Jsoup获取全国地区数据属性值(省市县镇村)
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
最近手头在做一些东西,需要一个全国各地的地域数据,从省市区到县镇乡街道的。各种度娘,各种谷歌,都没找到一个完整的数据。最后功夫不负有心人,总算找到一份相对来说比较完整的数据,但是这里的数据也只是精确到镇级别,没有村一级的数据(后来通过分析数据源我知道了为什么,呵呵),在加上博主提供的有些数据存在冗余,对于有强迫症和追求完美的我,心想着我一定要自己动手去把这部分数据给爬取出来。
上述博文中的内容还算丰富,博主是用的是php来实现的,作为2015年度编程语言排行榜的第一位,我们也不能示弱啊,下面我就带着大家一起来看看用java怎么从网页当中爬取我们想要的数据...
第一步、准备工作(数据源+工具):
数据源(截止目前最全面权威的官方数据):http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2013/
爬取数据的工具(爬虫工具):http://jsoup.org/
第二步、数据源分析:
首先jsoup工具的使用我在这里就不做讲解了,感兴趣的可以自己动手去查阅。
做开发就应该多去了解一些软件工具的使用,在平常开发过程中遇到了才知道从何下手,鼓励大家多平时留意一些身边的软件工具,以备不时之需。在做这个东西以前,我也不知道jsoup要怎么用,但我知道jsoup可以用来干嘛,在我需要的用到的时候,再去查阅资料,自己学习。
上述的数据源是2013年中华人民共和国国家统计局发布的,其准确性和权威性不言而喻。
接下来我们分析一下数据源的结构,先从首页说起: 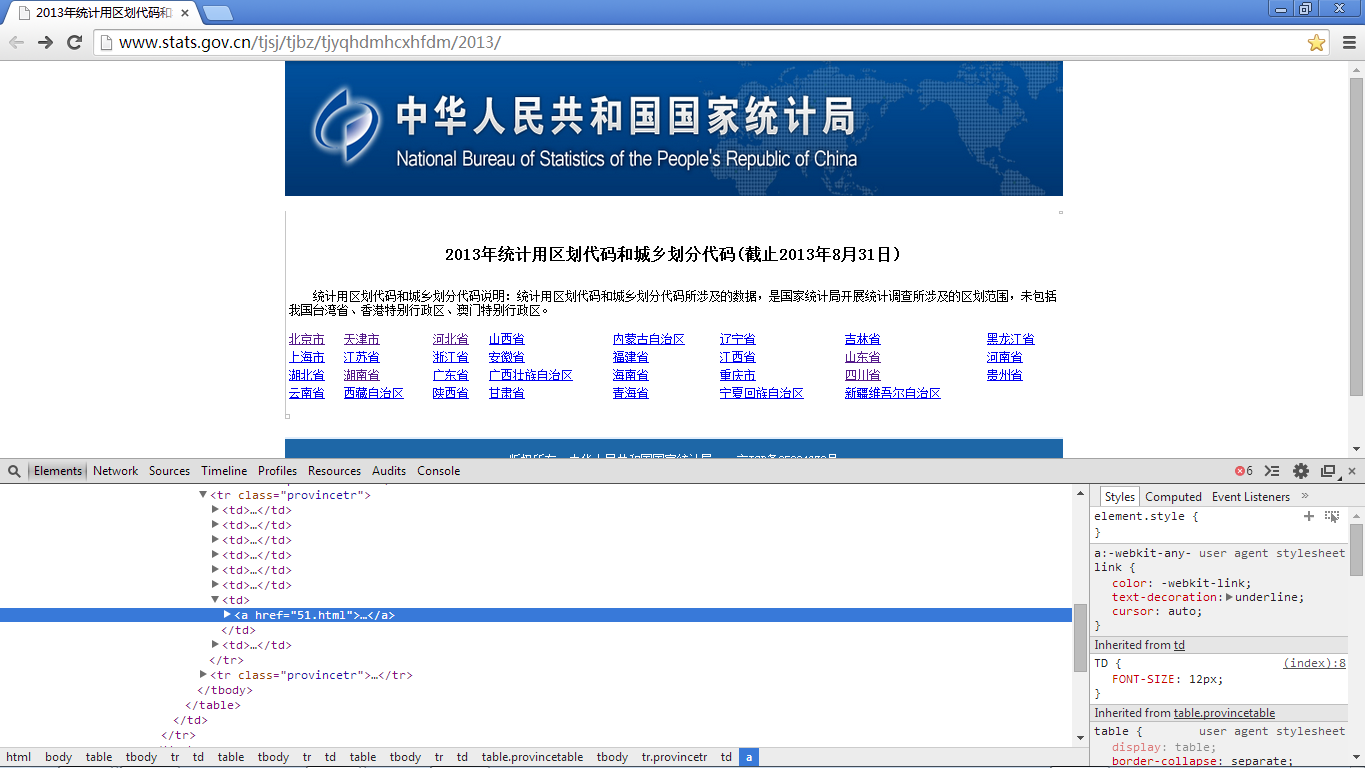
通过分析首页源码我们可以得到如下3点:
1.页面的整个布局是用的table标签来控制的,也就是说我们如果要通过jsoup来选择超链接,那么一定要注意,上图中不是只要标注了省市地区的地方采用的才是表格,整个页面中存在多个表格,因此是不可以直接通过表格
Document connect = connect("http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2013/");
Elements rowProvince = connect.select("table");
来解析数据的。
2.页面中有超链接的部分有多少地方。可能是官方考虑到了你们这种程序员需要获取这样的数据的原因吧,页面很干净,除开下方的备案号是多余的超链接,其他的链接可以直接爬取。
3.省份城市的数据规律。包含有效信息的表格的每一行都有一个class属性provincetr,这个属性很重要,至于为什么重要,请接着往下看;每一行数据中存在多个td标签,每一个td标签中包含一个a超链接,而这个超链接正是我们想要的超链接,超链接的文本即使省份(直辖市等)的名称。
再次我们再看一下一般的数据页面(一般的数据页面包括市级、县级、镇级这三级数据展示页面):
