基于Java中最常用的集合类框架之HashMap(详解)
一、HashMap的概述
HashMap可以说是Java中最常用的集合类框架之一,是Java语言中非常典型的数据结构。
HashMap是基于哈希表的Map接口实现的,此实现提供所有可选的映射操作。存储的是对的映射,允许多个null值和一个null键。但此类不保证映射的顺序,特别是它不保证该顺序恒久不变。
除了HashMap是非同步以及允许使用null外,HashMap 类与 Hashtable大致相同。
此实现假定哈希函数将元素适当地分布在各桶之间,可为基本操作(get 和 put)提供稳定的性能。迭代collection 视图所需的时间与 HashMap 实例的“容量”(桶的数量)及其大小(键-值映射关系数)成比例。所以,如果迭代性能很重要,则不要将初始容量设置得太高(或将加载因子设置得太低)。
HashMap 的实例有两个参数影响其性能:初始容量 和加载因子。容量 是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子 (0.75) 在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
注意,此实现不是同步的。 如果多个线程同时访问一个HashMap实例,而其中至少一个线程从结构上修改了列表,那么它必须保持外部同步。这通常是通过同步那些用来封装列表的 对象来实现的。但如果没有这样的对象存在,则应该使用{@link Collections#synchronizedMap Collections.synchronizedMap}来进行“包装”,该方法最好是在创建时完成,为了避免对映射进行意外的非同步操作。
Map m = Collections.synchronizedMap(new HashMap(...));
二、构造函数
HashMap提供了三个构造函数:
HashMap():构造一个具有默认初始容量 (16) 和默认加载因子 (0.75) 的空 HashMap。
HashMap(int initialCapacity):构造一个带指定初始容量和默认加载因子 (0.75) 的空 HashMap。
HashMap(int initialCapacity, float loadFactor):构造一个带指定初始容量和加载因子的空 HashMap。
这里提到了两个参数:初始容量,加载因子。这两个参数是影响HashMap性能的重要参数,其中容量表示哈希表中桶的数量,初始容量是创建哈希表时的容量,加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度,它衡量的是一个散列表的空间的使用程度,负载因子越大表示散列表的装填程度越高,反之愈小。对于使用链表法的散列表来说,查找一个元素的平均时间是O(1+a),因此如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低;如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费。系统默认负载因子为0.75,一般情况下我们是无需修改的。
HashMap是一种支持快速存取的数据结构,要了解它的性能必须要了解它的数据结构。
三、数据结构
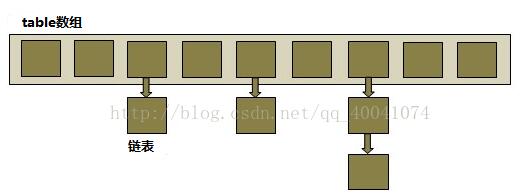
我们知道在Java中最常用的两种结构是数组和模拟指针(引用),几乎所有的数据结构都可以利用这两种来组合实现,HashMap也是如此。实际上HashMap是一个“链表散列”,如下是它数据结构:
// Entry是单向链表。 它是 “HashMap链式存储法”对应的链表。
// 实现了Map.Entry接口,即getKey(),getValue(),setValue(V value),equals(Object o),hashCode()这些函数
static class Entry implements Map.Entry {
final K key;
V value;
// 指向下一个节点
Entry next;
final int hash;
// 构造函数
// 输入参数包括"哈希值(h)", "键(k)", "值(v)", "下一节点(n)"
Entry(int h, K k, V v, Entry n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() {
return key;
}
public final V getValue() {
return value;
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 判断两个Entry是否相等
// 若两个Entry的“key”和“value”都相等,则返回true。
// 否则,返回false
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
// 实现hashCode()
public final int hashCode() {
return (key==null ? 0 : key.hashCode()) ^
(value==null ? 0 : value.hashCode());
}
public final String toString() {
return getKey() + "=" + getValue();
}
// 当向HashMap中添加元素时,绘调用recordAccess()。
// 这里不做任何处理
void recordAccess(HashMap m) {
}
// 当从HashMap中删除元素时,绘调用recordRemoval()。
