门用于React的优化,在代码中可以使用React ES6 classes的写法,同时直接支持JSX语法格式 安装Babel loader // 安装babel-core核心模块和babel-loader npm install babel-c
-
OpenCV4.1.0+VS2017环境配置的方法步骤
将VS2017上配置OpenCV4.1.0的过程记录于此. 准备工具: OpenCV:4.1.0 IDE:VS2017 安装环境:Win10 64位操作系统 主要步骤: 下载OpenCV自解压程序 安装VS2017 新建项目 配置包含路径 配置库目录 配置链接器 配置环境变量 重启VS2017 测试配置是否成功 详细过程: 1. 下载OpenCV自解压程序 打开https://opencv.org/releases.html,可以看到如图1的界面. 图1 OpenCV4.1.0下载界面 点
-
使用maven的profile构建不同环境配置的方法
最近使用到了maven的profile功能,发现这个功能的确很好用也很实用,这块的知识比较多也比较乱,其实真正理解了之后非常简单,为了巩固总结知识,有个更清晰的知识体系,本文诞生了,希望能让像我一样零基础的小白一看就懂,有请戏精,闪亮登场~~ 1.背景 作为一名猿,在实际的项目开发中,通常会有很多配置环境,比如最基本的:开发.测试.生产:不同的环境,某些文件的配置是不一样的(如:数据库连接信息.properties文件的配置等),如果我们进行开发or测试时每次都得手动去修改配置文件,难免有些麻烦
-
docker的pdflatex环境配置的方法步骤
技术背景 Latex在文档撰写方面是不可或缺的工具,尤其是在写文章方面,是必须要用到的文字排版工具.但是latex的环境部署并不是一个特别人性化的操作,尤其是在各种不同的平台上操作是完全不一样的,还经常容易报错.我们可以一个一个的去解决报错问题,但是这需要耗费极大的精力和时间,所以很多人选择了直接在overleaf进行latex的创作.但其实overleaf也有它的缺点,比如免费版本的带宽和速度都比较受限,尤其是在国内的网络,访问速度可谓是"一绝".因此这里我们介绍一个更加人性化的方案
-
详解pycharm连接远程linux服务器的虚拟环境的方法
一.前提条件 1.确保linux服务器已经安装好虚拟环境,并且虚拟环境已经python的相关环境(连接服务器也可以进行环境配置). 2.通过Xsheel激活虚拟环境然后通过pip安装相关的包,当然也可以通过pycharm的terminal进行相关库 安装. 二.连接服务器 1.进入pycharm的Tools栏 2.选择文件传输协议为SFTP,输入服务器的IP.端口.密码进行连接,不出意外的情况下应该是能够连接成功的. 3.选择本地和服务器的文件路径 三.采用服务器的解释器 1.file-seti