python爬虫之requests库使用代理方式
目录
- 安装上requests库
- GET方法
- 谷歌浏览器的开发者工具
- POST方法
- 使用代理
在看这篇文章之前,需要大家掌握的知识技能:
- python基础
- html基础
- http状态码
让我们看看这篇文章中有哪些知识点:
- get方法
- post方法
- header参数,模拟用户
- data参数,提交数据
- proxies参数,使用代理
- 进阶学习
安装上requests库
pip install requests
先来看下帮助文档,看看requests的介绍,用python自带的help命令
import requests help(requests)
output:
Help on package requests:
NAME
requests
DESCRIPTION
Requests HTTP Library
~~~~~~~~~~~~~~~~~~~~~
Requests is an HTTP library, written in Python, for human beings. Basic GET
usage:
>>> import requests
>>> r = requests.get('https://www.python.org')
>>> r.status_code
200
>>> 'Python is a programming language' in r.content
True
... or POST:
>>> payload = dict(key1='value1', key2='value2')
>>> r = requests.post('https://httpbin.org/post', data=payload)
>>> print(r.text)
{
...
"form": {
"key2": "value2",
"key1": "value1"
},
...
}
The other HTTP methods are supported - see `requests.api`. Full documentation
is at <http://python-requests.org>.
:copyright: (c) 2017 by Kenneth Reitz.
:license: Apache 2.0, see LICENSE for more details.
这里解释下,requests库是由python编写的对人类友好的http库,并且举例了GET与POST的方法。
GET方法
好的,那我们自己来测试下,就以请求百度为例吧,,,(谁让百度这么耐抗的)
import requests
r = requests.get('https://www.baidu.com')
print(r.status_code) #打印返回的http code
print(r.text) #打印返回结果的text