之所以要把上述三个页面放在一起,是因为通过分析我们可以发现,这三级数据的数据页面完全一致,唯一不同的就是在html源码数据表格中的数据行tr的class属性不一致,分别对应为:citytr,countrytrhe towntr。其他均一致。这样我们就可以用一个通用的方法解决这三个页面的数据爬取。
接下来我们分析一下数据源的结构,先从首页说起:
最后看看村一级的数据页面:
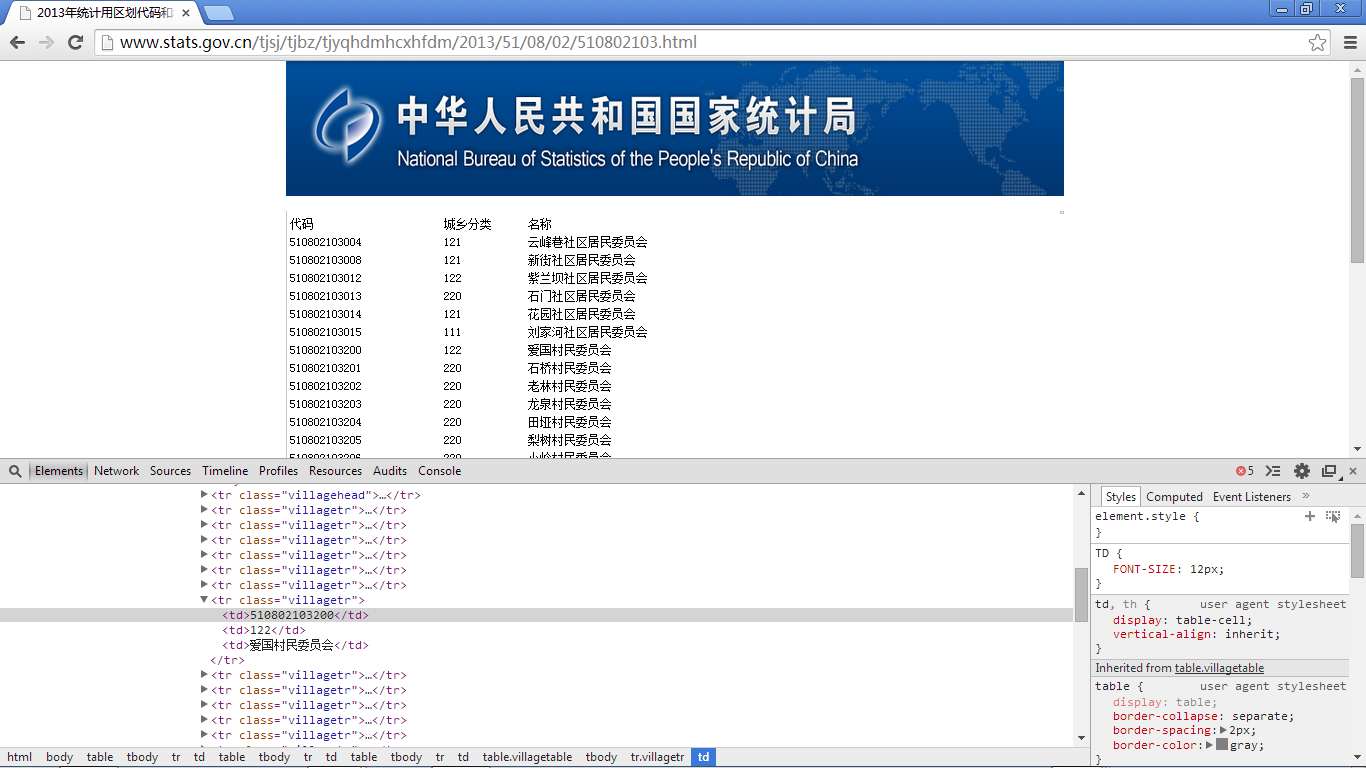
在村一级的数据中,和上述市县镇的数据格式不一致,这一级所表示的数据是最低一级的,所以不存在a链接,因此不能采用上面市县镇数据的爬取方式去爬取;这里展示数据的表格行的class为villagetr,除开这两点以外,在每一行数据中包含三列数据,第一列是citycode,第二列是城乡分类(市县镇的数据格式不存在这一项),第三列是城市名称。
把握了以上各个要点之外,我们就可以开始编码了。
第三步、编码实现:
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/**
* 全国省市县镇村数据爬取
* @author liushaofeng
* @date -- 上午::
* @version ..
*/
public class JsoupTest
{
private static Map<Integer, String> cssMap = new HashMap<Integer, String>();
private static BufferedWriter bufferedWriter = null;
static
{
cssMap.put(, "provincetr");// 省
cssMap.put(, "citytr");// 市
cssMap.put(, "countytr");// 县
cssMap.put(, "towntr");// 镇
cssMap.put(, "villagetr");// 村
}
public static void main(String[] args) throws IOException
{
int level = ;
initFile();
// 获取全国各个省级信息
Document connect = connect("http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm//");
Elements rowProvince = connect.select("tr." + cssMap.get(level));
for (Element provinceElement : rowProvince)// 遍历每一行的省份城市
{
Elements select = provinceElement.select("a");
for (Element province : select)// 每一个省份(四川省)
{
parseNextLevel(province, level + );
