将Python字符串生成PDF的实例代码详解
笔者在今天的工作中,遇到了一个需求,那就是如何将Python字符串生成PDF。比如,需要把Python字符串‘这是测试文件'生成为PDF, 该PDF中含有文字‘这是测试文件'。
经过一番检索,笔者决定采用wkhtmltopdf这个软件,它可以将HTML转化为PDF。wkhtmltopdf的访问网址为:https://wkhtmltopdf.org/downloads.html ,读者可根据自己的系统下载对应的文件并安装。安装好wkhtmltopdf,我们再安装这个软件的Python第三方模块——pdfkit,安装方式如下:
pip install pdfkit
我们再讨论如下问题:
•如何将Python字符串生成PDF;
•如何生成PDF中的表格;
•解决PDF生成速度慢的问题。
如何将Python字符串生成PDF
该问题的解决思路还是利用将Python字符串嵌入到HTML代码中解决,注意换行需要用<br>标签,示例代码如下:
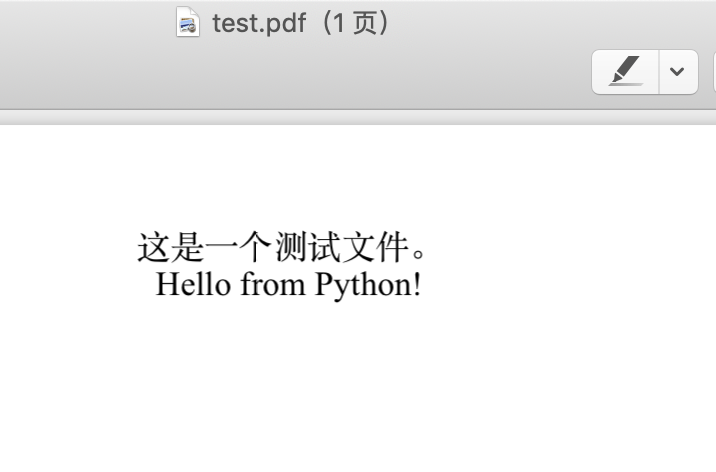
import pdfkit # PDF中包含的文字 content = '这是一个测试文件。' + '<br>' + 'Hello from Python!' html = '<html><head><meta charset="UTF-8"></head>' \ '<body><div align="center"><p>%s</p></div></body></html>'%content # 转换为PDF pdfkit.from_string(html, './test.pdf')
输出的结果如下:
Loading pages (1/6)
Counting pages (2/6)
Resolving links (4/6)
Loading headers and footers (5/6)
Printing pages (6/6)
Done
生成的test.pdf如下:
如何生成PDF中的表格
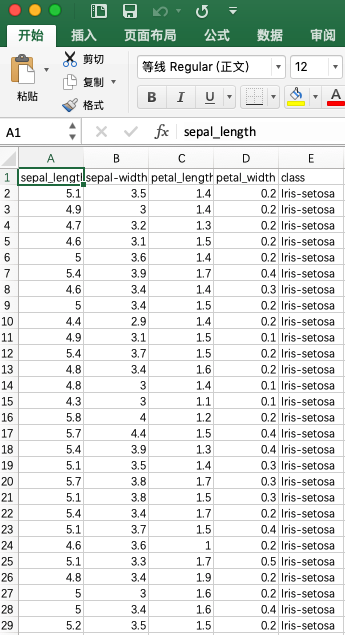
接下来我们考虑如何将csv文件转换为PDF中的表格,思路还是利用HTML代码。示例的iris.csv文件(部分)如下:
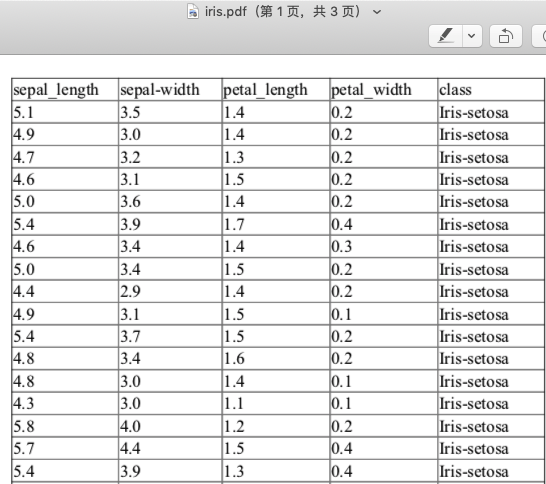
将csv文件转换为PDF中的表格的Python代码如下:
import pdfkit
# 读取csv文件
with open('iris.csv', 'r') as f:
lines = [_.strip() for _ in f.readlines()]
# 转化为html中的表格样式
td_width = 100
content = '<table width="%s" border="1" cellspacing="0px" style="border-collapse:collapse">' % (td_width*len(lines[0].split(',')))
for i in range(len(lines)):
tr = '<tr>'+''.join(['<td width="%d">%s</td>'%(td_width, _) for _ in lines[i].split(',')])+'</tr>'
content += tr
content += '</table>'
html = '<html><head><meta charset="UTF-8"></head>' \
'<body><div align="center">%s</div></body></html>' % content