方便点,截了个图给大家看,返回的code是200,说明请求正常拉回网页了。
看下返回的text,有点不对头,少了一些html标签,最起码百度两个字得有吧。嗯,这是什么原因,,,

相信有些同学已经想到了,是没有真实模拟用户的请求,你去爬数据,还不模拟用户请求,那肯定限制你啊。这个时候需要加一个header参数来搞定,至少要加一个user-agent吧。好,那咋们去找一个ua吧。别百度了,自己动手,丰衣足食。教大家一个办法,用谷歌或者火狐的开发者工具。
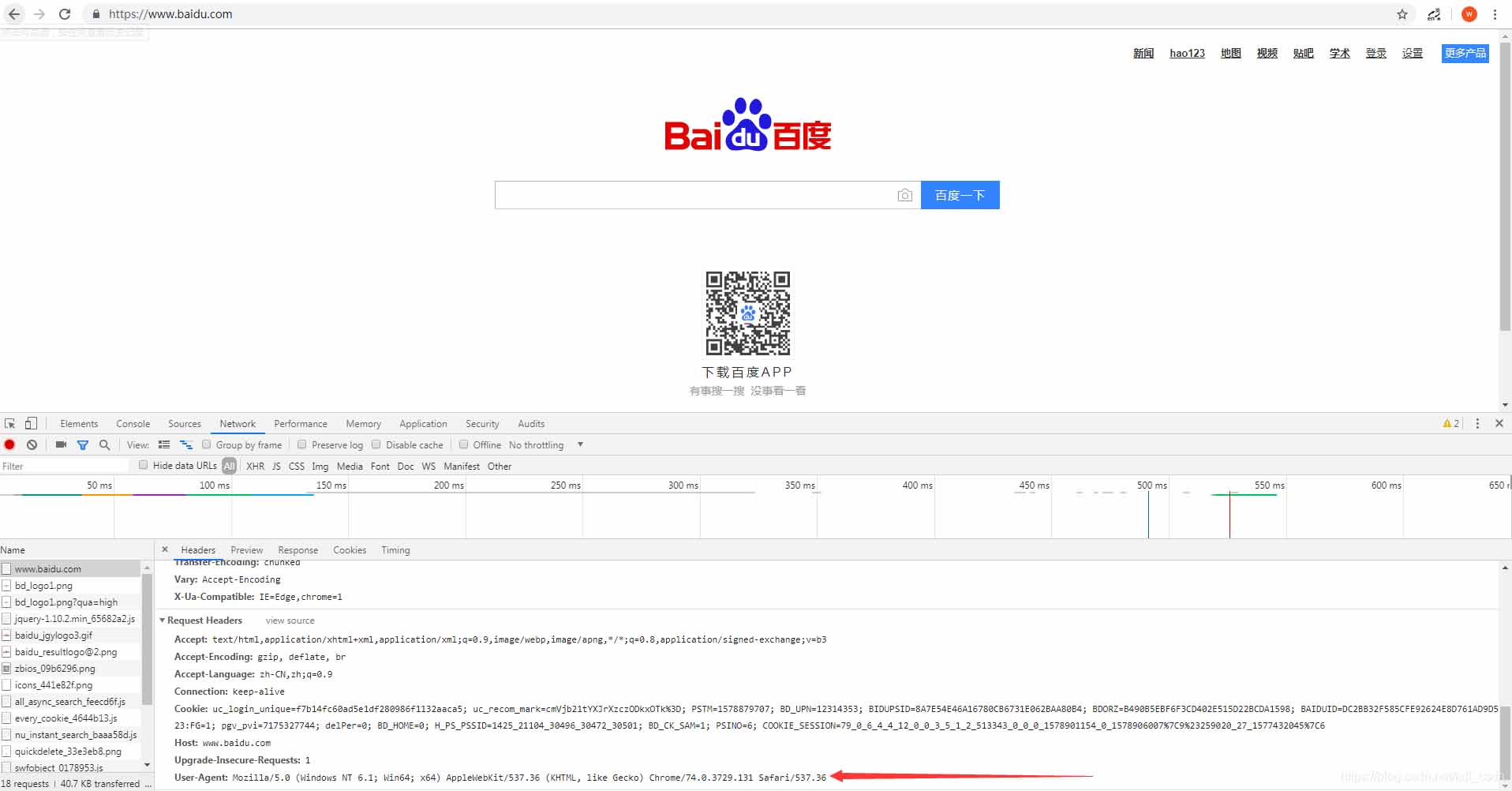
谷歌浏览器的开发者工具
打开新标签 —— 按F12——访问下百度——找到NetWork——随便点开一个——往下翻——看到ua了吧,复制上。
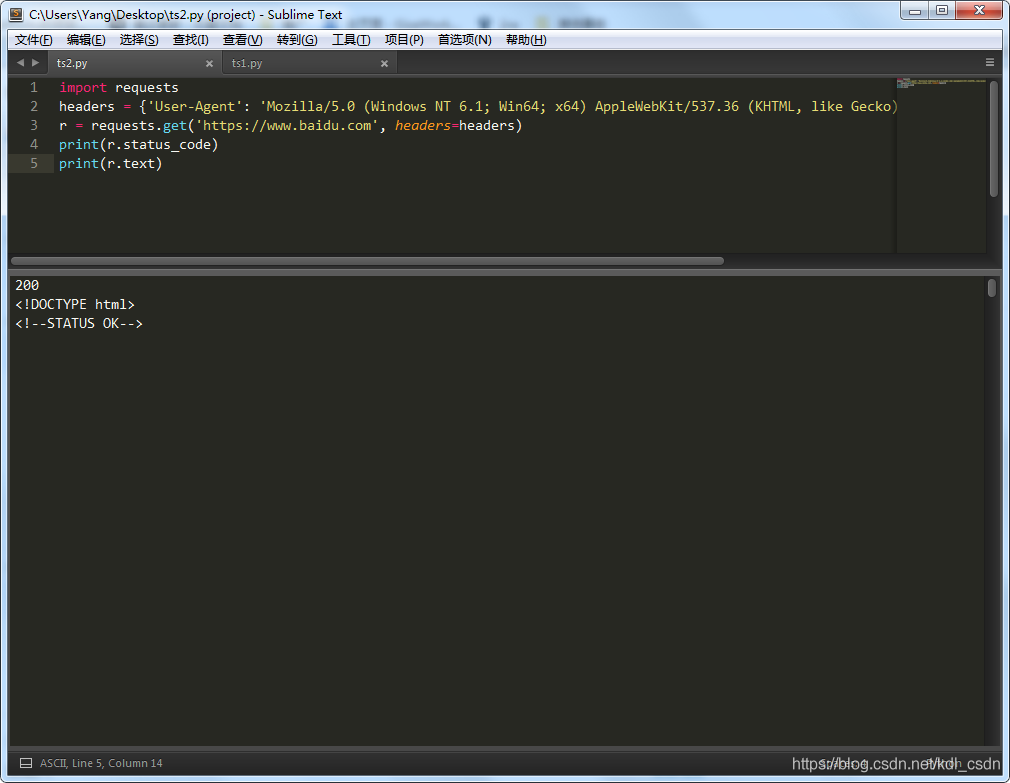
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
r = requests.get('https://www.baidu.com', headers=headers)
print(r.status_code)
print(r.text)
嗯~~~数据有点多,往下翻翻,这下就正常了嘛,数据都有了。。。PS:不信?可以自己输出一个html文件,浏览器打开看看呗
POST方法
只需要把get改成post就好了
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
r = requests.post('https://www.baidu.com', headers=headers)
print(r.status_code)
print(r.text)
运行下试试看。一般post都是用来提交表单信息的,嗯,这里找一个能提交数据的url,去post下。
用我自己写的接口(PS:django写的,挺方便),大家复制过去就好了。注意看代码,data是要post的数据,post方法里加了一个data参数。
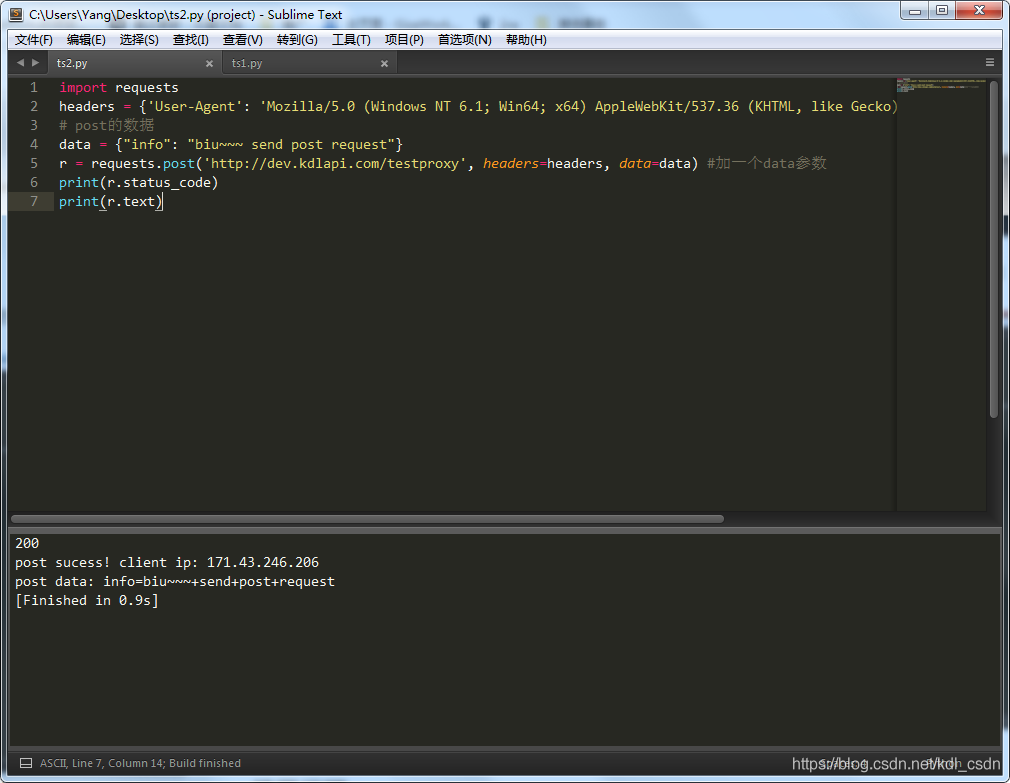
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
# post的数据
data = {"info": "biu~~~ send post request"}
r = requests.post('http://dev.kdlapi.com/testproxy', headers=headers, data=data) #加一个data参数
print(r.status_code)
print(r.text)
截个图给大家看下,http code 200,body信息说的post成功,并且返回的了我自己的IP信息以及post的数据
使用代理
为什么用代理?一般网站都有屏蔽的限制策略,用自己的IP去爬,被封了那该网站就访问不了,这时候就得用代理IP来解决问题了。封吧,反正封的不是本机IP,封的代理IP。