}
}
closeStream();
}
private static void initFile()
{
try
{
bufferedWriter = new BufferedWriter(new FileWriter(new File("d:\\CityInfo.txt"), true));
} catch (IOException e)
{
e.printStackTrace();
}
}
private static void closeStream()
{
if (bufferedWriter != null)
{
try
{
bufferedWriter.close();
} catch (IOException e)
{
e.printStackTrace();
}
bufferedWriter = null;
}
}
private static void parseNextLevel(Element parentElement, int level) throws IOException
{
try
{
Thread.sleep();//睡眠一下,否则可能出现各种错误状态码
} catch (InterruptedException e)
{
e.printStackTrace();
}
Document doc = connect(parentElement.attr("abs:href"));
if (doc != null)
{
Elements newsHeadlines = doc.select("tr." + cssMap.get(level));//
// 获取表格的一行数据
for (Element element : newsHeadlines)
{
printInfo(element, level + );
Elements select = element.select("a");// 在递归调用的时候,这里是判断是否是村一级的数据,村一级的数据没有a标签
if (select.size() != )
{
parseNextLevel(select.last(), level + );
}
}
}
}
/**
* 写一行数据到数据文件中去
* @param element 爬取到的数据元素
* @param level 城市级别
*/
private static void printInfo(Element element, int level)
{
try
{
bufferedWriter.write(element.select("td").last().text() + "{" + level + "}["
+ element.select("td").first().text() + "]");
bufferedWriter.newLine();
bufferedWriter.flush();
} catch (IOException e)
{
e.printStackTrace();
}
}
