mysql "group by"与"order by"的研究--分类中最新的内容
这两天让一个数据查询难了。主要是对group by 理解的不够深入。才出现这样的情况
这种需求,我想很多人都遇到过。下面是我模拟我的内容表
代码如下:
CREATE TABLE `test` (
`id` INT(10) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(255) NOT NULL,
`category_id` INT(10) NOT NULL,
`date` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
)
ENGINE=MyISAM
ROW_FORMAT=DEFAULT;
INSERT INTO `test` (`id`, `name`, `category_id`, `date`)
VALUES
(1, 'aaa', 1, '2010-06-10 19:14:37'),
(2, 'bbb', 2, '2010-06-10 19:14:55'),
(3, 'ccc', 1, '2010-06-10 19:16:02'),
(4, 'ddd', 1, '2010-06-10 19:16:15'),
(5, 'eee', 2, '2010-06-10 19:16:35');
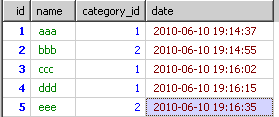
我现在需要取出每个分类中最新的内容
select * from test group by category_id order by `date`
结果如下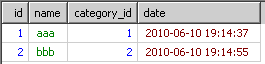
明显。这不是我想要的数据,原因是msyql已经的执行顺序是
引用
写的顺序:select ... from... where.... group by... having... order by..
执行顺序:from... where...group by... having.... select ... order by...
所以在order by拿到的结果里已经是分组的完的最后结果。
由from到where的结果如下的内容。
到group by时就得到了根据category_id分出来的多个小组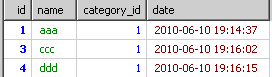
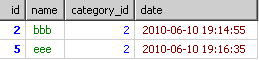
到了select的时候,只从上面的每个组里取第一条信息结果会如下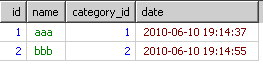
即使order by也只是从上面的结果里进行排序。并不是每个分类的最新信息。
回到我的目的上 --分类中最新的信息
根据上面的分析,group by到select时只取到分组里的第一条信息。有两个解决方法
1,where+group by(对小组进行排序)
2,从form返回的数据下手脚(即用子查询)
由where+group by的解决方法
对group by里的小组进行排序的函数我只查到group_concat()可以进行排序,但group_concat的作用是将小组里的字段里的值进行串联起来。
select group_concat(id order by `date` desc) from `test` group by category_id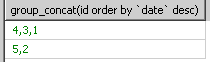
再改进一下
select * from `test` where id in(select SUBSTRING_INDEX(group_concat(id order by `date` desc),',',1) from `test` group by category_id ) order by `date` desc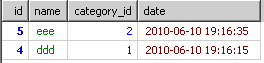
子查询解决方案
select * from (select * from `test` order by `date` desc) `temp` group by category_id order by `date` desc
相关推荐
-
使用mysql的disctinct group by查询不重复记录
有个需求,一直没有解决,在google上找了半天,给出的方案没有一个能用了,最后鬼使神差搞定了. 是这样的,假设一个表: id f_id value 1 2 a 2 2 b 3 5 c 4 9 c 5 9 a 6 6 d id f_id value 1 2 a 2
-
解析mysql中:单表distinct、多表group by查询去除重复记录
单表的唯一查询用:distinct多表的唯一查询用:group bydistinct 查询多表时,left join 还有效,全连接无效,在使用mysql时,有时需要查询出某个字段不重复的记录,虽然mysql提供有distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的条数,而不是用它来返回不重复记录的所有值.其原因是distinct只能返回它的目标字段,而无法返回其它字段,用distinct不能解决的话,我只有用二重循环查询来解决,而这样对于一个数据量非常大的
-

mysql筛选GROUP BY多个字段组合时的用法分享
想实现这样一种效果如果使用group by一个条件的话,得到的结果会少了很多,如何多个条件组合筛选呢 复制代码 代码如下: group by fielda,fieldb,fieldc... 循环的时候可以通过判断后一个跟前面一个是否相同来分组,一个示例 复制代码 代码如下: $result = mysql_query("SELECT groups,name,goods FROM table GROUP BY groups,name ORDER BY name"); $arr = arr
-
MySQL5.7 group by新特性报错1055的解决办法
项目中本来使用的是mysql5.6进行开发,切换到5.7之后,突然发现原来的一些sql运行都报错,错误编码1055,错误信息和sql_mode中的"only_full_group_by"有关,到网上看了原因,说是mysql5.7中only_full_group_by这个模式是默认开启的 解决办法大致有两种: 一:在sql查询语句中不需要group by的字段上使用any_value()函数 当然,这种对于已经开发了不少功能的项目不太合适,毕竟要把原来的sql都给修改一遍 二:修改my.