既然使用代理,得先找一个代理IP。PS:自己写个代理服务器太麻烦了,关键是我也不会写啊,,,哈哈哈
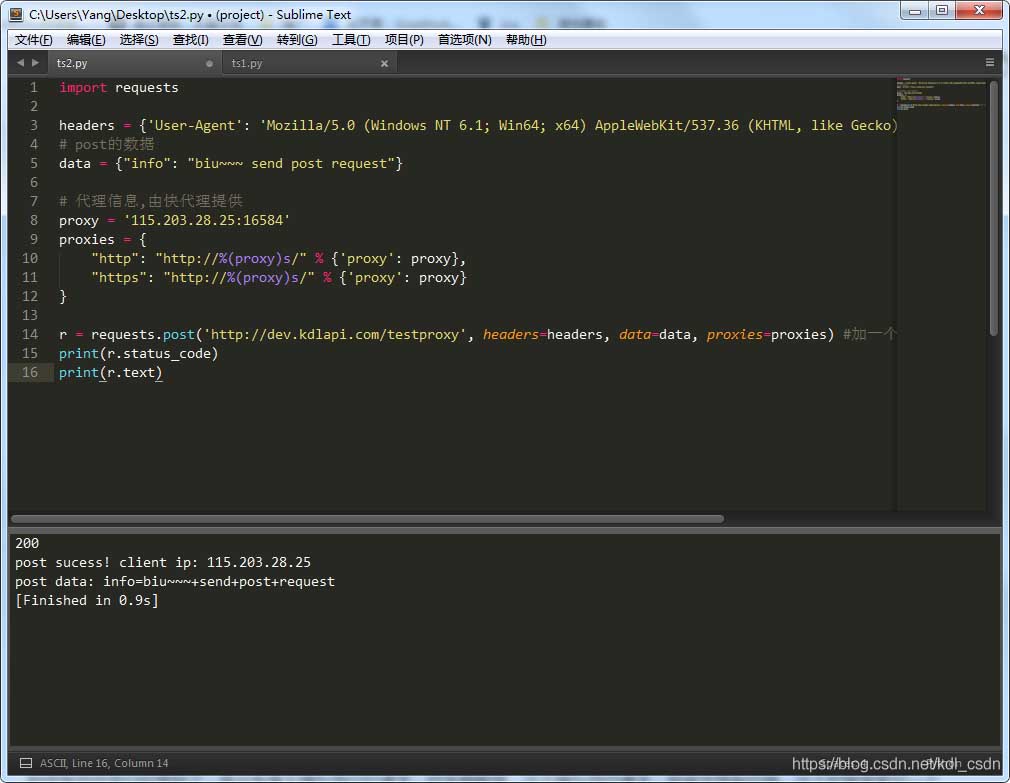
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'}
# post的数据
data = {"info": "biu~~~ send post request"}
# 代理信息,由快代理赞助
proxy = '115.203.28.25:16584'
proxies = {
"http": "http://%(proxy)s/" % {'proxy': proxy},
"https": "http://%(proxy)s/" % {'proxy': proxy}
}
r = requests.post('http://dev.kdlapi.com/testproxy', headers=headers, data=data, proxies=proxies) #加一个proxies参数
print(r.status_code)
print(r.text)
主要方法里加个proxies参数,这就用上代理IP了。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

python中requests库安装与使用详解
目录 前言 1.Requests介绍 2.requests库的安装 3.requests库常用的方法 4.response对象的常用属性 5.使用requests发送get请求 5.1 不带参数的get请求 5.2 带参数的get请求 5.2.1 查询参数params 5.2.2 SSL证书认证参数 verify 5.2.3 设置超时时间 timeout 5.2.4 代理IP参数 proxies 5.3 获取JSON数据 5.4 获取二进制数据 6.使用requests发送post请求 7.使
-
python 使用第三方库requests-toolbelt 上传文件流的示例
python 使用第三方库requests-toolbelt 上传文件流,内容如下所示: # pip install requests-toolbelt 使用第三方库上传文件流 from requests_toolbelt.multipart.encoder import MultipartEncoder 补充:Python使用requests和requests_toolbelt上传文件 一.文件上传(Form 表单方式)[先将文件读取至内存中,再将内存中的文件信息上传至服务器] 1.单文件上传
-
离线安装python的requests库方法