private static Document connect(String url)
{
if (url == null || url.isEmpty())
{
throw new IllegalArgumentException("The input url('" + url + "') is invalid!");
}
try
{
return Jsoup.connect(url).timeout( * ).get();
} catch (IOException e)
{
e.printStackTrace();
return null;
}
}
}
数据爬取过程便是一个漫长的过程,只需要慢慢等待吧,呵呵,由于程序运行时间较长,请不要在控制台打印输出,否则可能会影响程序运行....
最终获取到数据的格式如下("{}"中表示城市级别,"[]"中内容表示城市编码):
市辖区{3}[110100000000]
东城区{4}[110101000000]
东华门街道办事处{5}[110101001000]
多福巷社区居委会{6}[110101001001]
银闸社区居委会{6}[110101001002]
东厂社区居委会{6}[110101001005]
智德社区居委会{6}[110101001006]
南池子社区居委会{6}[110101001007]
黄图岗社区居委会{6}[110101001008]
灯市口社区居委会{6}[110101001009]
正义路社区居委会{6}[110101001010]
甘雨社区居委会{6}[110101001011]
台基厂社区居委会{6}[110101001013]
韶九社区居委会{6}[110101001014]
王府井社区居委会{6}[110101001015]
景山街道办事处{5}[110101002000]
隆福寺社区居委会{6}[110101002001]
吉祥社区居委会{6}[110101002002]
黄化门社区居委会{6}[110101002003]
钟鼓社区居委会{6}[110101002004]
魏家社区居委会{6}[110101002005]
汪芝麻社区居委会{6}[110101002006]
景山东街社区居委会{6}[110101002008]
皇城根北街社区居委会{6}[110101002009]
交道口街道办事处{5}[110101003000]
交东社区居委会{6}[110101003001]
福祥社区居委会{6}[110101003002]
大兴社区居委会{6}[110101003003]
府学社区居委会{6}[110101003005]
鼓楼苑社区居委会{6}[110101003007]
菊儿社区居委会{6}[110101003008]
南锣鼓巷社区居委会{6}[110101003009]
安定门街道办事处{5}[110101004000]
交北头条社区居委会{6}[110101004001]
北锣鼓巷社区居委会{6}[110101004002]
国子监社区居委会{6}[110101004003]
......
