详解spring cloud分布式日志链路跟踪
首先要明白一点,为什么要使用链路跟踪?
当我们微服务之间调用的时候可能会出错,但是我们不知道是哪个服务的问题,这时候就可以通过日志链路跟踪发现哪个服务出错。
它还有一个好处:当我们在企业中,可能每个人都负责一个服务,我们可以通过日志来检查自己所负责的服务不会出错,当调用其它服务时,这时候出现错误,那么就可以判定出不是自己的服务出错,从而也可以发现责任不是自己的。
基于微服务之间的调用开始,如果看不懂的小伙伴,请先参考我上篇博客:spring cloud中微服务之间的调用以及eureka的自我保护机制
首先,我们先在project-solr和project-shopping-mall里加配置:
project-solr中的application.yml:
logging: path: D:\work\logs\project-solr #打印存放日志的路径 level: com.gaofei: info #包名下日志的级别
project-shopping-mall中的application.yml:
logging: path: D:\work\logs\project-shopping-mall #打印存放日志的路径 level: com.gaofei: info #包下面日志级别
大家可以看出我两个服务里的日志存放的路径不一样,这样也便于区分
在project-solr里的constroller里:
@RestController//这里使此Constroller中所有的方法返回的不是页面
public class SolrSearchConstroller {
public static Logger logger=LoggerFactory.getLogger(SolrSearchConstroller.class);
@RequestMapping("/SolrSearch")
public String SolrSearch(){
logger.info("Solr被调用");
return "这里是Solr";
}
}
在project-shopping-mall里的constroller:
@Controller
public class PageController {
public static Logger logger=LoggerFactory.getLogger(PageController.class);
@Autowired
private RestTemplate restTemplate;
@RequestMapping("/toIndex")
public String toIndex(Model model){
logger.info("执行调用");
String msg=restTemplate.getForEntity("http://project-solr/SolrSearch",String.class).getBody();//project-solr是调用注册中心里的名字
logger.info("调用结束");
model.addAttribute("msg",msg);
return "/index";
}
}
接下来执行:
在这里如果没有logs后面的目录它会自动创建
点开两个日志文件:
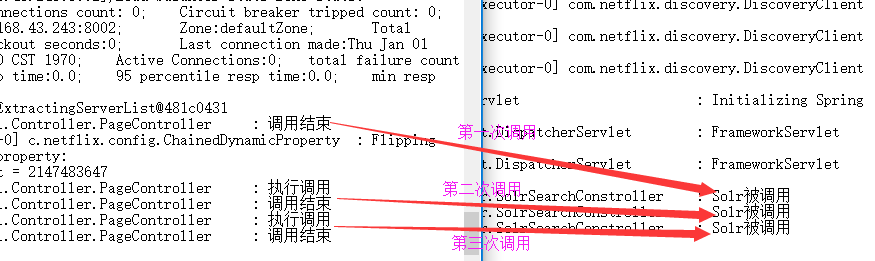
这里因为我运行刷新了3次,所以执行了3次,而两个日志里也对应了三次
如果其中一条报错那么也很快可以找到答案,并且知道哪个日志里报错,也就对应了哪个服务报错
那么问题来了,如果我们在开发中,一天可能会运行n次,那么其中某次运行报错,我们就要在n次调用时来找对应的服务,那么怎么办,我们不可能一一对应查找
这时候我们可以进行链路追踪,只需要在对应的服务器build.gradle加上Spring Cloud Sleuth依赖
//分布式链路依赖 compile group: 'org.springframework.cloud', name: 'spring-cloud-starter-sleuth'
这里我只用到了两个服务project-solr和project-shopping-mall,所以这里就在这两个服务build.gradle中添加
之后执行,打开存放的日志:
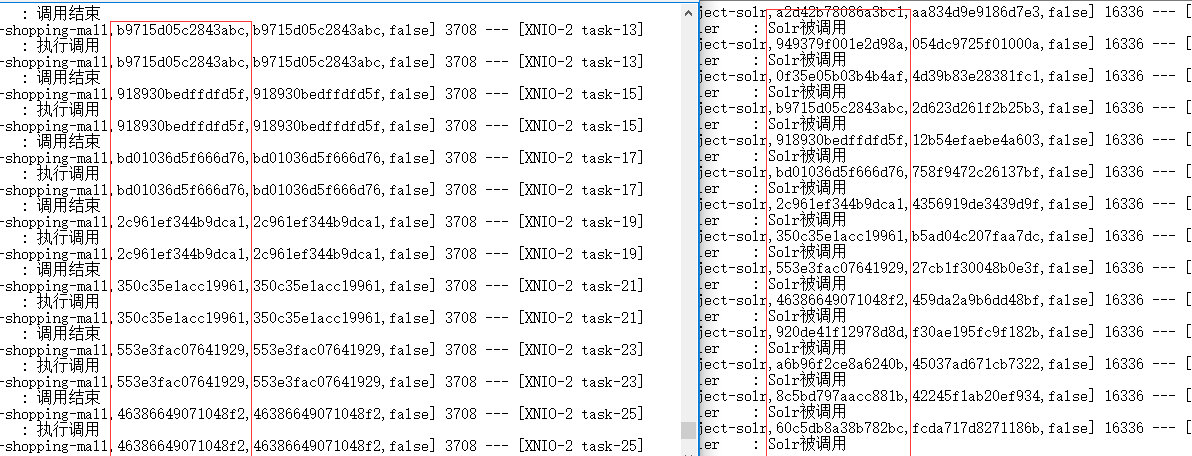
这里我运行刷新了n次,那么怎么在另一个服务找到对应的调用呢?大家仔细看一下红块中的链路是不是对应相应的服务
我随便拿一个进行查找

通过查找可以发现,可以找到对应的链路,那么也就是每次运行都会出现一个链路,可以来查找相应服务的操作是否执行成功,那么这也就是链路追踪
下一篇我会写分布式服务整合zipkin的链路跟踪
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Spring Cloud微服务架构的构建:分布式配置中心(加密解密功能)