# 转换为PDF
pdfkit.from_string(html, './iris.pdf')
生成的PDF文件为iris.pdf,部分内容如下:
解决PDF生成速度慢的问题
用pdfkit生成PDF文件虽然方便,但有一个比较大的缺点,那就是生成PDF的速度比较慢,这里我们可以做个简单的测试,比如生成100份PDF文件,里面的文字为“这是第*份测试文件!”。Python代码如下:
import pdfkit
import time
start_time = time.time()
for i in range(100):
content = '这是第%d份测试文件!'%(i+1)
html = '<html><head><meta charset="UTF-8"></head>' \
'<body><div align="center">%s</div></body></html>' % content
# 转换为PDF
pdfkit.from_string(html, './test/%s.pdf'%(i+1))
end_time = time.time()
print('一共耗时:%s 秒.' %(end_time-start_time))
在这个程序中,生成100份PDF文件一共耗时约192秒。输出结果如下:
......
Loading pages (1/6)
Counting pages (2/6)
Resolving links (4/6)
Loading headers and footers (5/6)
Printing pages (6/6)
Done
一共耗时:191.9226369857788 秒.
如果想要加快生成的速度,我们可以使用多线程来实现,主要使用concurrent.futures模块,完整的Python代码如下:
import pdfkit
import time
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED
start_time = time.time()
# 函数: 生成PDF
def convert_2_pdf(i):
content = '这是第%d份测试文件!'%(i+1)
html = '<html><head><meta charset="UTF-8"></head>' \
'<body><div align="center">%s</div></body></html>' % content
# 转换为PDF
pdfkit.from_string(html, './test/%s.pdf'%(i+1))
# 利用多线程生成PDF
executor = ThreadPoolExecutor(max_workers=10) # 可以自己调整max_workers,即线程的个数
# submit()的参数: 第一个为函数, 之后为该函数的传入参数,允许有多个
future_tasks = [executor.submit(convert_2_pdf, i) for i in range(100)]
# 等待所有的线程完成,才进入后续的执行
wait(future_tasks, return_when=ALL_COMPLETED)
end_time = time.time()
print('一共耗时:%s 秒.' %(end_time-start_time))
在这个程序中,生成100份PDF文件一共耗时约41秒,明显快了很多~
总结
以上所述是小编给大家介绍的将Python字符串生成PDF的相关知识,希望对大家有所帮助,如果大家有任何疑问欢迎给我留言,小编会及时回复大家的!