目录 前言 1.下载安装包 1.1 检查requests模块所需依赖包 1.2 下载requests所需依赖包 1.3 下载requests包 2.安装 2.1 安装requests所需依赖包 2.2 安装requests 3.检查是否安装成功 总结 前言 本文详细记录了在win7中离线安装python requests的过程,包括安装requests所需依赖包. 环境:win7.python3.8.9(win7中可安装的最新python版本).无法连接互联网 1.下载安装包 1.1 检查req
-
python爬虫之requests库的使用详解
目录 python爬虫-requests库的用法 基本的get请求 带参数的GET请求: 解析json 使用代理 获取cookie 会话维持 证书验证设置 超时异常捕获 异常处理 总结 python爬虫-requests库的用法 requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多,requests 允许你发送 HTTP/1.1 请求.指定 URL并添加查询url字符串即可开始爬取网页信息等操作 因为是第三方库,所以使用前需要cmd安装 pip install
-
Python Requests库知识汇总
目录 快速开始 发送请求 URL传参 响应内容 二进制响应内容 JSON响应内容 原始响应内容 自定义请求头 更复杂的POST请求More complicated POST requests 提交Multipart-Encoded文件 响应状态码 响应头 Cookies 重定向与history 请求超时 错误和异常 高级用法 Session对象 请求和响应对象 Prepared requests HTTP Basic 验证 SSL证书验证 客户端证书 CA证书 Body内容工作流 Keep-Al
-
Python爬虫之requests库基本介绍
目录 一.说明 二.基本用法: 总结 一.说明 requests是一个很实用的Python HTTP客户端库,爬虫和测试服务器响应数据时经常会用到,requests是Python语言的第三方的库,专门用于发送HTTP请求,使用起来比urllib简洁很多. Requests 有这些功能: 1.Keep-Alive & 连接池2.国际化域名和 URL3.带持久 Cookie 的会话4.浏览器式的 SSL 认证5.自动内容解码6.基本/摘要式的身份认证7.优雅的 key/value Cookie8.自
-
Python爬虫之urllib库详解
目录 一.说明: 二.urllib四个模块组成: 三.urllib.request 1.urlopen函数 2.response 响应类型 3.Request对象 4.高级请求方式 四.urllib.error 五.URL解析urllib.parse 六.urllib.robotparser 总结 一.说明: urllib库是python内置的一个http请求库,requests库就是基于该库开发出来的,虽然requests库使用更方便,但作为最最基本的请求库,了解一下原理和用法还是很有必要的.
