Python3.5 Pandas模块缺失值处理和层次索引实例详解
本文实例讲述了Python3.5 Pandas模块缺失值处理和层次索引。分享给大家供大家参考,具体如下:
1、pandas缺失值处理

import numpy as np
import pandas as pd
from pandas import Series,DataFrame
df3 = DataFrame([
["Tom",np.nan,456.67,"M"],
["Merry",34,345.56,np.nan],
[np.nan,np.nan,np.nan,np.nan],
["John",23,np.nan,"M"],
["Joe",18,385.12,"F"]
],columns = ["name","age","salary","gender"])
print(df3)
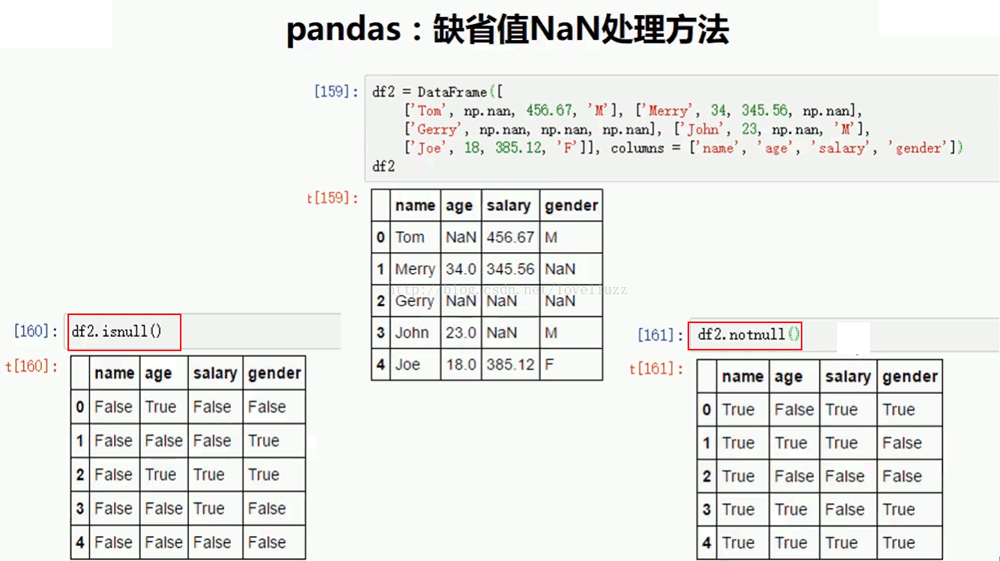
print("=======判断NaN值=======")
print(df3.isnull())
print("=======判断非NaN值=======")
print(df3.notnull())
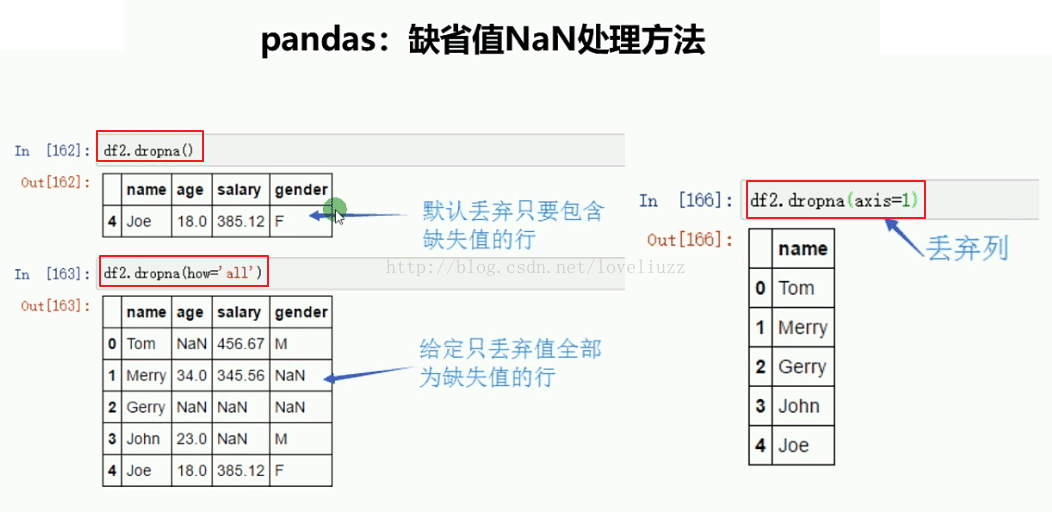
print("=======删除包含NaN值的行=======")
print(df3.dropna())
print("=======删除全部为NaN值的行=======")
print(df3.dropna(how="all"))
df3.ix[2,0] = "Gerry" #修改第2行第0列的值
print(df3)
print("=======删除包含NaN值的列=======")
print(df3.dropna(axis=1))
运行结果:
name age salary gender
0 Tom NaN 456.67 M
1 Merry 34.0 345.56 NaN
2 NaN NaN NaN NaN
3 John 23.0 NaN M
4 Joe 18.0 385.12 F
=======判断NaN值=======
name age salary gender
0 False True False False
1 False False False True
2 True True True True
3 False False True False
4 False False False False
=======判断非NaN值=======
name age salary gender
0 True False True True
1 True True True False
2 False False False False
3 True True False True
4 True True True True
=======删除包含NaN值的行=======
name age salary gender
4 Joe 18.0 385.12 F
=======删除全部为NaN值的行=======
name age salary gender
0 Tom NaN 456.67 M
1 Merry 34.0 345.56 NaN
3 John 23.0 NaN M
4 Joe 18.0 385.12 F
name age salary gender
0 Tom NaN 456.67 M
1 Merry 34.0 345.56 NaN
2 Gerry NaN NaN NaN
3 John 23.0 NaN M
4 Joe 18.0 385.12 F
=======删除包含NaN值的列=======
name
0 Tom
1 Merry
2 Gerry
3 John
4 Joe

import numpy as np
