Oracle常见分析函数实例详解
目录
- 1. 认识分析函数
- 1.1 什么是分析函数
- 1.2 分析函数和聚合函数的不同
- 1.3 分析函数的形式
- 2. 理解over()函数
- 2.1 两个order by 的执行机制
- 2.2 分析函数中的分组、排序、窗口
- 2.3 帮助理解over()的实例
- 3. 常见分析函数
- 3.1 演示表和数据的生成
- 3.2 first_value()与last_value():求最值对应的其他属性
- 3.3 rank()、dense_rank()与row_number() 排序问题
- 3.4 lag()与lead():求之前或之后的第N行
- 3.5 rollup()与cube():排列组合分组
- 3.6 max()、min()、sum()与avg():求移动的最值、总和与平均值
- 3.7 ratio_to_report():求百分比
- 总结
1. 认识分析函数
1.1 什么是分析函数
分析函数是Oracle专门用于解决复杂报表统计需求的功能强大的函数,它可以在数据中进行分组然后计算基于组的某种统计值,并且每一组的每一行都可以返回一个统计值。
1.2 分析函数和聚合函数的不同
普通的聚合函数用group by分组,每个分组返回一个统计值;而分析函数采用partition by 分组,并且每组每行都可以返回一个统计值。
1.3 分析函数的形式
分析函数带有一个开窗函数over(),包含三个分析子句:分组(partition by),排序(order by), 窗口(rows),他们的使用形式如下:
over(partition by xxx order by yyy rows between zzz) -- 例如在scott.emp表中:xxx为deptno, yyy为sal, -- zzz为unbounded preceding and unbounded following
分析函数的例子:
显示各部门员工的工资,并附带显示该部分的最高工资。
SQL如下:
SELECT DEPTNO, EMPNO, ENAME, SAL, LAST_VALUE(SAL) OVER (PARTITION BY DEPTNO ORDER BY SAL ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) MAX_SAL FROM EMP;
结果为:
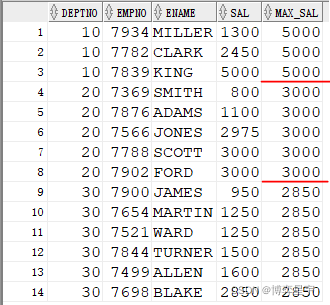
注: current row 表示当前行
unbounded preceding 表示第一行
unbounded following 表示最后一行
last_value(sal) 的结果与 order by sal 排序有关。如果排序为order by sal desc, 则最终的结果为分组排序后sal的最小值(分组排序后的最后一个值), 当deptno为10时,max_sal为1300。
2. 理解over()函数
2.1 两个order by 的执行机制
分析函数是在整个SQL查询结束后(SQL语句中的order by 的执行比较特殊)再进行的操作,也就是说SQL语句中的order by也会影响分析函数的执行结果:
- 两者一致:如果SQL语句中的order by 满足分析函数分析时要求的排序,那么SQL语句中的排序将先执行,分析函数在分析时就不必再排序。
- 两者不一致:如果SQL语句中的order by 不满足分析函数分析时要求的排序,那么SQL语句中的排序将最后在分析函数分析结束后执行排序。
2.2 分析函数中的分组、排序、窗口
分析函数包含三个分析子句:分组(partition by)、排序(order by)、窗口(rows)。
窗口就是分析函数分析时要处理的数据范围,就拿sum来说,它是sum窗口中的记录而不是整个分组中的记录。因此我们在想得到某个栏位的累计值时,我们需要把窗口指定到该分组中的第一行数据到当前行,如果你指定该窗口从该分组中的第一行到最后一行,那么该组中的每一个sum值都会一样,即整个组的总和。
窗口子句中我们经常用到指定第一行,当前行,最后一行这样的三个属性:
- 第一行是 unbounded preceding
- 当前行是 current row
- 最后一行是 unbounded following
窗口子句不能单独出现,必须有order by 子句时才能出现,如:
LAST_VALUE(SAL) OVER (PARTITION BY DEPTNO ORDER BY SAL ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING )
以上示例指定窗口为整个分组.
而出现order by 子句的时候,不一定要有窗口子句,但效果会不一样,此时窗口默认是当前组的第一行到当前行!
