python django使用haystack:全文检索的框架(实例讲解)
haystack:全文检索的框架
whoosh:纯Python编写的全文搜索引擎
jieba:一款免费的中文分词包
首先安装这三个包
pip install django-haystack
pip install whoosh
pip install jieba
1.修改settings.py文件,安装应用haystack,
2.在settings.py文件中配置搜索引擎
HAYSTACK_CONNECTIONS = {
'default': {
# 使用whoosh引擎
'ENGINE': 'haystack.backends.whoosh_cn_backend.WhooshEngine',
# 索引文件路径
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
}
}
# 当添加、修改、删除数据时,自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
3. 在templates目录下创建“search/indexes/blog/”目录 采用blog应用名字下面创建一个文件blog_text.txt
#指定索引的属性
{{ object.title }}
{{ object.text}}
{{ object.keywords }}
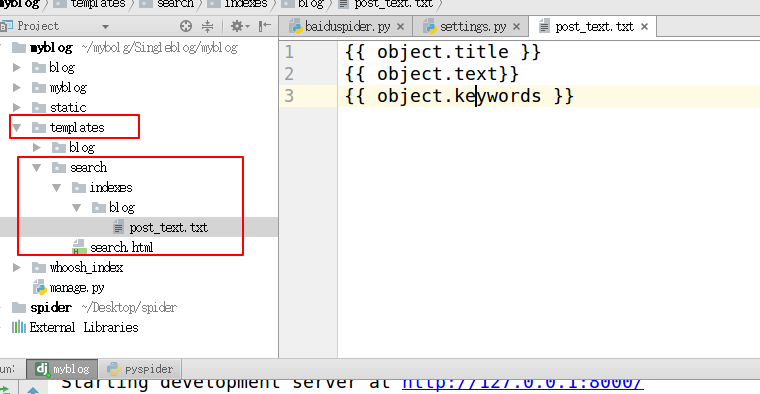
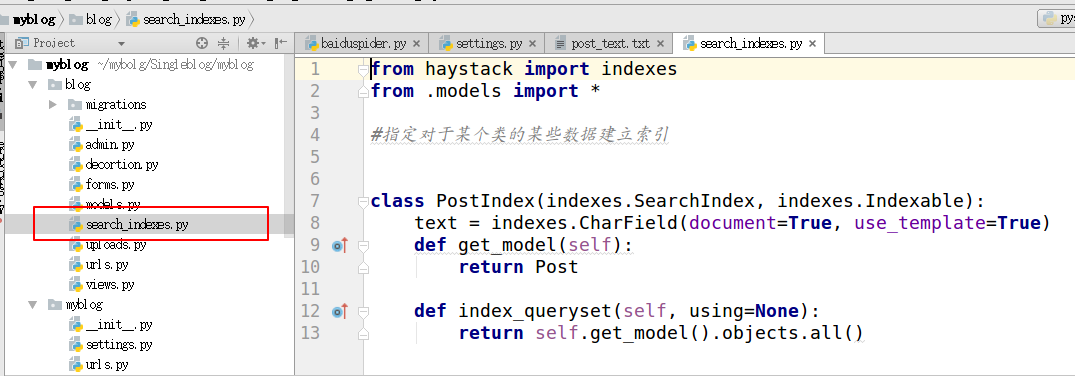
4.在需要搜索的应用下面创建search_indexes
from haystack import indexes from models import Post #指定对于某个类的某些数据建立索引 class GoodsInfoIndex(indexes.SearchIndex, indexes.Indexable): text = indexes.CharField(document=True, use_template=True) def get_model(self): return Post #搜索的模型类 def index_queryset(self, using=None): return self.get_model().objects.all()
5.