拿到以上数据以后,自己想干什么都可以自我去实现了,以上的代码可以直接运行,从数据源爬取后,可以直接转换成自己所要的格式。
相关推荐
-
JavaScript获取客户端IP的方法(新方法)
很久以来,我都是经过http://fw.qq.com/ipaddress来得到客户端用户的IP,这个方法简单.快速.实用 . 我们调用它的写法是: <script type="text/javascript" src="http://fw.qq.com/ipaddress"></script> 它可以返回用户IP和地点,比喻: var IPData = new Array("220.181.108.85","&q
-
nodejs获取本机内网和外网ip地址的实现代码
实现代码: 复制代码 代码如下: var os = require('os');function getLocalIP() { var map = []; var ifaces = os.networkInterfaces(); console.log(ifaces); for (var dev in ifaces) { if (dev.indexOf('eth0') != -1) { var tokens = dev.split(':');
-
JS实现的验证身份证及获取地区功能示例
本文实例讲述了JS实现的验证身份证及获取地区功能.分享给大家供大家参考,具体如下: 这里的代码可以用来验证身份证号,并且根据身份证号来判断是哪个省份及性别 代码示例: <head > <title></title> <script src="Scripts/jquery-1.4.1.min.js" type="text/javascript"></script> </head> <body
-
JS获取客户端IP地址、MAC和主机名的7个方法汇总
今天在搞JS(javascript)获取客户端IP的小程序,上网搜了下,好多在现在的系统和浏览器中的都无效,很无奈,在Chrome.FireFox中很少搞到直接利用ActiveX获取IP等的JS脚本.下面的代码是我在所有windowsNT5.0及以上的系统上都测试通过的,给出代码: 一.使用JS获取客户端IP的几个方法 方法一(只针对IE且客户端的IE允许AcitiveX运行,通过平台:XP,SERVER03,2000). 获取客户端IP代码: 复制代码 代码如下: <HTML> <HE
-
js获取客户端外网ip的简单实例
var wwip=""; $(function(){ $(document).ready( function() { $.getJSON( "http://smart-ip.net/geoip-json?callback=?", function(data){ alert( data.host); wwip=data.host; } ); }); }); 这个问题查了很多资料,都不可以,这个还好用. 例子,js获取本地与外网IP地址. <script lang
-
js获取IP地址的方法小结
1,js取得IP地址的方法一 <script src="http://pv.sohu.com/cityjson?ie=utf-8"></script> <script type="text/<A class=infotextkey href="http://www.jb51.net/" target=_blank>javascript</A>"> document.write(retur
-
JSP 获取真实IP地址的代码
但是在通过了 Apache,Squid等反向代理软件就不能获取到客户端的真实IP地址了.如果使用了反向代理软件,用 request.getRemoteAddr()方法获取的IP地址是:127.0.0.1或 192.168.1.110,而并不是客户端的真实IP. 经过代理以后,由于在客户端和服务之间增加了中间层,因此服务器无法直接拿到客户端的 IP,服务器端应用也无法直接通过转发请求的地址返回给客户端.但是在转发请求的HTTP头信息中,增加了X-FORWARDED-FOR信息.用以跟踪原有的客户端
-

js获取ip和地区
这个接口是搜狐的目前是可用的, 就是不知道以后会不会失效 效果图: 代码如下: <!doctype html> <html> <head> <meta charset="utf-8"> <title>t1</title> <meta content="width=device-width,initial-scale=1.0,maximum-scale=1.0,user-scalable=0"
-
JS获取IP、MAC和主机名的五种方法
今天在搞JS(javascript)获取客户端IP的小程序,上网搜了下,好多在现在的系统和浏览器中的都无效,很无奈,在Chrome.FireFox中很少搞到直接利用ActiveX获取IP等的JS脚本.下面的代码是我在所有windowsNT5.0及以上的系统上都测试通过的,给出代码: 方法一(只针对IE且客户端的IE允许AcitiveX运行,通过平台:XP,SERVER03,2000): 获取客户端IP. 复制代码 代码如下: <HTML> <HEAD> <TITLE>G
-
Jsoup获取全国地区数据属性值(省市县镇村)
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址.HTML文本内容.它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据. 最近手头在做一些东西,需要一个全国各地的地域数据,从省市区到县镇乡街道的.各种度娘,各种谷歌,都没找到一个完整的数据.最后功夫不负有心人,总算找到一份相对来说比较完整的数据,但是这里的数据也只是精确到镇级别,没有村一级的数据(后来通过分析数据源我知道了为什么,呵呵),在加上博主提供的有些数据存在冗余,对于有
