Python实现k-means算法
本文实例为大家分享了Python实现k-means算法的具体代码,供大家参考,具体内容如下
这也是周志华《机器学习》的习题9.4。
数据集是西瓜数据集4.0,如下
编号,密度,含糖率
1,0.697,0.46
2,0.774,0.376
3,0.634,0.264
4,0.608,0.318
5,0.556,0.215
6,0.403,0.237
7,0.481,0.149
8,0.437,0.211
9,0.666,0.091
10,0.243,0.267
11,0.245,0.057
12,0.343,0.099
13,0.639,0.161
14,0.657,0.198
15,0.36,0.37
16,0.593,0.042
17,0.719,0.103
18,0.359,0.188
19,0.339,0.241
20,0.282,0.257
21,0.784,0.232
22,0.714,0.346
23,0.483,0.312
24,0.478,0.437
25,0.525,0.369
26,0.751,0.489
27,0.532,0.472
28,0.473,0.376
29,0.725,0.445
30,0.446,0.459
算法很简单,就不解释了,代码也不复杂,直接放上来:
# -*- coding: utf-8 -*-
"""Excercise 9.4"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sys
import random
data = pd.read_csv(filepath_or_buffer = '../dataset/watermelon4.0.csv', sep = ',')[["密度","含糖率"]].values
########################################## K-means #######################################
k = int(sys.argv[1])
#Randomly choose k samples from data as mean vectors
mean_vectors = random.sample(data,k)
def dist(p1,p2):
return np.sqrt(sum((p1-p2)*(p1-p2)))
while True:
print mean_vectors
clusters = map ((lambda x:[x]), mean_vectors)
for sample in data:
distances = map((lambda m: dist(sample,m)), mean_vectors)
min_index = distances.index(min(distances))
clusters[min_index].append(sample)
new_mean_vectors = []
for c,v in zip(clusters,mean_vectors):
new_mean_vector = sum(c)/len(c)
#If the difference betweenthe new mean vector and the old mean vector is less than 0.0001
#then do not updata the mean vector
if all(np.divide((new_mean_vector-v),v) < np.array([0.0001,0.0001]) ):
new_mean_vectors.append(v)
else:
new_mean_vectors.append(new_mean_vector)
if np.array_equal(mean_vectors,new_mean_vectors):
break
else:
mean_vectors = new_mean_vectors
#Show the clustering result
total_colors = ['r','y','g','b','c','m','k']
colors = random.sample(total_colors,k)
for cluster,color in zip(clusters,colors):
density = map(lambda arr:arr[0],cluster)
sugar_content = map(lambda arr:arr[1],cluster)