SQL语句为:
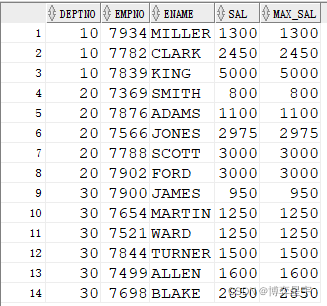
SELECT DEPTNO, EMPNO, ENAME, SAL, last_value(SAL) OVER(PARTITION BY DEPTNO ORDER BY SAL) MAX_SAL FROM EMP;
等价于
SELECT DEPTNO, EMPNO, ENAME, SAL,last_value(SAL) OVER(PARTITION BY DEPTNO ORDER BY SAL ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) MAX_SAL FROM EMP;
结果如下图所示:
当省略窗口子句时:
- 如果存在order by, 则默认的窗口是 unbounded preceding and current row.
- 如果同时省略order by, 则默认的窗口是 unbounded preceding and unbounded following.
如果省略分组,则把全部记录当成一个组:
- 如果存在order by 则默认窗口是unbounded preceding and current row
- 如果这时省略order by 则窗口默认为 unbounded preceding and unbounded following
2.3 帮助理解over()的实例
例1:关注点:SQL无排序,over()排序子句省略
select deptno, empno, ename, sal, last_value(sal) over(partition by deptno) from emp;

例2:关注点:SQL无排序,over()排序子句有,窗口省略
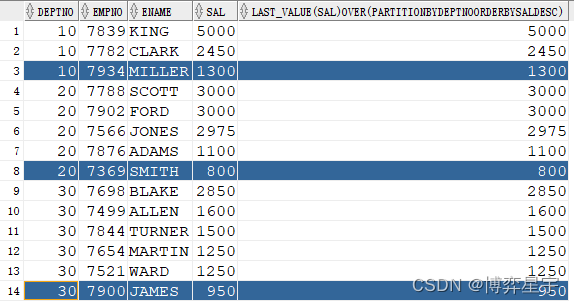
select deptno, empno, ename, sal, last_value(sal) over(partition by deptno order by sal desc) from emp;
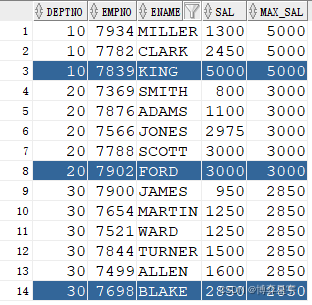
例3:关注点:SQL无排序,over()排序子句有,窗口也有,窗口特意强调全组数据
select deptno, empno, ename, sal, last_value(sal) over(partition by deptno order by sal rows between unbounded preceding and unbounded following) max_sal from emp;
例4:关注点:SQL有排序(正序),over() 排序子句无,先做SQL排序再进行分析函数运算
select deptno, mgr, ename, sal, hiredate, last_value(sal) over(partition by deptno) last_value from emp where deptno=30 order by deptno, mgr;
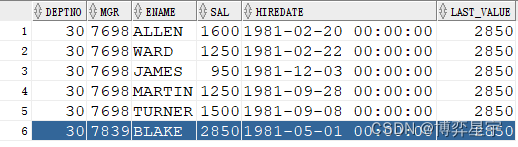
例5:关注点:SQL有排序(倒序),over() 排序子句无,先做SQL排序再进行分析函数运算
select deptno, mgr, ename, sal, hiredate, last_value(sal) over(partition by deptno) last_value from emp where deptno=30 order by deptno, mgr desc;
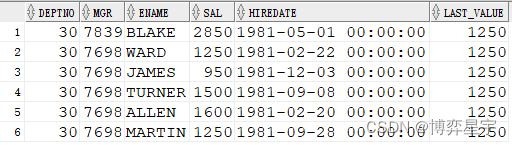
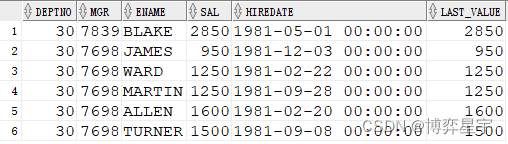
例6:关注点:SQL有排序(倒序),over()排序子句有,窗口子句无,此时的运算是:SQL先选数据但是不排序,而后排序子句先排序并进行分析函数处理(窗口默认为第一行到当前行),最后再进行SQL排序
select deptno, mgr, ename, sal, hiredate, min(sal) over(partition by deptno order by sal)last_value from emp where deptno=30 order by deptno, mgr desc;

select deptno, mgr, ename, sal, hiredate, min(sal) over(partition by deptno order by sal desc) last_value from emp where deptno=30 order by deptno, mgr desc;
3. 常见分析函数
3.1 演示表和数据的生成
建表语句:
create table t( BILL_MONTH VARCHAR2(12), AREA_CODE NUMBER, NET_TYPE VARCHAR(2), LOCAL_FARE NUMBER );
插入数据:
insert into t values('200405',5761,'G', 7393344.04);
insert into t values('200405',5761,'J', 5667089.85);
insert into t values('200405',5762,'G', 6315075.96);
insert into t values('200405',5762,'J', 6328716.15);
insert into t values('200405',5763,'G', 8861742.59);
insert into t values('200405',5763,'J', 7788036.32);
insert into t values('200405',5764,'G', 6028670.45);
insert into t values('200405',5764,'J', 6459121.49);
insert into t values('200405',5765,'G', 13156065.77);
insert into t values('200405',5765,'J', 11901671.70);
insert into t values('200406',5761,'G', 7614587.96);
insert into t values('200406',5761,'J', 5704343.05);
insert into t values('200406',5762,'G', 6556992.60);
insert into t values('200406',5762,'J', 6238068.05);
insert into t values('200406',5763,'G', 9130055.46);
insert into t values('200406',5763,'J', 7990460.25);
insert into t values('200406',5764,'G', 6387706.01);
insert into t values('200406',5764,'J', 6907481.66);
insert into t values('200406',5765,'G', 13562968.81);
insert into t values('200406',5765,'J', 12495492.50);
insert into t values('200407',5761,'G', 7987050.65);
insert into t values('200407',5761,'J', 5723215.28);
insert into t values('200407',5762,'G', 6833096.68);
insert into t values('200407',5762,'J', 6391201.44);
insert into t values('200407',5763,'G', 9410815.91);
insert into t values('200407',5763,'J', 8076677.41);
insert into t values('200407',5764,'G', 6456433.23);
insert into t values('200407',5764,'J', 6987660.53);
insert into t values('200407',5765,'G', 14000101.20);
insert into t values('200407',5765,'J', 12301780.20);
insert into t values('200408',5761,'G', 8085170.84);
insert into t values('200408',5761,'J', 6050611.37);
insert into t values('200408',5762,'G', 6854584.22);
insert into t values('200408',5762,'J', 6521884.50);
insert into t values('200408',5763,'G', 9468707.65);
insert into t values('200408',5763,'J', 8460049.43);
insert into t values('200408',5764,'G', 6587559.23);
insert into t values('200408',5764,'J', 7342135.86);
insert into t values('200408',5765,'G', 14450586.63);