相关推荐
-

python批量实现Word文件转换为PDF文件
本文为大家分享了python批量转换Word文件为PDF文件的具体方法,供大家参考,具体内容如下 1.目的 通过万能的Python把一个目录下的所有Word文件转换为PDF文件. 2.遍历目录 作者总结了三种遍历目录的方法,分别如下. 2.1.调用glob 遍历指定目录下的所有文件和文件夹,不递归遍历,需要手动完成递归遍历功能. import glob as gb path = gb.glob('d:\\2\\*') for path in path: print path 2.2.调用os.w
-
python实现pdf转换成word/txt纯文本文件
本文实例为大家分享了python实现pdf转word/txt,供大家参考,具体内容如下 依赖包:pdfminer3k 可以通过pip安装:也可以到官网下载,解压,进入文件夹,输入命令setup.py install安装软件. 源代码: #!/usr/bin/python # -*- coding: utf-8 -*- import sys import importlib importlib.reload(sys) from pdfminer.pdfparser import PDFParser
-
Python2.7读取PDF文件的方法示例
本文实例讲述了Python2.7读取PDF文件的方法.分享给大家供大家参考,具体如下: 这篇文章示例代码采用的Python版本是2.7,需要下载的插件是PDFMiner,下载地址是http://www.unixuser.org/~euske/python/pdfminer/,地址里有安装方法,我就不再细说了,需要说明的是Python2只能使用PDFMiner,Python3不能使用,Python3可以使用PDFMiner3K,下载地址为https://pypi.python.org/pypi/p
-
Python 将pdf转成图片的方法
本篇文章记录如何使用python将pdf文件切分成一张一张图片,包括环境配置.版本兼容问题. 环境配置(mac) 安装ImageMagick brew install imagemagick 这里有个坑,brew安装都是7.x版本,使用wand时会出错,需要你安装6.x版本. 解决办法: 1.安装6.x版本 brew install imagemagick@6 2.取消链接7.x版本 brew unlink imagemagick Unlinking /usr/local/Cellar/imag
-
Python实现pdf文档转txt的方法示例
本文实例讲述了Python实现pdf文档转txt的方法.分享给大家供大家参考,具体如下: 首先,这是一个比较粗糙的版本,因为已经够用了,而且对pdf的格式不熟悉,所以暂时没有进一步优化. 还有,这是转成txt的,所以如果是有图片的pdf是无法保存图片的. 至于本来就是图片的文本,这里是无法分析出来的.那些图片的pdf,估计要用图形匹配的方式来处理,类似于超速拍摄的车牌识别. 不过这样的程度,已经不是文本处理了.扯远了... 转出来的文字,好像按照pdf里面的所展示的来换行了,看不到有什么规则还原
-
windows下Python实现将pdf文件转化为png格式图片的方法
本文实例讲述了windows下Python实现将pdf文件转化为png格式图片的方法.分享给大家供大家参考,具体如下: 最近工作中需要把pdf文件转化为图片,想用Python来实现,于是在网上找啊找啊找啊找,找了半天,倒是找到一些代码. 1.第一个找到的代码,我试了一下好像是反了,只能实现把图片转为pdf,而不能把pdf转为图片... 参考链接:https://zhidao.baidu.com/question/745221795058982452.html 代码如下: #!/usr/bin/e
-
Python解析并读取PDF文件内容的方法
本文实例讲述了Python解析并读取PDF文件内容的方法.分享给大家供大家参考,具体如下: 一.问题描述 利用python,去读取pdf文本内容. 二.效果 三.运行环境 python2.7 四.需要安装的库 pip install pdfminer 五.实现源代码 代码1(win64) # coding=utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') import time time1=time.time() impor
-
浅谈Python处理PDF的方法
处理pdf文档 第一. 从文本中提取文本 第二. 创建PDF 两种方法 #使用PdfFileWriter import PyPDF2 pdfFiles = [] for filename in os.listdir('.'): if filename.endswith('.pdf'): pdfFiles.append(filename) print(pdfFiles) pdfWriter = PyPDF2.PdfFileWriter() pdfFileObj = open(pdfFiles[0]
-
将Python字符串生成PDF的实例代码详解
笔者在今天的工作中,遇到了一个需求,那就是如何将Python字符串生成PDF.比如,需要把Python字符串'这是测试文件'生成为PDF, 该PDF中含有文字'这是测试文件'. 经过一番检索,笔者决定采用wkhtmltopdf这个软件,它可以将HTML转化为PDF.wkhtmltopdf的访问网址为:https://wkhtmltopdf.org/downloads.html ,读者可根据自己的系统下载对应的文件并安装.安装好wkhtmltopdf,我们再安装这个软件的Python第三方模块