-
Python爬虫解析网页的4种方式实例及原理解析
这篇文章主要介绍了Python爬虫解析网页的4种方式实例及原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 用Python写爬虫工具在现在是一种司空见惯的事情,每个人都希望能够写一段程序去互联网上扒一点资料下来,用于数据分析或者干点别的事情. 我们知道,爬虫的原理无非是把目标网址的内容下载下来存储到内存中,这个时候它的内容其实是一堆HTML,然后再对这些HTML内容进行解析,按照自己的想法提取出想要的数据,所以今天我们主要来讲四种在Py
-
Python爬虫简单运用爬取代理IP的实现
功能1: 爬取西拉ip代理官网上的代理ip 环境:python3.8+pycharm 库:requests,lxml 浏览器:谷歌 IP地址:http://www.xiladaili.com/gaoni/ 分析网页源码: 选中div元素后右键找到Copy再深入子菜单找到Copy Xpath点击一下就复制到XPath 我们复制下来的Xpth内容为:/html/body/div/div[3]/div[2]/table/tbody/tr[50]/td[1] 虽然可以查出来ip,但不利于程序自动爬取所有
-
python爬虫使用requests发送post请求示例详解
简介 HTTP协议规定post提交的数据必须放在消息主体中,但是协议并没有规定必须使用什么编码方式.服务端通过是根据请求头中的Content-Type字段来获知请求中的消息主体是用何种方式进行编码,再对消息主体进行解析.具体的编码方式包括: application/x-www-form-urlencoded 最常见post提交数据的方式,以form表单形式提交数据. application/json 以json串提交数据. multipart/form-data 一般使用来上传文件. 一. 以f
-
python爬虫用request库处理cookie的实例讲解
python爬虫中使用urli库可以使用opener"发送多个请求,这些请求是能共享处理cookie的,小编之前也提过python爬虫中使用request库会比urllib库更加⽅便,使用使用requests也能达到共享cookie的目的,即使用request库get方法和使用requests库提供的session对象都可以处理. 方法一:使用request库get方法 resp = requests.get('http://www.baidu.com/') print(resp.cookies
-
python爬虫之pyppeteer库简单使用
pyppeteer 介绍Pyppeteer之前先说一下Puppeteer,Puppeteer是谷歌出品的一款基于Node.js开发的一款工具,主要是用来操纵Chrome浏览器的 API,通过Javascript代码来操纵Chrome浏览器,完成数据爬取.Web程序自动测试等任务. pyppeteer 是非官方 Python 版本的 Puppeteer 库,浏览器自动化库,由日本工程师开发. Puppeteer 是 Google 基于 Node.js 开发的工具,调用 Chrome 的 API,通
-
关于python爬虫应用urllib库作用分析
目录 一.urllib库是什么? 二.urllib库的使用 urllib.request模块 urllib.parse模块 利用try-except,进行超时处理 status状态码 && getheaders() 突破反爬 一.urllib库是什么? urllib库用于操作网页 URL,并对网页的内容进行抓取处理 urllib包 包含以下几个模块: urllib.request - 打开和读取 URL. urllib.error - 包含 urllib.request 抛出的异常. ur
-
Python爬虫之Selenium库的使用方法
Selenium 是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等.这个工具的主要功能包括:测试与浏览器的兼容性--测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上.测试系统功能--创建回归测试检验软件功能和用户需求.支持自动录制动作和自动生成 .Net.Java.Perl等不同语言的测试