insert into t values('200408',5765,'J', 12680052.38);
commit;
3.2 first_value()与last_value():求最值对应的其他属性
问题:取出每个月通话费最高和最低的两个地区
思路:先进行group by bill_month, area_code使用聚合函数sum()求解出by bill_month, area_code的local_fare总和, 即sum(local_fare), 然后再运用分析函数进行求解每个月通话费用最高和最低的两个地区。
select bill_month, area_code, sum(local_fare) local_fare, first_value(area_code) over(partition by bill_month order by sum(local_fare) desc rows between unbounded preceding and unbounded following) firstval, last_value(area_code) over(partition by bill_month order by sum(local_fare) desc rows between unbounded preceding and unbounded following) lastval from t group by bill_month, area_code;

3.3 rank()、dense_rank()与row_number() 排序问题
演示数据再Oracle自带的scott用户下
1.rank()值相同时排名相同,其后排名跳跃不连续
select * from ( select deptno, ename, sal, rank() over(partition by deptno order by sal desc) rw from emp ) where rw < 4;

2. dense_rank()值相同时排名相同,其后排名连续不跳跃
select * from ( select deptno, ename, sal, dense_rank() over(partition by deptno order by sal desc) rw from emp ) where rw <= 4;
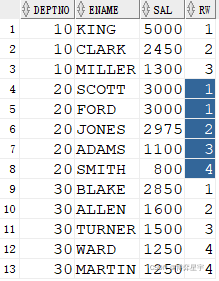
3. row_number()值相同时排名不相等,其后排名连续不跳跃
select * from ( select deptno, ename, sal, row_number() over(partition by deptno order by sal desc) rw from emp ) where rw <= 4;
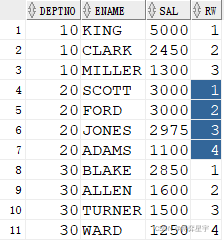
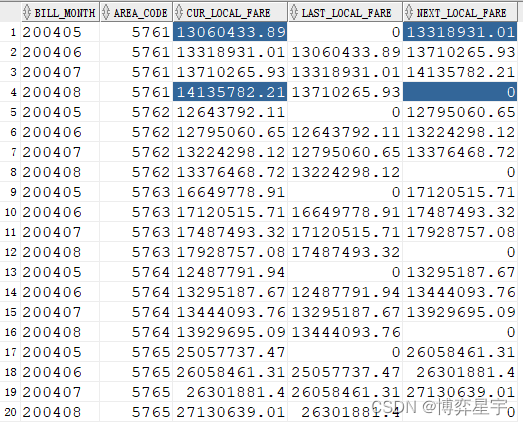
3.4 lag()与lead():求之前或之后的第N行
lag(arg1, arg2, arg3):
- arg1:是从其他行返回的表达式
- arg2:是希望检索的当前行分区的偏移量。是一个正的偏移量,是一个往回检索以前的行数目
- arg3:是在arg2表示的数目超出了分组的范围时返回的值
而lead()与lag()相反
select bill_month, area_code, local_fare cur_local_fare,
lag(local_fare, 1, 0) over(partition by area_code order by bill_month)
last_local_fare,
lead(local_fare, 1, 0) over(partition by area_code order by bill_month)
next_local_fare
from (select bill_month, area_code, sum(local_fare) local_fare
from t group by bill_month, area_code);
3.5 rollup()与cube():排列组合分组
group by rollup(A, B, C):
首先会对 (A, B, C) 进行group by,
然后再对 (A, B) 进行group by,
其后再对 (A) 进行group by,
最后对全表进行汇总操作。
group by cube(A, B, C):
则首先会对 (A, B, C) 进行group by,
然后依次是 (A, B), (A, C), (A), (B, C), (B), (C),
最后对全表进行汇总操作。
1.生成演示数据:
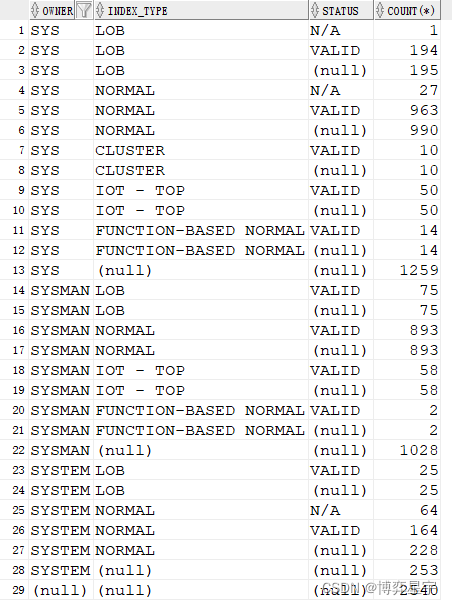