-
Python中变量的输入输出实例代码详解
1.变量的输入: input函数: input() input("请输入银行卡密码") password = input("请输入银行卡密码") 变量名 = input("XXX") # 用输入函数给变量赋值 输入函数给变量赋值举例: 注:所有input()得到的数据类型都是str字符串类型 2.变量类型的转换函数: • int(x) # str转整数 • float(x) # str转小数 转换举例: 3.输入综合练习: # 1.输入苹果的单价
-
Python生成验证码、计算具体日期是一年中的第几天实例代码详解
1.约瑟夫环问题 <幸运的基督徒> 有15个基督徒和15个非基督徒在海上遇险,为了能让一部分人活下来不得不将其中15个人扔到海里面去,有个人想了个办法就是大家围成一个圈,由某个人开始从1报数,报到9的人就扔到海里面,他后面的人接着从1开始报数,报到9的人继续扔到海里面,直到扔掉15个人.由于上帝的保佑,15个基督徒都幸免于难,问这些人最开始是怎么站的,哪些位置是基督徒哪些位置是非基督徒. def main(): ''' 先用列表中每个数字代表每个人,然后通过循环替换列表中的数字 用@代表基督徒
-
Python中使用pypdf2合并、分割、加密pdf文件的代码详解
朋友需要对一个pdf文件进行分割,在网上查了查发现这个pypdf2可以完成这些操作,所以就研究了下这个库,并做一些记录.首先pypdf2是python3版本的,在之前的2版本有一个对应pypdf库. 可以使用pip直接安装: pip install pypdf2 官方文档: pythonhosted.org/PyPDF2/ 里面主要有这几个类: PdfFileReader . 该类主要提供了对pdf文件的读操作,其构造方法为: PdfFileReader(stream, strict=True,
-
python获取时间及时间格式转换问题实例代码详解
整理总结一下python中最常用的一些时间戳和时间格式的转换 第一部分:获取当前时间和10位13位时间戳 import datetime, time '''获取当前时间''' n = datetime.datetime.now() print(n) '''获取10位时间戳''' now = time.time() print(int(now)) '''获取13位时间戳''' now2 = round(now*1000) print(now2) 运行结果为: 2018-12-06 11:00:30
-
使用 Opentype.js 生成字体子集的实例代码详解
字体子集是将字体文件中部分多余的字符删除,来减小文件大小,从而在 Web 端使用或嵌入到其他应用或系统中,在网上可以找到不少这方面的工具. Opentype.js是一套可以支持浏览器环境和 Node.js 环境的开源 OpenType 字体读写库,利用这个库可以很轻松实现浏览器环境和 Node.js 环境的字体子集功能. 在浏览器环境创建字体子集工具 首先创建一个简单的 HTML界面,包括一个选取字体文件按钮,一个输入框用于输入保留的字符,和一个保存下载按钮. HTML <!DOCTYPE ht
-
Python 八个数据清洗实例代码详解
如果你经历过数据清洗的过程,你就会明白我的意思.而这正是撰写这篇文章的目的——让读者更轻松地进行数据清洗工作. 事实上,我在不久前意识到,在进行数据清洗时,有一些数据具有相似的模式.也正是从那时起,我开始整理并编译了一些数据清洗代码,我认为这些代码也适用于其它的常见场景. 由于这些常见的场景涉及到不同类型的数据集,因此本文更加侧重于展示和解释这些代码可以用于完成哪些工作,以便读者更加方便地使用它们. 数据清洗小工具箱 在下面的代码片段中,数据清洗代码被封装在了一些函数中,代码的目的十分直观.你可
-
Mybatis逆向生成使用扩展类的实例代码详解
1.背景介绍 用的mybatis自动生成的插件,然而每次更改数据库的时候重新生成需要替换原有的mapper.xml文件,都要把之前业务相关的sql重新写一遍,感觉十分麻烦,就想着把自动生成的作为一个基础文件,然后业务相关的写在扩展文件里面,这样更改数据库后只需要把所有基础文件替换掉就可以了 2.代码 2.1 BaseMapper.java 把自动生成的方法都抽到一个base类,然后可以写一些公共的方法 /** * @author 吕梁山 * @date 2019/4/23 */ public i
-
JS字符串与二进制的相互转化实例代码详解
JS字符串与二进制的相互转化的方法,具体代码如下所示: //字符串转ascii码,用charCodeAt(); //ascii码转字符串,用fromCharCode(); var str = "A"; var code = str.charCodeAt(); var str2 = String.fromCharCode(code); 十进制转二进制 var a = "i"; console.log(a.charCodeAt()); //105 console.log
-
Python 带有参数的装饰器实例代码详解
demo.py(装饰器,带参数的装饰器): def set_level(level_num): def set_func(func): def call_func(*args, **kwargs): if level_num == 1: print("----权限级别1,验证----") elif level_num == 2: print("----权限级别2,验证----") return func() return call_func return set_f