TensorFlow平台下Python实现神经网络
本篇文章主要通过一个简单的例子来实现神经网络。训练数据是随机产生的模拟数据集,解决二分类问题。
下面我们首先说一下,训练神经网络的一般过程:
1.定义神经网络的结构和前向传播的输出结果
2.定义损失函数以及反向传播优化的算法
3.生成会话(Session)并且在训练数据上反复运行反向传播优化算法
要记住的一点是,无论神经网络的结构如何变化,以上三个步骤是不会改变的。
完整代码如下:
import tensorflow as tf
#导入TensorFlow工具包并简称为tf
from numpy.random import RandomState
#导入numpy工具包,生成模拟数据集
batch_size = 8
#定义训练数据batch的大小
w1 = tf.Variable(tf.random_normal([2,3],stddev=1,seed=1))
w2 = tf.Variable(tf.random_normal([3,1],stddev=1,seed=1))
#分别定义一二层和二三层之间的网络参数,标准差为1,随机产生的数保持一致
x = tf.placeholder(tf.float32,shape=(None,2),name='x-input')
y_ = tf.placeholder(tf.float32,shape=(None,1),name='y-input')
#输入为两个维度,即两个特征,输出为一个标签,声明数据类型float32,None即一个batch大小
#y_是真实的标签
a = tf.matmul(x,w1)
y = tf.matmul(a,w2)
#定义神经网络前向传播过程
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y,1e-10,1.0)))
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
#定义损失函数和反向传播算法
rdm = RandomState(1)
dataset_size = 128
#产生128组数据
X = rdm.rand(dataset_size,2)
Y = [[int(x1+x2 < 1)] for (x1,x2) in X]
#将所有x1+x2<1的样本视为正样本,表示为1;其余为0
#创建会话来运行TensorFlow程序
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
#初始化变量
sess.run(init_op)
print(sess.run(w1))
print(sess.run(w2))
#打印出训练网络之前网络参数的值
STEPS = 5000
#设置训练的轮数
for i in range(STEPS):
start = (i * batch_size) % dataset_size
end = min(start+batch_size,dataset_size)
#每次选取batch_size个样本进行训练
sess.run(train_step,feed_dict={x:X[start:end],y_:Y[start:end]})
#通过选取的样本训练神经网络并更新参数
if i%1000 == 0:
total_cross_entropy = sess.run(cross_entropy,feed_dict={x:X,y_:Y})
print("After %d training step(s),cross entropy on all data is %g" % (i,total_cross_entropy))
#每隔一段时间计算在所有数据上的交叉熵并输出,随着训练的进行,交叉熵逐渐变小
print(sess.run(w1))
print(sess.run(w2))
#打印出训练之后神经网络参数的值
运行结果如下:
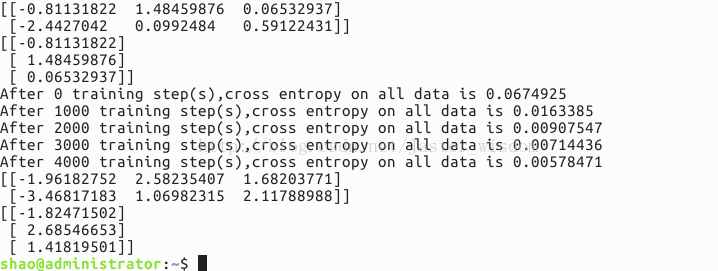
结果说明:
首先是打印出训练之前的网络参数,也就是随机产生的参数值,然后将训练过程中每隔1000次的交叉熵输出,发现交叉熵在逐渐减小,说明分类的性能在变好。最后是训练网络结束后网络的参数。
分享一个图形化神经网络训练过程的网站:点这里,可以自己定义网络参数的大小,层数以及学习速率的大小,并且训练过程会以很直观的形式展示出来。比如:


以上对于神经网络训练过程可以有一个很深刻的理解。
最后,再补充一些TensorFlow相关的知识:
1.TensorFlow计算模型-计算图
Tensor表示张量,可以简单的理解为多维数据结构;Flow则体现了它的计算模型。Flow翻译过来是“流”,它直观地表达了张量之间通过计算相互转换的过程。TensorFlow中的每一个计算都是计算图上的一个节点,而节点之间的边描述了计算之间的依赖关系。
指定GPU方法,命令如下:
import tensorflow as tf a = tf.constant([1.0,2.0],name=“a”) b = tf.constant([3.0,4.0],name=“b”) g = tf.Graph() with g.device(/gpu:0): result = a + b sess = tf.Session() sess.run(result)
2.TensorFlow数据模型-张量
张量是管理数据的形式。零阶张量表示标量,第一阶张量为向量,也就是一维数组,一般来说,第n阶张量可以理解为一个n维数组。张量本身不存储运算的结果,它只是得到对结果的一个引用。可以使用tf.Session().run(result)语句来得到计算结果。
3.TensorFlow运行模型-会话
我们使用session来执行定义好的运算。
主要有以下两种方式,第一种会产生内存泄漏,第二种不会有这种问题。
#创建一个会话 sess = tf.Session() sess.run(…) #关闭会话使得本次运行中使用的资源得到释放 sess.close()
第二种方式是通过Python的上下文资源管理器来使用会话。
with tf.Session() as sess: sess.run(…)
此种方式自动关闭和自动进行资源的释放
4.TensorFlow-神经网络例子
使用神经网络解决分类问题可以分为以下四个步骤:
①提取问题中实体的特征向量作为输入。
②定义神经网络的结构,并定义如何从神经网络的输入得到输出。这个过程就是神经网络的前向传播算法。
③通过训练数据来调整神经网络中参数的设置,这就是训练网络的过程。
④使用训练好的神经网络来预测未知的数据
在TensorFlow中声明一个2*3的矩阵变量的方法:
weight = tf.Variable(tf.random_normal([2,3],stddev=2))
即表示为方差为0、标准差为2的正态分布
在TensorFlow中,一个变量的值在被使用之前,这个变量的初始化过程需要被明确调用。一下子初始化所有的变量
sess = tf.Session()
init_op = tf.initialize_all_variables()
或者换成init_op = tf.global_variables_initializer()也可
sess.run(init_op)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- python构建深度神经网络(续)
- python构建深度神经网络(DNN)
- python实现简单神经网络算法
- Python实现的三层BP神经网络算法示例
- Python实现的径向基(RBF)神经网络示例
- Python编程实现的简单神经网络算法示例
- python实现神经网络感知器算法
- python机器学习之神经网络(三)
- python机器学习之神经网络(一)
- Python实现感知器模型、两层神经网络
相关推荐
-

Python编程实现的简单神经网络算法示例
本文实例讲述了Python编程实现的简单神经网络算法.分享给大家供大家参考,具体如下: python实现二层神经网络 包括输入层和输出层 # -*- coding:utf-8 -*- #! python2 import numpy as np #sigmoid function def nonlin(x, deriv = False): if(deriv == True): return x*(1-x) return 1/(1+np.exp(-x)) #input dataset x = np.