-
MySql版本问题sql_mode=only_full_group_by的完美解决方案
1.查看sql_mode select @@sql_mode 查询出来的值为: ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION 2.去掉ONLY_FULL_GROUP_BY,重新设置值. set @@sql_mode ='STRICT_TRANS_TABLES,NO_ZE
-
mysql使用GROUP BY分组实现取前N条记录的方法
本文实例讲述了mysql使用GROUP BY分组实现取前N条记录的方法.分享给大家供大家参考,具体如下: MySQL中GROUP BY分组取前N条记录实现 mysql分组,取记录 GROUP BY之后如何取每组的前两位下面我来讲述mysql中GROUP BY分组取前N条记录实现方法. 这是测试表(也不知道怎么想的,当时表名直接敲了个aa,汗~~~~): 结果: 方法一: 复制代码 代码如下: SELECT a.id,a.SName,a.ClsNo,a.Score FROM aa a LEFT J
-
MySql Group By对多个字段进行分组的实现方法
在平时的开发任务中我们经常会用到MYSQL的GROUP BY分组, 用来获取数据表中以分组字段为依据的统计数据.比如有一个学生选课表,表结构如下: Table: Subject_Selection Subject Semester Attendee --------------------------------- ITB001 1 John ITB001 1 Bob ITB001 1 Mickey ITB001 2 Jenny ITB001 2 James MKB114 1 John MKB1
-
MySQL分组查询Group By实现原理详解
由于GROUP BY 实际上也同样会进行排序操作,而且与ORDER BY 相比,GROUP BY 主要只是多了排序之后的分组操作.当然,如果在分组的时候还使用了其他的一些聚合函数,那么还需要一些聚合函数的计算.所以,在GROUP BY 的实现过程中,与 ORDER BY 一样也可以利用到索引. 在MySQL 中,GROUP BY 的实现同样有多种(三种)方式,其中有两种方式会利用现有的索引信息来完成 GROUP BY,另外一种为完全无法使用索引的场景下使用.下面我们分别针对这三种实现方式做一个分
-
Mysql中错误使用SQL语句Groupby被兼容的情况
首先创建数据库hncu,建立stud表格. 添加数据: create table stud( sno varchar(30) not null primary key, sname varchar(30) not null, age int, saddress varchar(30) ); INSERT INTO stud VALUES('1001','Tom',22,'湖南益阳'); INSERT INTO stud VALUES('1002','Jack',23,'益阳'); INSERT
-
关于MYSQL中每个用户取1条记录的三种写法(group by xxx)
今天以前的同学问我关于这方面的SQL语句,我特意记忆一下,毕竟这个也比较常见了 复制代码 代码如下: select * from (select * from member_payment order by id desc) t group by member_id limit 10 第一种是先排序,然后group,这样的话自然可以取到最适合的一条数据.缺点很明显:Using temporary; Using filesort 复制代码 代码如下: select
-
mysql分组取每组前几条记录(排名) 附group by与order by的研究
--按某一字段分组取最大(小)值所在行的数据 复制代码 代码如下: /* 数据如下: name val memo a 2 a2(a的第二个值) a 1 a1--a的第一个值 a 3 a3:a的第三个值 b 1 b1--b的第一个值 b 3 b3:b的第三个值 b 2 b2b2b2b2 b 4 b4b4 b 5 b5b5b5b5b5 */ --创建表并插入数据: 复制代码 代码如下: create table tb(name varchar(10),val int,memo varchar(20)
-
MySQL中distinct与group by语句的一些比较及用法讲解
在数据表中记录了用户验证时使用的书目,现在想取出所有书目,用DISTINCT和group by都取到了我想要的结果,但我发现返回结果排列不同,distinct会按数据存放顺序一条条显示,而group by会做个排序(一般是ASC). DISTINCT 实际上和 GROUP BY 操作的实现非常相似,只不过是在 GROUP BY 之后的每组中只取出一条记录而已.所以,DISTINCT 的实现和 GROUP BY 的实现也基本差不多,没有太大的区别,同样可以通过松散索引扫描或者是