// 这里不做任何处理
void recordRemoval(HashMap m) {
}
}
从上图我们可以看出HashMap底层实现还是数组,只是数组的每一项都是一条链。其中参数initialCapacity就代表了该数组的长度。下面为HashMap构造函数的源码:
// 找出“大于Capacity”的最小的2的幂,使Hash表的容量保持为2的次方倍
// 算法的思想:通过使用逻辑运算来替代取余,这里有一个规律,就是当N为2的次方(Power of two),那么X%N==X&(N-1)。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1; // >>> 无符号右移,高位补0
n |= n >>> 2; // a|=b的意思就是把a和b按位或然后赋值给a
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
// 构造一个带指定初始容量和加载因子的空HashMap
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
// 构造一个带指定初始容量和默认加载因子(0.75)的空 HashMap
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 构造一个具有默认初始容量 (16)和默认加载因子 (0.75)的空 HashMap
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
// 构造一个映射关系与指定 Map相同的新 HashMap,容量与指定Map容量相同,加载因子为默认的0.75
public HashMap(Map m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
从源码中可以看出,每次新建一个HashMap时,都会初始化一个table数组。table数组的元素为Entry节点。
// Entry是单向链表。
// 它是 “HashMap链式存储法”对应的链表。
// 它实现了Map.Entry 接口,即实现getKey(), getValue(), setValue(V value), equals(Object o), hashCode()这些函数
static class Entry implements Map.Entry {
final K key;
V value;
// 指向下一个节点
Entry next;
final int hash;
// 构造函数。
// 输入参数包括"哈希值(h)", "键(k)", "值(v)", "下一节点(n)"
Entry(int h, K k, V v, Entry n) {
value = v;
next = n;
key = k;
hash = h;
}
......
}
其中Entry为HashMap的内部类,它包含了键key、值value、下一个节点next,以及hash值,这是非常重要的,正是由于Entry才构成了table数组的项为链表。
以上这篇基于Java中最常用的集合类框架之HashMap(详解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

JAVA HashMap详细介绍和示例
第1部分 HashMap介绍HashMap简介HashMap 是一个散列表,它存储的内容是键值对(key-value)映射.HashMap 继承于AbstractMap,实现了Map.Cloneable.java.io.Serializable接口.HashMap 的实现不是同步的,这意味着它不是线程安全的.它的key.value都可以为null.此外,HashMap中的映射不是有序的.HashMap 的实例有两个参数影响其性能:"初始容量" 和 "加载因子".容量
-
详谈java集合框架
1.为什么使用集合框架 当我们并不知道程序运行时会需要多少对象,或者需要更复杂方式存储对象--可以使用Java集合框架 2.Java集合框架包含的内容 接口:(父类)Collection接口下包含List(子类 )接口和Set(子类) 接口 List接口下又包含(ArrayList集合实现类和LinkedList集合实现类) Set接口下又包含(HashSet集合实现类和TreeSet集合实现类) 接口:(父类)Map接口下包含(HashMap集合实现类和TreeMap 集合实现类) *Coll
-
Java复习之集合框架总结
俗话说:温故而知新.想想学过的知识,就算是以前学得很不错,久不用了,就会忘记,所以温习一下以前学习的知识我认为是非常有必要的.而本篇文件温习的是 Java基础中的集合框架. 为什么会有集合框架? 平时我们用数组存储一些基本的数据类型,或者是引用数据类型,但是数组的长度是固定的,当添加的元素超过了数组的长度时,需要对数组进行重新的定义,这样就会显得写程序太麻烦,所以Java内部为了我们方便,就提供了集合类,能存储任意对象,长度是可以改变的,随着元素的增加而增加,随着元素的减少而减少. 数组可以存储
-
基于Java中最常用的集合类框架之HashMap(详解)
一.HashMap的概述 HashMap可以说是Java中最常用的集合类框架之一,是Java语言中非常典型的数据结构. HashMap是基于哈希表的Map接口实现的,此实现提供所有可选的映射操作.存储的是对的映射,允许多个null值和一个null键.但此类不保证映射的顺序,特别是它不保证该顺序恒久不变. 除了HashMap是非同步以及允许使用null外,HashMap 类与 Hashtable大致相同. 此实现假定哈希函数将元素适当地分布在各桶之间,可为基本操作(get 和 put)提供稳定的性