import pandas as pd
from pandas import Series,DataFrame
df4 = DataFrame(np.random.randn(7,3))
print(df4)
df4.ix[:4,1] = np.nan #第0至3行,第1列的数据
df4.ix[:2,2] = np.nan
print(df4)
print(df4.fillna(0)) #将缺失值用传入的指定值0替换
print(df4.fillna({1:0.5,2:-1})) #将缺失值按照指定形式填充
运行结果:
0 1 2
0 -0.737618 -0.530302 -2.716457
1 0.810339 0.063028 -0.341343
2 0.070564 0.347308 -0.121137
3 -0.501875 -1.573071 -0.816077
4 -2.159196 -0.659185 -0.885185
5 0.175086 -0.954109 -0.758657
6 0.395744 -0.875943 0.950323
0 1 2
0 -0.737618 NaN NaN
1 0.810339 NaN NaN
2 0.070564 NaN NaN
3 -0.501875 NaN -0.816077
4 -2.159196 NaN -0.885185
5 0.175086 -0.954109 -0.758657
6 0.395744 -0.875943 0.950323
0 1 2
0 -0.737618 0.000000 0.000000
1 0.810339 0.000000 0.000000
2 0.070564 0.000000 0.000000
3 -0.501875 0.000000 -0.816077
4 -2.159196 0.000000 -0.885185
5 0.175086 -0.954109 -0.758657
6 0.395744 -0.875943 0.950323
0 1 2
0 -0.737618 0.500000 -1.000000
1 0.810339 0.500000 -1.000000
2 0.070564 0.500000 -1.000000
3 -0.501875 0.500000 -0.816077
4 -2.159196 0.500000 -0.885185
5 0.175086 -0.954109 -0.758657
6 0.395744 -0.875943 0.950323
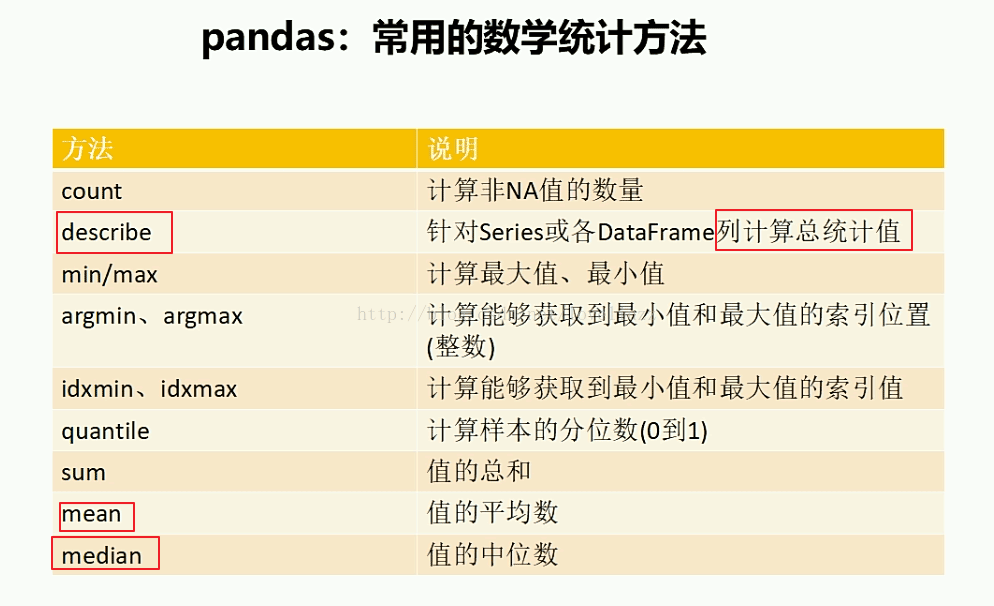
2、pandas常用数学统计方法

import numpy as np
import pandas as pd
from pandas import Series,DataFrame
#pandas常用数学统计方法
arr = np.array([
[98.5,89.5,88.5],
[98.5,85.5,88],
[70,85,60],
[80,85,82]
])
df1 = DataFrame(arr,columns=["语文","数学","英语"])
print(df1)
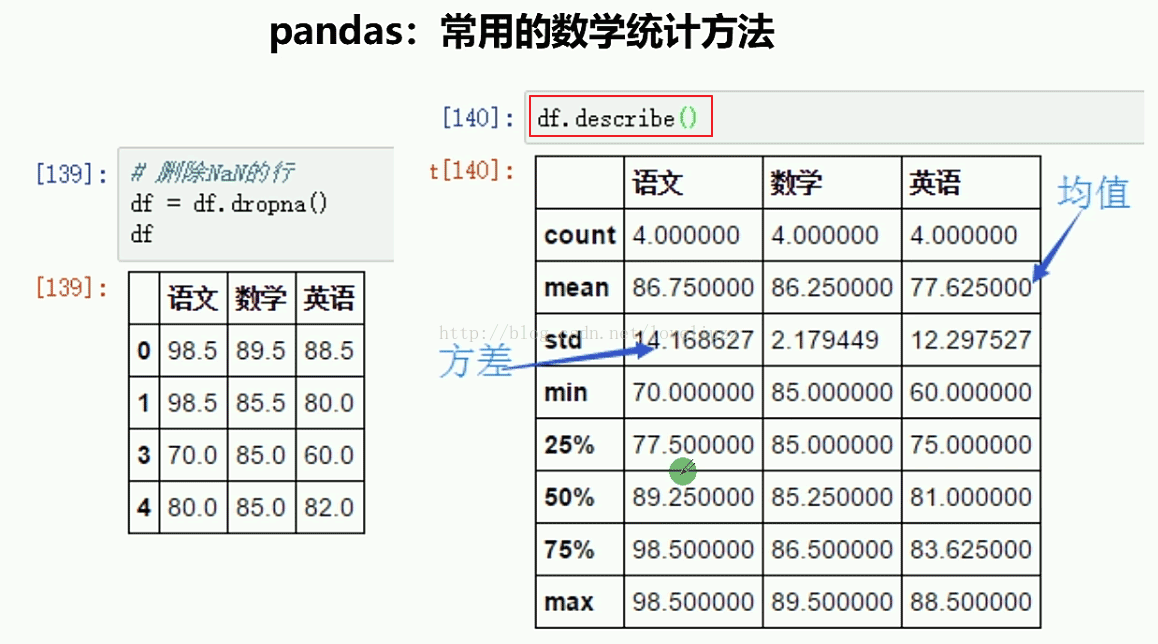
print("=======针对列计算总统计值=======")
print(df1.describe())
print("=======默认计算各列非NaN值个数=======")
print(df1.count())
print("=======计算各行非NaN值个数=======")
print(df1.count(axis=1))
运行结果:
语文 数学 英语
0 98.5 89.5 88.5
1 98.5 85.5 88.0
2 70.0 85.0 60.0