1. 修改haystack文件
2. 找到虚拟环境py_django下的haystack目录 这个目录根据自己使用的python环境不同,路径也不一样。
3. site-packages/haystack/backends/ 创建一个文件名为ChineseAnalyzer.py文件写入下面代码,用于中文分词
import jieba
from whoosh.analysis import Tokenizer, Token
class ChineseTokenizer(Tokenizer):
def __call__(self, value, positions=False, chars=False,
keeporiginal=False, removestops=True,
start_pos=0, start_char=0, mode='', **kwargs):
t = Token(positions, chars, removestops=removestops, mode=mode,
**kwargs)
seglist = jieba.cut(value, cut_all=True)
for w in seglist:
t.original = t.text = w
t.boost = 1.0
if positions:
t.pos = start_pos + value.find(w)
if chars:
t.startchar = start_char + value.find(w)
t.endchar = start_char + value.find(w) + len(w)
yield t
def ChineseAnalyzer():
return ChineseTokenizer()
6.
1. 复制whoosh_backend.py文件,改为如下名称
whoosh_cn_backend.py
在复制出来的文件中导入中文分词模块
from .ChineseAnalyzer import ChineseAnalyzer
2. 更改词语分析类 改成中文
查找analyzer=StemmingAnalyzer()改为analyzer=ChineseAnalyzer()
7. 最后一步就是建初始化索引数据
python manage.py rebuild_index
8. 创建搜索模板 在templates/indexes/ 创建search.html模板
搜索结果进行分页,视图向模板中传递的上下文如下
query:搜索关键字
page:当前页的page对象
paginator:分页paginator对象
9. 在自己的应用视图中导入模块
from haystack.generic_views import SearchView
定义一个类重写get_context_data 方法,这样就可以往模板中传递自定义的上下文。
class GoodsSearchView(SearchView): def get_context_data(self, *args, **kwargs): context = super().get_context_data(*args, **kwargs) context['iscart']=1 context['qwjs']=2 return context
应用的urls文件中添加这条url 将类当一个视图的方法使用 .as_view()
url('^search/$', views.BlogSearchView.as_view())
以上这篇python django使用haystack:全文检索的框架(实例讲解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python中使用haystack实现django全文检索搜索引擎功能
前言 django是python语言的一个web框架,功能强大.配合一些插件可为web网站很方便地添加搜索功能. 搜索引擎使用whoosh,是一个纯python实现的全文搜索引擎,小巧简单. 中文搜索需要进行中文分词,使用jieba. 直接在django项目中使用whoosh需要关注一些基础细节问题,而通过haystack这一搜索框架,可以方便地在django中直接添加搜索功能,无需关注索引建立.搜索解析等细节问题. haystack支持多种搜索引擎,不仅仅是whoosh,使用solr.elas
-

分析Python的Django框架的运行方式及处理流程
之前在网上看过一些介绍Django处理请求的流程和Django源码结构的文章,觉得了解一下这些内容对开发Django项目还是很有帮助的.所以,我按照自己的逻辑总结了一下Django项目的运行方式和对Request的基本处理流程. 一.Django的运行方式 运行Django项目的方法很多,这里主要介绍一下常用的方法.一种是在开发和调试中经常用到runserver方法,使用Django自己的web server:另外一种就是使用fastcgi,uWSGIt等协议运行Django项目,这里以uWSG
-
Python的Django框架使用入门指引
前言 传统 Web 开发方式常常需要编写繁琐乏味的重复性代码,不仅页面表现与逻辑实现的代码混杂在一起,而且代码编写效率不高.对于开发者来说,选择一个功能强大并且操作简洁的开发框架来辅助完成繁杂的编码工作,将会对开发效率的提升起到很大帮助.幸运的是,这样的开发框架并不少见,需要做的仅是从中选出恰恰为开发者量身打造的那款Web框架. 自从基于 MVC 分层结构的 Web 设计理念普及以来,选择适合的开发框架无疑是项目成功的关键性因素.无论是 Struts.Spring 或是其他 Web 框架的出现
-
python django使用haystack:全文检索的框架(实例讲解)