-
python机器学习之神经网络(一)
python有专门的神经网络库,但为了加深印象,我自己在numpy库的基础上,自己编写了一个简单的神经网络程序,是基于Rosenblatt感知器的,这个感知器建立在一个线性神经元之上,神经元模型的求和节点计算作用于突触输入的线性组合,同时结合外部作用的偏置,对若干个突触的输入求和后进行调节.为了便于观察,这里的数据采用二维数据. 目标函数是训练结果的误差的平方和,由于目标函数是一个二次函数,只存在一个全局极小值,所以采用梯度下降法的策略寻找目标函数的最小值. 代码如下: import numpy
-
python实现简单神经网络算法
python实现简单神经网络算法,供大家参考,具体内容如下 python实现二层神经网络 包括输入层和输出层 import numpy as np #sigmoid function def nonlin(x, deriv = False): if(deriv == True): return x*(1-x) return 1/(1+np.exp(-x)) #input dataset x = np.array([[0,0,1], [0,1,1], [1,0,1], [1,1,1]]) #out
-
python机器学习之神经网络(三)
前面两篇文章都是参考书本神经网络的原理,一步步写的代码,这篇博文里主要学习了如何使用neurolab库中的函数来实现神经网络的算法. 首先介绍一下neurolab库的配置: 选择你所需要的版本进行下载,下载完成后解压. neurolab需要采用python安装第三方软件包的方式进行安装,这里介绍一种安装方式: (1)进入cmd窗口 (2)进入解压文件所在目录下 (3)输入 setup.py install 这样,在python安装目录的Python27\Lib\site-packages下,就可
-
Python实现的三层BP神经网络算法示例
本文实例讲述了Python实现的三层BP神经网络算法.分享给大家供大家参考,具体如下: 这是一个非常漂亮的三层反向传播神经网络的python实现,下一步我准备试着将其修改为多层BP神经网络. 下面是运行演示函数的截图,你会发现预测的结果很惊人! 提示:运行演示函数的时候,可以尝试改变隐藏层的节点数,看节点数增加了,预测的精度会否提升 import math import random import string random.seed(0) # 生成区间[a, b)内的随机数 def rand(
-
Python实现感知器模型、两层神经网络
本文实例为大家分享了Python实现感知器模型.两层神经网络,供大家参考,具体内容如下 python 3.4 因为使用了 numpy 这里我们首先实现一个感知器模型来实现下面的对应关系 [[0,0,1], --- 0 [0,1,1], --- 1 [1,0,1], --- 0 [1,1,1]] --- 1 从上面的数据可以看出:输入是三通道,输出是单通道. 这里的激活函数我们使用 sigmoid 函数 f(x)=1/(1+exp(-x)) 其导数推导如下所示: L0=W*X; z=f(L0);
-
Python实现的径向基(RBF)神经网络示例
本文实例讲述了Python实现的径向基(RBF)神经网络.分享给大家供大家参考,具体如下: from numpy import array, append, vstack, transpose, reshape, \ dot, true_divide, mean, exp, sqrt, log, \ loadtxt, savetxt, zeros, frombuffer from numpy.linalg import norm, lstsq from multiprocessing impor
-
python实现神经网络感知器算法
现在我们用python代码实现感知器算法. # -*- coding: utf-8 -*- import numpy as np class Perceptron(object): """ eta:学习率 n_iter:权重向量的训练次数 w_:神经分叉权重向量 errors_:用于记录神经元判断出错次数 """ def __init__(self, eta=0.01, n_iter=2): self.eta = eta self.n_iter
-
python构建深度神经网络(续)
这篇文章在前一篇文章:python构建深度神经网络(DNN)的基础上,添加了一下几个内容: 1) 正则化项 2) 调出中间损失函数的输出 3) 构建了交叉损失函数 4) 将训练好的网络进行保存,并调用用来测试新数据 1 数据预处理 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2017-03-12 15:11 # @Author : CC # @File : net_load_data.py from numpy import
-
python构建深度神经网络(DNN)
本文学习Neural Networks and Deep Learning 在线免费书籍,用python构建神经网络识别手写体的一个总结. 代码主要包括两三部分: 1).数据调用和预处理 2).神经网络类构建和方法建立 3).代码测试文件 1)数据调用: #!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2017-03-12 15:11 # @Author : CC # @File : net_load_data.py # @Soft