create table scott.tt as select * from dba_indexes;
2.普通group by 体验
select owner, index_type, status, count(*) from tt where owner like 'SY%' group by owner, index_type, status;

3. group by rollup(A, B, C):
首先会对 (A, B, C) 进行group by,
然后再对 (A, B) 进行group by,
其后再对 (A) 进行group by,
最后对全表进行汇总操作。
select owner, index_type, status, count(*) from tt where owner like 'SY%' group by rollup(owner, index_type, status);
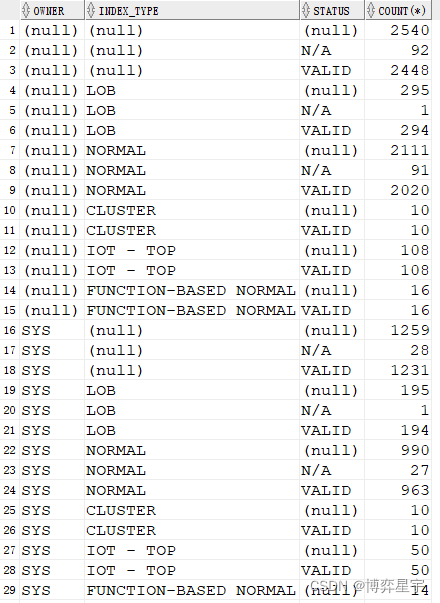
4. group by cube(A, B, C):
则首先会对 (A, B, C) 进行group by,
然后依次是 (A, B), (A, C), (A), (B, C), (B), (C),
最后对全表进行汇总操作。
select owner, index_type, status, count(*) from tt where owner like 'SY%' group by cube(owner, index_type, status);
(只截取了部分图)
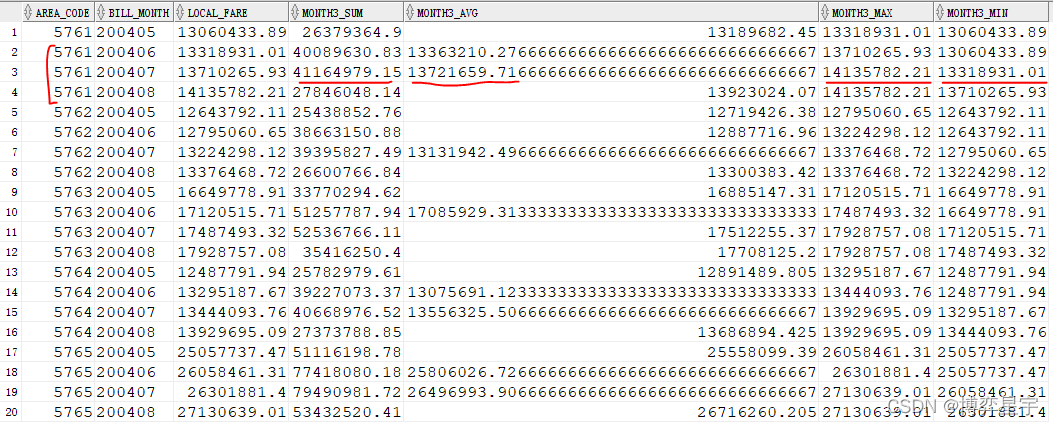
3.6 max()、min()、sum()与avg():求移动的最值、总和与平均值
问题:计算出各个地区连续3个月的通话费用的平均数(移动平均值)
select area_code, bill_month, local_fare,
sum(local_fare) over(partition by area_code order by to_number(bill_month)
range between 1 preceding and 1 following) month3_sum,
avg(local_fare) over(partition by area_code order by to_number(bill_month)
range between 1 preceding and 1 following) month3_avg,
max(local_fare) over(partition by area_code order by to_number(bill_month)
range between 1 preceding and 1 following) month3_max,
min(local_fare) over(partition by area_code order by to_number(bill_month)
range between 1 preceding and 1 following) month3_min
from (select bill_month, area_code, sum(local_fare) local_fare from t
group by area_code, bill_month);
问题:求各地区按月份累加的通话费
select area_code, bill_month, local_fare, sum(local_fare) over(partition by area_code order by bill_month asc) last_sum_value from(select area_code, bill_month, sum(local_fare) local_fare from t group by area_code, bill_month) order by area_code, bill_month;

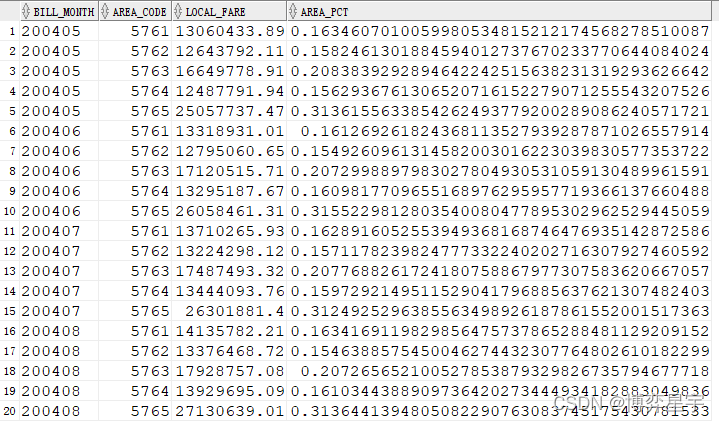
3.7 ratio_to_report():求百分比
问题:求各地区花费占各月花费的比例
select bill_month, area_code, sum(local_fare) local_fare, RATIO_TO_REPORT(sum(local_fare)) OVER (partition by bill_month) AS area_pct from t group by bill_month, area_code;
总结
到此这篇关于Oracle常见分析函数的文章就介绍到这了,更多相关Oracle分析函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Oracle分析函数用法详解