3 80.0 85.0 82.0
=======针对列计算总统计值=======
语文 数学 英语
count 4.000000 4.000000 4.000000
mean 86.750000 86.250000 79.625000
std 14.168627 2.179449 13.412525
min 70.000000 85.000000 60.000000
25% 77.500000 85.000000 76.500000
50% 89.250000 85.250000 85.000000
75% 98.500000 86.500000 88.125000
max 98.500000 89.500000 88.500000
=======默认计算各列非NaN值个数=======
语文 4
数学 4
英语 4
dtype: int64
=======计算各行非NaN值个数=======
0 3
1 3
2 3
3 3
dtype: int64


import numpy as np
import pandas as pd
from pandas import Series,DataFrame、
#2.pandas相关系数与协方差
df2 = DataFrame({
"GDP":[12,23,34,45,56],
"air_temperature":[23,25,26,27,30],
"year":["2001","2002","2003","2004","2005"]
})
print(df2)
print("=========相关系数========")
print(df2.corr())
print("=========协方差========")
print(df2.cov())
print("=========两个量之间的相关系数========")
print(df2["GDP"].corr(df2["air_temperature"]))
print("=========两个量之间协方差========")
print(df2["GDP"].cov(df2["air_temperature"]))
运行结果:
GDP air_temperature year
0 12 23 2001
1 23 25 2002
2 34 26 2003
3 45 27 2004
4 56 30 2005
=========相关系数========
GDP air_temperature
GDP 1.000000 0.977356
air_temperature 0.977356 1.000000
=========协方差========
GDP air_temperature
GDP 302.5 44.0
air_temperature 44.0 6.7
=========两个量之间的相关系数========
0.97735555485
=========两个量之间协方差========
44.0




import numpy as np
import pandas as pd
from pandas import Series,DataFrame
#3.pandas唯一值、值计数及成员资格
df3 = DataFrame({
"order_id":["1001","1002","1003","1004","1005"],
"member_id":["m01","m01","m02","m01","m02",],
"order_amt":[345,312.2,123,250.2,235]
})
print(df3)
print("=========去重后的数组=========")
print(df3["member_id"].unique())
print("=========值出现的频率=========")
print(df3["member_id"].value_counts())