-
基于JAVA中使用Axis发布/调用Webservice的方法详解
本示例和参考文章的差别在于: 1)deploy.wsdd定义的更详细(对于server端定义了接口:ICalculate): 复制代码 代码如下: <deployment xmlns="http://xml.apache.org/axis/wsdd/" xmlns:java="http://xml.apache.org/axis/wsdd/providers/java"> <service name="Calculate&qu
-
Java中的引用和动态代理的实现详解
我们知道,动态代理(这里指JDK的动态代理)与静态代理的区别在于,其真实的代理类是动态生成的.但具体是怎么生成,生成的代理类包含了哪些内容,以什么形式存在,它为什么一定要以接口为基础? 如果去看动态代理的源代码(java.lang.reflect.Proxy),会发现其原理很简单(真正二进制类文件的生成是在本地方法中完成,源代码中没有),但其中用到了一个缓冲类java.lang.reflect.WeakCache<ClassLoader,Class<?>[],Class<?>
-
基于Spring中各个jar包的作用及依赖(详解)
先附spring各版本jar包下载链接http://repo.spring.io/release/org/springframework/spring/ spring.jar 是包含有完整发布模块的单个jar 包.但是不包括mock.jar, aspects.jar, spring-portlet.jar, and spring-hibernate2.jar 示例图片为Spring-2.5.6.jar的包目录 下面讲解各个jar包的作用: 1.org.springframework.aop或sp
-
java 中mongodb的各种操作查询的实例详解
java 中mongodb的各种操作查询的实例详解 一. 常用查询: 1. 查询一条数据:(多用于保存时判断db中是否已有当前数据,这里 is 精确匹配,模糊匹配 使用regex...) public PageUrl getByUrl(String url) { return findOne(new Query(Criteria.where("url").is(url)),PageUrl.class); } 2. 查询多条数据:linkUrl.id 属于分级查询 public Lis
-
基于mpvue搭建微信小程序项目框架的教程详解
简介: mpvue框架对于从没有接触过小程序又要尝试小程序开发的人员来说,无疑是目前最好的选择.mpvue从底层支持 Vue.js 语法和构建工具体系,同时再结合相关UI组件库,便可以高效的实现小程序开发 前言: 本文讲述如何搭建完整的小程序项目框架,因为是第一次使用,有不完善的地方请大佬指正. 搭建内容包括: 1.使用scss语法:依赖插件sass-loader .node-sass 2.像vue一样使用路由:依赖插件 mpvue-entry 和 mpvue-router-patch 3.使用
-
java中Servlet监听器的工作原理及示例详解
监听器就是一个实现特定接口的普通java程序,这个程序专门用于监听另一个java对象的方法调用或属性改变,当被监听对象发生上述事件后,监听器某个方法将立即被执行. 监听器原理 监听原理 1.存在事件源 2.提供监听器 3.为事件源注册监听器 4.操作事件源,产生事件对象,将事件对象传递给监听器,并且执行监听器相应监听方法 监听器典型案例:监听window窗口的事件监听器 例如:swing开发首先制造Frame**窗体**,窗体本身也是一个显示空间,对窗体提供监听器,监听窗体方法调用或者属性改变:
-
java中常见的6种线程池示例详解
之前我们介绍了线程池的四种拒绝策略,了解了线程池参数的含义,那么今天我们来聊聊Java 中常见的几种线程池,以及在jdk7 加入的 ForkJoin 新型线程池 首先我们列出Java 中的六种线程池如下 线程池名称 描述 FixedThreadPool 核心线程数与最大线程数相同 SingleThreadExecutor 一个线程的线程池 CachedThreadPool 核心线程为0,最大线程数为Integer. MAX_VALUE ScheduledThreadPool 指定核心线程数的定时
-
Java中关于二叉树的概念以及搜索二叉树详解
目录 一.二叉树的概念 为什么要使用二叉树? 树是什么? 树的相关术语! 根节点 路径 父节点 子节点 叶节点 子树 访问 层(深度) 关键字 满二叉树 完全二叉树 二叉树的五大性质 二.搜索二叉树 插入 删除 hello, everyone. Long time no see. 本期文章,我们主要讲解一下二叉树的相关概念,顺便也把搜索二叉树(也叫二叉排序树)讲一下.我们直接进入正题吧!GitHub源码链接 一.二叉树的概念 为什么要使用二叉树? 为什么要用到树呢?因为它通常结合了另外两种数据结
-
java中 Set与Map排序输出到Writer详解及实例
java中 Set与Map排序输出到Writer详解及实例 一般来说java.util.Set,java.util.Map输出的内容的顺序并不是按key的顺序排列的,但是java.util.TreeMap,java.util.TreeSet的实现却可以让Map/Set中元素内容以key的顺序排序,所以利用这个特性,可以将Map/Set转为TreeMap,TreeSet然后实现排序输出. 以下是实现的代码片段: /** * 对{@link Map}中元素以key排序后,每行以{key}={val