plt.scatter(density,sugar_content,c = color)
plt.show()
运行方式:在命令行输入 python k_means.py 4。其中4就是k。
下面是k分别等于3,4,5的运行结果,因为一开始的均值向量是随机的,所以每次运行结果会有不同。
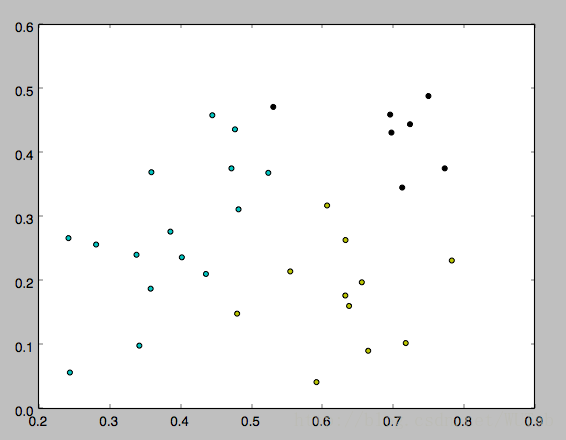
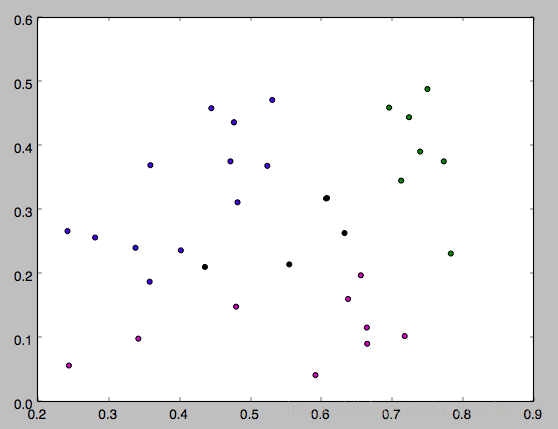
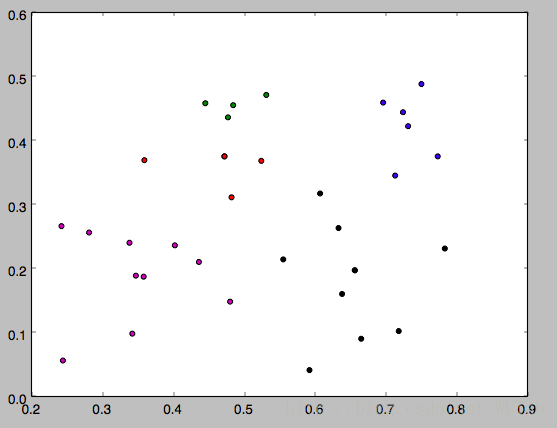
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- python kmeans聚类简单介绍和实现代码
- Python机器学习算法之k均值聚类(k-means)
- python中kmeans聚类实现代码
- python实现k-means聚类算法
- Python机器学习之K-Means聚类实现详解
- Python实现Kmeans聚类算法
- python实现kMeans算法
- 详解K-means算法在Python中的实现
- python中学习K-Means和图片压缩
- Python KMeans聚类问题分析
相关推荐
-

python中学习K-Means和图片压缩
大家在学习python中,经常会使用到K-Means和图片压缩的,我们在此给大家分享一下K-Means和图片压缩的方法和原理,喜欢的朋友收藏一下吧. 通俗的介绍这种压缩方式,就是将原来很多的颜色用少量的颜色去表示,这样就可以减小图片大小了.下面首先我先介绍下K-Means,当你了解了K-Means那么你也很容易的可以去理解图片压缩了,最后附上图片压缩的核心代码. K-Means的核心思想 k-means的核心算法也就上面寥寥几句,下面将分三个部分来讲解:初始化簇中心.簇分配.簇中心移动. 初始化
-
python实现kMeans算法
聚类是一种无监督的学习,将相似的对象放到同一簇中,有点像是全自动分类,簇内的对象越相似,簇间的对象差别越大,则聚类效果越好. 1.k均值聚类算法 k均值聚类将数据分为k个簇,每个簇通过其质心,即簇中所有点的中心来描述.首先随机确定k个初始点作为质心,然后将数据集分配到距离最近的簇中.然后将每个簇的质心更新为所有数据集的平均值.然后再进行第二次划分数据集,直到聚类结果不再变化为止. 伪代码为 随机创建k个簇质心 当任意一个点的簇分配发生改变时: 对数据集中的每个数据点: 对
-
详解K-means算法在Python中的实现
K-means算法简介 K-means是机器学习中一个比较常用的算法,属于无监督学习算法,其常被用于数据的聚类,只需为它指定簇的数量即可自动将数据聚合到多类中,相同簇中的数据相似度较高,不同簇中数据相似度较低. K-MEANS算法是输入聚类个数k,以及包含 n个数据对象的数据库,输出满足方差最小标准k个聚类的一种算法.k-means 算法接受输入量 k :然后将n个数据对象划分为 k个聚类以便使得所获得的聚类满足:同一聚类中的对象相似度较高:而不同聚类中的对象相似度较小. 核心思想 通过迭代寻找
-
Python机器学习之K-Means聚类实现详解
本文为大家分享了Python机器学习之K-Means聚类的实现代码,供大家参考,具体内容如下 1.K-Means聚类原理 K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大.其基本思想是:以空间中k个点为中心进行聚类,对最靠近他们的对象归类.通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果.各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开. 算法大致流程为:(1)随机选取k个点作为种子点(这k个点不一定属于数据集)
-
Python实现Kmeans聚类算法
本节内容:本节内容是根据上学期所上的模式识别课程的作业整理而来,第一道题目是Kmeans聚类算法,数据集是Iris(鸢尾花的数据集),分类数k是3,数据维数是4. 关于聚类 聚类算法是这样的一种算法:给定样本数据Sample,要求将样本Sample中相似的数据聚到一类.有了这个认识之后,就应该了解了聚类算法要干什么了吧.说白了,就是归类. 首先,我们需要考虑的是,如何衡量数据之间的相似程度?比如说,有一群说不同语言的人,我们一般是根据他们的方言来聚类的(当然,你也可以指定以身高来聚类).