前言 要会用,首先要了解.图懒得画,借鉴网上大牛的图吧,springcloud组建架构如图: 微服务架构的应用场景: 1.系统拆分,多个子系统 2.每个子系统可部署多个应用,应用之间负载均衡实现 3.需要一个服务注册中心,所有的服务都在注册中心注册,负载均衡也是通过在注册中心注册的服务来使用一定策略来实现. 4.所有的客户端都通过同一个网关地址访问后台的服务,通过路由配置,网关来判断一个URL请求由哪个服务处理.请求转发到服务上的时候也使用负载均衡. 5.服务之间有时候也需要相互访问.例如有一个
-
spring cloud 分布式链路追踪的方法
一篇讲了微服务之间的调用spring cloud eureka 微服务之间的调用 微服务之间进行调用 那么如果我负责一个模块 别人负责另一个模块 我调用了他的方法 测试那边却报了错 那是我的问题还是他的问题 这个时候大家应该就能想到日志可以解决这个问题 如何使用日志呢 先在配置文件中加 logging: path: D:\logs\poppy-mall #日志的存放地址 最好再加个项目名的文件夹 可以更容易的区分 level: org.poppy.mall: info #日志的级别 org.po
-
详解spring cloud config整合gitlab搭建分布式的配置中心
在前面的博客中,我们都是将配置文件放在各自的服务中,但是这样做有一个缺点,一旦配置修改了,那么我们就必须停机,然后修改配置文件后再进行上线,服务少的话,这样做还无可厚非,但是如果是成百上千的服务了,这个时候,就需要用到分布式的配置管理了.而spring cloud config正是用来解决这个问题而生的.下面就结合gitlab来实现分布式配置中心的搭建.spring cloud config配置中心由server端和client端组成, 前提:在gitlab中的工程下新建一个配置文件config
-
SpringCloud之分布式配置中心Spring Cloud Config高可用配置实例代码
一.简介 当要将配置中心部署到生产环境中时,与服务注册中心一样,我们也希望它是一个高可用的应用.Spring Cloud Config实现服务端的高可用非常简单,主要有以下两种方式. 传统模式:不需要为这些服务端做任何额外的配置,只需要遵守一个配置规则,将所有的Config Server都指向同一个Git仓库,这样所有的配置内容就通过统一的共享文件系统来维护.而客户端在指定Config Server位置时,只需要配置Config Server上层的负载均衡设备地址即可, 就如下图所示的结构. 服
-
Spring Cloud Config实现分布式配置中心
在分布式系统中,配置文件散落在每个项目中,难于集中管理,抑或修改了配置需要重启才能生效.下面我们使用 Spring Cloud Config 来解决这个痛点. Config Server 我们把 config-server 作为 Config Server,只需要加入依赖: <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-config-ser
-
Spring Cloud与分布式系统简析
本文不是讲解如何使用Spring Cloud的教程,而是探讨Spring Cloud是什么,以及它诞生的背景和意义. 背景 2008年以后,国内互联网行业飞速发展,我们对软件系统的需求已经不再是过去"能用就行"这种很low的档次了,像抢红包.双十一这样的活动不断逼迫我们去突破软件系统的性能上限,传统的IT企业"能用就行"的开发思想已经不能满足互联网高并发.大流量的性能要求.系统架构走向分布式已经是服务器开发领域解决该问题唯一的出路,然而分布式系统由于天生的复杂度,并
-
spring cloud config分布式配置中心的高可用问题
在前面的文章中,我们实现了配置文件统一管理的功能,但是我们可以发现,我们仅仅只用了一个server,如果当这个server挂掉的话,整个配置中心就会不可用,下面,我们就来解决配置中心的高可用问题. 下面我们通过整合Eureka来实现配置中心的高可用,因为作为架构内的配置管理,本身其实也是可以看作架构中的一个微服务,我们可以把config server也注册为服务,这样所有客户端就能以服务的方式进行访问.通过这种方法,只需要启动多个指向同一Gitlab仓库位置的config server端就能实现
-
详解spring cloud分布式日志链路跟踪
首先要明白一点,为什么要使用链路跟踪? 当我们微服务之间调用的时候可能会出错,但是我们不知道是哪个服务的问题,这时候就可以通过日志链路跟踪发现哪个服务出错. 它还有一个好处:当我们在企业中,可能每个人都负责一个服务,我们可以通过日志来检查自己所负责的服务不会出错,当调用其它服务时,这时候出现错误,那么就可以判定出不是自己的服务出错,从而也可以发现责任不是自己的. 基于微服务之间的调用开始,如果看不懂的小伙伴,请先参考我上篇博客:spring cloud中微服务之间的调用以及eureka的自我保护
-
详解spring cloud分布式整合zipkin的链路跟踪