haystack:全文检索的框架 whoosh:纯Python编写的全文搜索引擎 jieba:一款免费的中文分词包 首先安装这三个包 pip install django-haystack pip install whoosh pip install jieba 1.修改settings.py文件,安装应用haystack, 2.在settings.py文件中配置搜索引擎 HAYSTACK_CONNECTIONS = { 'default': { # 使用whoosh引擎 'ENGINE': '
-
Python django中如何使用restful框架
在使用django进行前后台分离开发时通常会搭配django-rest-framework框架创建RESTful风格的接口API.框架介绍及版本要求可参考官方地址:https://www.django-rest-framework.org 本文以创建man包含name.sex字段的API为实例学习django-rest-framework框架的使用. 主要包含下面5个步骤: 1.创建Django项目 2.创建ORM模型 3.加载Django REST Framework 4.序列化模型 5.创建
-
对python使用http、https代理的实例讲解
在国内利用Python从Internet上爬取数据时,有些网站或API接口被限速或屏蔽,这时使用代理可以加速爬取过程,减少请求失败,Python程序使用代理的方法主要有以下几种: (1)如果是在代码中使用一些网络库或爬虫框架进行数据爬取,一般这种框架都会支持设置代理,例如: <span style="font-size:14px;">import urllib.request as urlreq # 设置https代理 ph = urlreq.ProxyHandler({'
-
python中用Scrapy实现定时爬虫的实例讲解
一般网站发布信息会在具体实现范围内发布,我们在进行网络爬虫的过程中,可以通过设置定时爬虫,定时的爬取网站的内容.使用python爬虫框架Scrapy框架可以实现定时爬虫,而且可以根据我们的时间需求,方便的修改定时的时间. 1.Scrapy介绍 Scrapy是python的爬虫框架,用于抓取web站点并从页面中提取结构化的数据.任何人都可以根据需求方便的修改.Scrapy用途广泛,可以用于数据挖掘.监测和自动化测试. 2.使用Scrapy框架定时爬取 import time from scrapy
-
打造通用的匀速运动框架(实例讲解)
本文,是接着上 基于匀速运动的实例讲解(侧边栏,淡入淡出) 继续的,在这篇文章的最后,我们做了2个小实例:侧边栏与改变透明度的淡入淡出效果,本文我们把上文的animate函数,继续改造,让他变得更加的通用和强大: 1,支持多个物体的运动 2,同时运动 3,顺序运动 这三种运动方式也是jquery中animate函数支持的 一.animate函数中怎么区分变化不同的样式? 上文中,侧边栏效果 用的animate函数 改变的是left值 function animate(obj, target, s
-
python递归打印某个目录的内容(实例讲解)
以下函数列出某个目录下(包括子目录)所有文件,本随笔重点不在于递归函数的实现,这是一个很简单的递归,重点在于熟悉Python 库os以及os.path一些函数的功能和用法. 1. os.listdir(path): 列出path下所有内容(包括文件和目录,不包括.和..) 2. os.path.join(path1,path2,path3...): 拼接目录,例如将'home','test'拼接成'home/test/' 3. os.path.isdir(path): 判断path是否为目录 代
-
Python字典实现简单的三级菜单(实例讲解)
如下所示: data = { "北京":{ "昌平":{"沙河":["oldboy","test"],"天通苑":["链接地产","我爱我家"]}, "朝阳":{"望京":["奔驰","陌陌"],"国贸":["CICC",&quo
-
Python之自动获取公网IP的实例讲解
0.预备知识 0.1 SQL基础 ubuntu.Debian系列安装: root@raspberrypi:~/python-script# apt-get install mysql-server Redhat.Centos 系列安装: [root@localhost ~]# yum install mysql-server 登录数据库 pi@raspberrypi:~ $ mysql -uroot -p -hlocalhost Enter password: Welcome to the Ma
-
python 3.6 +pyMysql 操作mysql数据库(实例讲解)
版本信息:python:3.6 mysql:5.7 pyMysql:0.7.11 ################################################################# #author: 陈月白 #_blogs: http://www.cnblogs.com/chenyuebai/ ################################################################# # -*- coding: utf-8
-
python中判断文件编码的chardet(实例讲解)
1.实测,这个版本在32位window7和python3.2环境下正常使用. 2.使用方法:把解压后所得的chardet和docs两个文件夹拷贝到python3.2目录下的Lib\site-packages目录下就可以正常使用了. 3.判断文件编码的参考代码如下: file = open(fileName, "rb")#要有"rb",如果没有这个的话,默认使用gbk读文件. buf = file.read() result = chardet.detect(buf)