-
python中kmeans聚类实现代码
k-means算法思想较简单,说的通俗易懂点就是物以类聚,花了一点时间在python中实现k-means算法,k-means算法有本身的缺点,比如说k初始位置的选择,针对这个有不少人提出k-means++算法进行改进:另外一种是要对k大小的选择也没有很完善的理论,针对这个比较经典的理论是轮廓系数,二分聚类的算法确定k的大小,在最后还写了二分聚类算法的实现,代码主要参考机器学习实战那本书: #encoding:utf-8 ''''' Created on 2015年9月21日 @author: Z
-
python实现k-means聚类算法
k-means聚类算法 k-means是发现给定数据集的k个簇的算法,也就是将数据集聚合为k类的算法. 算法过程如下: 1)从N个文档随机选取K个文档作为质心 2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类,我们一般取欧几里得距离 3)重新计算已经得到的各个类的质心 4)迭代步骤(2).(3)直至新的质心与原质心相等或迭代次数大于指定阈值,算法结束 算法实现 随机初始化k个质心,用dict保存质心的值以及被聚类到该簇中的所有data. def initCent(dataSe
-
Python KMeans聚类问题分析
今天用python实现了一下简单的聚类分析,顺便熟悉了numpy数组操作和绘图的一些技巧,在这里做个记录. from pylab import * from sklearn.cluster import KMeans ## 利用numpy.append()函数实现matlab多维数组合并的效果,axis 参数值为 0 时是 y 轴方向合并,参数值为 1 时是 x 轴方向合并,分别对应matlab [A ; B] 和 [A , B]的效果 #创建5个随机的数据集 x1=append(randn(5
-
Python机器学习算法之k均值聚类(k-means)
一开始的目的是学习十大挖掘算法(机器学习算法),并用编码实现一遍,但越往后学习,越往后实现编码,越发现自己的编码水平低下,学习能力低.这一个k-means算法用Python实现竟用了三天时间,可见编码水平之低,而且在编码的过程中看了别人的编码,才发现自己对numpy认识和运用的不足,在自己的代码中有很多可以优化的地方,比如求均值的地方可以用mean直接对数组求均值,再比如去最小值的下标,我用的是argsort排序再取列表第一个,但是有argmin可以直接用啊.下面的代码中这些可以优化的并没有改,
-
python kmeans聚类简单介绍和实现代码
一.k均值聚类的简单介绍 假设样本分为c类,每个类均存在一个中心点,通过随机生成c个中心点进行迭代,计算每个样本点到类中心的距离(可以自定义.常用的是欧式距离) 将该样本点归入到最短距离所在的类,重新计算聚类中心,进行下次的重新划分样本,最终类中心不改变时,聚类完成 二.伪代码 三.python代码实现 #!/usr/bin/env python # coding=utf-8 import numpy as np import random import matplotlib.pyplo