一.概述 OLAP的系统(即Online Aanalyse Process)一般用于系统决策使用.通常和数据仓库.数据分析.数据挖掘等概念联系在一起.这些系统的特点是数据量大,对实时响应的要求不高或者根本不关注这方面的要求,以查询.统计操作为主. 我们来看看下面的几个典型例子: ①查找上一年度各个销售区域排名前10的员工 ②按区域查找上一年度订单总额占区域订单总额20%以上的客户 ③查找上一年度销售最差的部门所在的区域 ④查找上一年度销售最好和最差的产品 我们看看上面的几个例子就可以感觉到这几个
-
Oracle开发之分析函数总结
这一篇是对前面所有关于分析函数的文章的总结: 一.统计方面: 复制代码 代码如下: Sum() Over ([Partition by ] [Order by ]) Sum() Over ([Partition by ] [Order by ] Rows Between Preceding And Following) Sum() Over ([Partition by ] [Order by ] Rows Between Preceding An
-
oracle常用分析函数与聚合函数的用法
今天是2019年第一天,在此祝大家新年快乐,梦想还在路上,让我们继续加油! 应之前的计划,今天完成这篇记录,也借此记录自己的成长. 一.几个排名函数的语法和用法: rank ( ) over ([partition by col] order by col ) dense_rank ( ) over ([partition by col] order by col ) rownumber ( ) over ( [partition by col] order by col ) rank
-
常用Oracle分析函数大全
Oracle的分析函数功能非常强大,工作这些年来经常用到.这次将平时经常使用到的分析函数整理出来,以备日后查看. 我们拿案例来学习,这样理解起来更容易一些. 1.建表 create table earnings -- 打工赚钱表 ( earnmonth varchar2(6), -- 打工月份 area varchar2(20), -- 打工地区 sno varchar2(10), -- 打工者编号 sname varchar2(20), -- 打工者姓名 times int, -- 本月打工次
-
Oracle中的分析函数汇总
一.概述 OLAP的系统(即Online Aanalyse Process)一般用于系统决策使用.通常和数据仓库.数据分析.数据挖掘等概念联系在一起.这些系统的特点是数据量大,对实时响应的要求不高或者根本不关注这方面的要求,以查询.统计操作为主. 我们来看看下面的几个典型例子: ①查找上一年度各个销售区域排名前10的员工 ②按区域查找上一年度订单总额占区域订单总额20%以上的客户 ③查找上一年度销售最差的部门所在的区域 ④查找上一年度销售最好和最差的产品 我们看看上面的几个例子就可以感觉到这几个
-
Oracle数据库分析函数用法
目录 1.什么是窗口函数? 2.窗口函数--开窗 3.一些分析函数的使用方法 4.OVER()参数--分组函数 5.OVER()参数--排序函数 1.什么是窗口函数? 窗口函数也属于分析函数.Oracle从8.1.6开始提供窗口函数,窗口函数用于计算基于组的某种聚合值, 窗口函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化. 与聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行 基本语法: ‹分析函数› over (partition by ‹
-
Oracle常见分析函数实例详解
目录 1. 认识分析函数 1.1 什么是分析函数 1.2 分析函数和聚合函数的不同 1.3 分析函数的形式 2. 理解over()函数 2.1 两个order by 的执行机制 2.2 分析函数中的分组.排序.窗口 2.3 帮助理解over()的实例 3. 常见分析函数 3.1 演示表和数据的生成 3.2 first_value()与last_value():求最值对应的其他属性 3.3 rank().dense_rank()与row_number() 排序问题 3.4 lag()与lead()
-
Oracle addBatch()用法实例详解
Oracle addBatch()用法实例详解 PreparedStatement.addbatch()的使用 Statement和PreparedStatement的区别就不多废话了,直接说PreparedStatement最重要的addbatch()结构的使用. 1.建立链接 Connection connection =getConnection(); 2.不自动 Commit connection.setAutoCommit(false); 3.预编译SQL语句,只编译一回哦,效
-
Java导出oracle表结构实例详解