-
python获取全国最新省市区数据并存入表实例代码
本文通过调取高德行政区划查询接口,获取最新的数据信息(省.市.区.经纬度.行政级别.城市编码.行政编码等),并通过mysql.connector存入mysql数据库 表结构设计如下: CREATE TABLE `districts` ( `districtId` int(11) NOT NULL AUTO_INCREMENT, `districtPid` int(11) DEFAULT NULL COMMENT '上级ID', `name` varchar(32) DEFAULT NULL CO
-
php获取数组中键值最大数组项的索引值 原创
本文实例讲述了php获取数组中键值最大数组项的索引值的方法.分享给大家供大家参考.具体分析如下: 一.问题: 从给定数组中获取值最大的数组项的键值.用途如:获取班级得分最高的学生的姓名. 二.解决方法: <?php /* * Created on 2015-3-17 * Created by www.jb51.net */ $arr=array('tom'=>9,'jack'=>3,'kim'=>5,'hack'=>4); asort($arr); //print_r($ar
-
怎么通过onclick事件获取js函数返回值(代码少)
具体过程不做详细叙述,直接上代码: 写一个弹出框,绑定onclick事件是好像控制不了它的返回值.代码如下 function createBtn(){ for(var i = 0; i < _this.btn.length; i++){ var btn = document.createElement('span'); btn.id = 'btn_' + i; btn.innerHTML = _this.btn[i]; btn.style.padding = '5px 15px'; btn.st
-
jquery获取img的src值的简单实例
简简单单的一句话,如下: <img id="test" src="1.jpg" alt="test" /> 引用的jquery如下: <script type="text/javascript" language="javascript" src="~/Js/jquery-1.2.6.js"></script> <script type=&quo
-
JS与jQuery实现子窗口获取父窗口元素值的方法
本文实例讲述了JS与jQuery实现子窗口获取父窗口元素值的方法.分享给大家供大家参考,具体如下: 功能描述:父窗口有一个input,和一个button ,点击button打开子窗口,在子窗口中获取父窗口中input的值,并显示. js: 父窗口: <input type="text" name="currentProjectIDForDetail" id="currentProjectIDForDetail" disabled="
-
一览画面点击复选框后获取多个id值的方法
在web开发中经常会遇到一览画面中每一条记录前都带一个复选框,点击后选中该条记录进行删除.修改.查看等操作. 修改和查看都是获取一条记录的id值后传递到后台进行查询获取该记录对象的各种属性值,再显示到画面上. 我说的重点是选中多条记录后进行批量删除,如何获取多条记录的id值是问题的关键.首先是在jsp页面中全选中复选框的方法. 代码如下: function checkEvent(name, allCheckId) { var allCk = document.getElementById(all
-
PHP简单获取多个checkbox值的方法
本文实例讲述了PHP简单获取多个checkbox值的方法.分享给大家供大家参考,具体如下: HTML页面: <html> <head> </head> <body> <form name="myform" enctype="multipart/form-data" action="index2.php" method="post"> 兴趣爱好:<input ty
-
PHP 获取指定地区的天气实例代码
PHP 获取指定地区的天气 在开发网站的时候用到天气查询,由于是基于Wordpress的 所以有很多限制,先建一个[weather.PHP]的文件,然后看代码: <?php //获取天气 $url = 'http://m.weather.com.cn/data/'; $id = '101181101'; //焦作的代号 $data = file_get_contents($url . $id .'.html'); $obj=json_decode($data); echo $obj->weat
-
Python获取任意xml节点值的方法
本文实例讲述了Python获取任意xml节点值的方法.分享给大家供大家参考.具体实现方法如下: # -*- coding: utf-8 -*- import xml.dom.minidom ELEMENT_NODE = xml.dom.Node.ELEMENT_NODE class SimpleXmlGetter(object): def __init__(self, data): if type(data) == str: self.root = xml.dom.minidom.parse(d