print("=========成员资格=========")
df3 = df3["member_id"]
mask = df3.isin(["m01"])
print(mask)
print(df3[mask])
运行结果:
member_id order_amt order_id
0 m01 345.0 1001
1 m01 312.2 1002
2 m02 123.0 1003
3 m01 250.2 1004
4 m02 235.0 1005
=========去重后的数组=========
['m01' 'm02']
=========值出现的频率=========
m01 3
m02 2
Name: member_id, dtype: int64
=========成员资格=========
0 True
1 True
2 False
3 True
4 False
Name: member_id, dtype: bool
0 m01
1 m01
3 m01
Name: member_id, dtype: object
3、pandas层次索引



import numpy as np
import pandas as pd
from pandas import Series,DataFrame
#3.pandas层次索引
data = Series([998.4,6455,5432,9765,5432],
index=[["2001","2001","2001","2002","2002"],
["苹果","香蕉","西瓜","苹果","西瓜"]]
)
print(data)
df4 = DataFrame({
"year":[2001,2001,2002,2002,2003],
"fruit":["apple","banana","apple","banana","apple"],
"production":[2345,5632,3245,6432,4532],
"profits":[245.6,432.7,534.1,354,467.8]
})
print(df4)
print("=======层次化索引=======")
df4 = df4.set_index(["year","fruit"])
print(df4)
print("=======依照索引取值=======")
print(df4.ix[2002,"apple"])
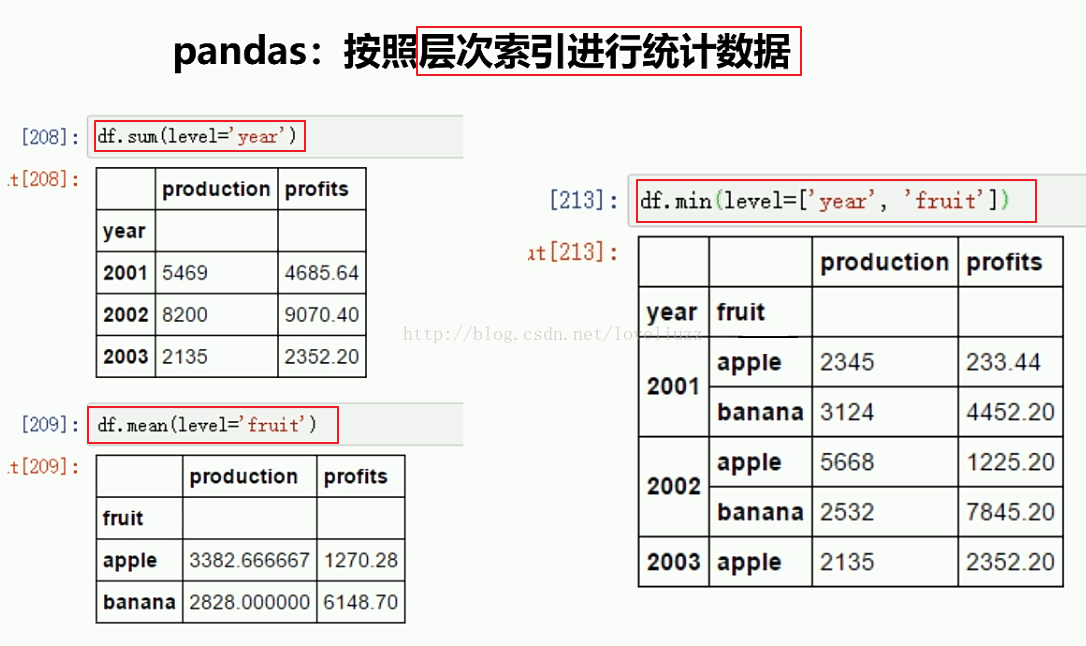
print("=======依照层次化索引统计数据=======")
print(df4.sum(level="year"))
print(df4.mean(level="fruit"))
print(df4.min(level=["year","fruit"]))
运行结果:
2001 苹果 998.4
香蕉 6455.0
西瓜 5432.0
2002 苹果 9765.0
西瓜 5432.0
dtype: float64
fruit production profits year
0 apple 2345 245.6 2001
1 banana 5632 432.7 2001
2 apple 3245 534.1 2002
3 banana 6432 354.0 2002
4 apple 4532 467.8 2003
=======层次化索引=======
production profits
year fruit
2001 apple 2345 245.6
banana 5632 432.7
2002 apple 3245 534.1
banana 6432 354.0
2003 apple 4532 467.8
=======依照索引取值=======
production 3245.0