为什么使用zipkin? 上篇主要写了:spring cloud分布式日志链路跟踪 从上篇中可以看出服务之间的调用,假设现在有十几台服务,那么在查找日志的时候比较繁琐.复杂,而且在查看调用的时候也会像蜘蛛网一样,量太大. 这时候zipkin可以把链路调用整个过程给升级起来,只需要到一个地方去查找,就可以知道哪一步出错. zipkin也分为服务器和客户端,服务器就是zipkin,微服务就是客户端. 首先,建立服务器zipkin 在此服务build.gradle加上zipkin的依赖: compil
-
详解spring cloud分布式关于熔断器
spring cloud分布式中,熔断器就是断路器,其实都是一个意思. 为什么要使用熔断器呢? 在分布式中,我们会根据业务或功能将项目拆分为多个服务单元,各个服务单元之间通过服务注册和订阅的方式相互依赖和调用功能,随着项目和业务的不断拓展,服务单元数量也逐渐增多,相互之间的依赖关系也越来越复杂,这时候,可能会某个服务单元出现问题或网络原因依赖调用出错或延迟,此时如果调用该依赖的请求不断增加,那么要调用该服务的服务将都会等待或者出现故障,如果后续连锁反应越来越多,Servlet容器的线程资源会被消
-
详解spring cloud config实现datasource的热部署
关于spring cloud config的基本使用,前面的博客中已经说过了,如果不了解的话,请先看以前的博客 spring cloud config整合gitlab搭建分布式的配置中心 spring cloud config分布式配置中心的高可用 今天,我们的重点是如何实现数据源的热部署. 1.在客户端配置数据源 @RefreshScope @Configuration// 配置数据源 public class DataSourceConfigure { @Bean @RefreshScope
-
详解spring cloud构建微服务架构的网关(API GateWay)
前言 在我们前面的博客中讲到,当服务A需要调用服务B的时候,只需要从Eureka中获取B服务的注册实例,然后使用Feign来调用B的服务,使用Ribbon来实现负载均衡,但是,当我们同时向客户端暴漏多个服务的时候,客户端怎么调用我们暴漏的服务了,如果我们还想加入安全认证,权限控制,过滤器以及动态路由等特性了,那么就需要使用Zuul来实现API GateWay了,下面,我们先来看下Zuul怎么使用. 一.加入Zuul的依赖 <dependency> <groupId>org.spri
-
详解spring cloud使用Hystrix实现单个方法的fallback
本文介绍了spring cloud-使用Hystrix实现单个方法的fallback,分享给大家,具体如下: 一.加入Hystrix依赖 <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-hystrix</artifactId> </dependency> 二.编写Controller package c
-
详解Spring Cloud 跨服务数据聚合框架
AG-Merge Spring Cloud 跨服务数据聚合框架 解决问题 解决Spring Cloud服务拆分后分页数据的属性或单个对象的属性拆分之痛, 支持对静态数据属性(数据字典).动态主键数据进行自动注入和转化, 其中聚合的静态数据会进行 一级混存 (guava). 举个栗子: 两个服务,A服务的某张表用到了B服务的某张表的值,我们在对A服务那张表查询的时候,把B服务某张表的值聚合在A服务的那次查询过程中 示例 具体示例代码可以看 ace-merge-demo 模块 |------- ac
-
详解spring cloud整合Swagger2构建RESTful服务的APIs
前言 在前面的博客中,我们将服务注册到了Eureka上,可以从Eureka的UI界面中,看到有哪些服务已经注册到了Eureka Server上,但是,如果我们想查看当前服务提供了哪些RESTful接口方法的话,就无从获取了,传统的方法是梳理一篇服务的接口文档来供开发人员之间来进行交流,这种情况下,很多时候,会造成文档和代码的不一致性,比如说代码改了,但是接口文档没有改等问题,而Swagger2则给我们提供了一套完美的解决方案,下面,我们来看看Swagger2是如何来解决问题的. 一.引入Swag
-
详解Spring Cloud Feign 熔断配置的一些小坑
1.在使用feign做服务调用时,使用继承的方式调用服务,加入Hystrix的熔断处理fallback配置时,会报错,已解决. 2.使用feign默认配置,熔断不生效,已解决. 最近在做微服务的学习,发现在使用feign做服务调用时,使用继承的方式调用服务,加入Hystrix的熔断处理fallback配置时,会报错,代码如下: @RequestMapping("/demo/api") public interface HelloApi { @GetMapping("user/