Java导出oracle表结构实例详解 最近用到的,因为plsql是收费的,不让用,找了很多方法终于发现了这个. 核心语句 SELECT DBMS_METADATA.GET_DDL(U.OBJECT_TYPE, U.object_name), U.OBJECT_TYPE FROM USER_OBJECTS U where U.OBJECT_TYPE = 'TABLE' or U.OBJECT_TYPE = 'VIEW' or U.OBJECT_TYPE = 'INDEX' or U.OBJEC
-
Oracle例外用法实例详解
本文实例讲述了Oracle例外用法.分享给大家供大家参考,具体如下: 一.例外分类 oracle将例外分为预定义例外.非预定义例外和自定义例外三种. 1).预定义例外用于处理常见的oracle错误. 2).非预定义例外用于处理预定义例外不能处理的例外. 3).自定义例外用于处理与oracle错误无关的其它情况. 下面通过一个小案例演示如果不处理例外看会出现什么情况? 编写一个存储过程,可接收雇员的编号,并显示该雇员的姓名. sql代码如下: SET SERVEROUTPUT ON; DECLAR
-
Python字典的概念及常见应用实例详解
本文实例讲述了Python字典的概念及常见应用.分享给大家供大家参考,具体如下: 字典的介绍 字典的概念 字典的创建 1. 我们可以通过{}.dict()来创建字典对象. 2. 通过 zip()创建字典对象 3. 通过 fromkeys 创建值为空的字典 字典元素的访问 1. 通过 [键] 获得"值".若键不存在,则抛出异常. 2. 通过 get()方法获得"值".推荐使用.优点是:指定键不存在,返回 None:也可以设 3. 列出所有的键值对 4. 列出所有的键,
-
Oracle触发器用法实例详解
本文实例讲述了Oracle触发器用法.分享给大家供大家参考,具体如下: 一.触发器简介 触发器的定义就是说某个条件成立的时候,触发器里面所定义的语句就会被自动的执行.因此触发器不需要人为的去调用,也不能调用.然后,触发器的触发条件其实在你定义的时候就已经设定好了.这里面需要说明一下,触发器可以分为语句级触发器和行级触发器.详细的介绍可以参考网上的资料,简单的说就是语句级的触发器可以在某些语句执行前或执行后被触发.而行级触发器则是在定义的了触发的表中的行数据改变时就会被触发一次. 具体举例: 1.
-
JS正则表达式常见用法实例详解
本文实例讲述了JS正则表达式常见用法.分享给大家供大家参考,具体如下: 前言:正则表达式(regular expression)反反复复学了多次,学了又忘,忘了又学,这次打算把基本的东西都整理出来,加强记忆,也方便下次查询. 学习正则表达式之前首先需要掌握记忆这些基本概念: 1.元字符:(.,\w,\W,\d,\D,\s,/S,^,$,) 字符 含义 . 匹配除了换行符以外的任意字符. \s 代表任意空白符(换行符,制表符,空格) \S 匹配任意非空字符串 \b 匹配单词边界,匹配单词的开头和结
-
Python3.5集合及其常见运算实例详解
本文实例讲述了Python3.5集合及其常见运算.分享给大家供大家参考,具体如下: 1.集合的定义:集合是一个无序的.无重复的数据的数据组合. 2.集合的特征: (1)去除重复元素:将一个列表变成集合就可实现去重. (2)测试关系:测试两组数据之间交集.并集.差集等关系. 3.集合常用的操作: (1)去重复:将列表变成集合,形式:集合=set(列表) list_1 = [1,3,5,3,6,8,9,6,8,1] list_1 = set(list_1) print(list_1,type(lis
-
Python subprocess模块功能与常见用法实例详解
本文实例讲述了Python subprocess模块功能与常见用法.分享给大家供大家参考,具体如下: 一.简介 subprocess最早在2.4版本引入.用来生成子进程,并可以通过管道连接他们的输入/输出/错误,以及获得他们的返回值. subprocess用来替换多个旧模块和函数: os.system os.spawn* os.popen* popen2.* commands.* 运行python的时候,我们都是在创建并运行一个进程,linux中一个进程可以fork一个子进程,并让这个子进程ex
-
js DOM的事件常见操作实例详解
本文实例讲述了js DOM的事件常见操作.分享给大家供大家参考,具体如下: 一.JavaScript的组成 JavaScript基础分为三个部分: ECMAScript:JavaScript的语法标准.包括变量.表达式.运算符.函数.if语句.for语句等. DOM:文档对象模型,操作网页上的元素的API.比如让盒子移动.变色.轮播图等. BOM:浏览器对象模型,操作浏览器部分功能的API.比如让浏览器自动滚动. 二.事件 JS是以事件驱动为核心的一门语言. 事件的三要素 事件的三要素:事件源.