profits 534.1
Name: (2002, apple), dtype: float64
=======依照层次化索引统计数据=======
production profits
year
2001 7977 678.3
2002 9677 888.1
2003 4532 467.8
production profits
fruit
apple 3374 415.833333
banana 6032 393.350000
production profits
year fruit
2001 apple 2345 245.6
banana 5632 432.7
2002 apple 3245 534.1
banana 6432 354.0
2003 apple 4532 467.8
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数学运算技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。
相关推荐
-
对Pandas DataFrame缺失值的查找与填充示例讲解
查看DataFrame中每一列是否存在空值: temp = data.isnull().any() #列中是否存在空值 print(type(temp)) print(temp) 结果如下,返回结果类型是Series,列中不存在空值则对应值为False: <class 'pandas.core.series.Series'> eventid False iyear False imonth False iday False approxdate True extended False reso
-
Python Pandas对缺失值的处理方法
Pandas使用这些函数处理缺失值: isnull和notnull:检测是否是空值,可用于df和series dropna:丢弃.删除缺失值 axis : 删除行还是列,{0 or 'index', 1 or 'columns'}, default 0 how : 如果等于any则任何值为空都删除,如果等于all则所有值都为空才删除 inplace : 如果为True则修改当前df,否则返回新的df fillna:填充空值 value:用于填充的值,可以是单个值,或者字典(key是列名,valu
-
pandas如何处理缺失值
在实际应用中对于数据进行分析的时候,经常能看见缺失值,下面来介绍一下如何利用pandas来处理缺失值.常见的缺失值处理方式有,过滤.填充. 一.缺失值的判断 pandas使用浮点值NaN(Not a Number)表示浮点数和非浮点数组中的缺失值,同时python内置None值也会被当作是缺失值. a.Series的缺失值判断 s = Series(["a","b",np.nan,"c",None]) print(s) ''' 0 a 1 b 2
-
python解决pandas处理缺失值为空字符串的问题
踩坑记录: 用pandas来做csv的缺失值处理时候发现奇怪BUG,就是excel打开csv文件,明明有的格子没有任何东西,当然,我就想到用pandas的dropna()或者fillna()来处理缺失值. 但是pandas读取csv文件后发现那个空的地方isnull()竟然是false,就是说那个地方有东西... 后来经过排查发现看似什么都没有的地方有空字符串,故pandas认为那儿不是缺失值,所以就不能用dropna()或者fillna()来处理. 解决思路:先用正则将空格匹配出来,然后全部替
-
Python Pandas找到缺失值的位置方法
问题描述: python pandas判断缺失值一般采用 isnull(),然而生成的却是所有数据的true/false矩阵,对于庞大的数据dataframe,很难一眼看出来哪个数据缺失,一共有多少个缺失数据,缺失数据的位置. 首先对于存在缺失值的数据,如下所示 import pandas as pd import numpy as np df = pd.DataFrame(np.random.randn(10,6)) # Make a few areas have NaN values df.
-
pandas 使用均值填充缺失值列的小技巧分享
pd.DataFrame中通常含有许多特征,有时候需要对每个含有缺失值的列,都用均值进行填充,代码实现可以这样: for column in list(df.columns[df.isnull().sum() > 0]): mean_val = df[column].mean() df[column].fillna(mean_val, inplace=True) # -------代码分解------- # 判断哪些列有缺失值,得到series对象 df.isnull().sum() > 0
-
Python3.5 Pandas模块缺失值处理和层次索引实例详解
本文实例讲述了Python3.5 Pandas模块缺失值处理和层次索引.分享给大家供大家参考,具体如下: 1.pandas缺失值处理 import numpy as np import pandas as pd from pandas import Series,DataFrame df3 = DataFrame([ ["Tom",np.nan,456.67,"M"], ["Merry",34,345.56,np.nan], [np.nan,np
-
Python3使用requests模块实现显示下载进度的方法详解
本文实例讲述了Python3使用requests模块实现显示下载进度的方法.分享给大家供大家参考,具体如下: 一.配置request 1. 相关资料 请求关键参数:stream=True.默认情况下,当你进行网络请求后,响应体会立即被下载.你可以通过 stream 参数覆盖这个行为,推迟下载响应体直到访问 Response.content 属性. tarball_url = 'https://github.com/kennethreitz/requests/tarball/master' r =
-
Python3中的列表生成式、生成器与迭代器实例详解
本文实例讲述了Python3中的列表生成式.生成器与迭代器.分享给大家供大家参考,具体如下: 列表生成式 Python内置的一种极其强大的生成列表 list 的表达式.返回结果必须是列表. 基本语法: [ 变量表达式 for 变量 in 表达式 ] 示例 a = [x ** 2 for x in range(1, 10)] b = [x * x for x in range(1, 11) if x % 2 == 0] c = [m + n for m in 'ABC' for n in '123
-
Python3.5基础之函数的定义与使用实例详解【参数、作用域、递归、重载等】
本文实例讲述了Python3.5函数的定义与使用.分享给大家供大家参考,具体如下: 1.函数学习框架 2.函数的定义与格式 (1)定义 (2)函数调用 注:函数名称不能以数字开头,建议函数名称的开头用小写的字母 (3)函数有四种格式,分别是:无参数无返回值,有参数无返回值.无参数有返回值.有参数有返回值 #!/usr/bin/env python # -*- coding:utf-8 -*- # Author:ZhengzhengLiu # 无参数无返回值 def hello(): # 函数体/
-

Python3实现打格点算法的GPU加速实例详解
目录 技术背景 打格点算法实现 打格点算法加速 总结概要 技术背景 在数学和物理学领域,总是充满了各种连续的函数模型.而当我们用现代计算机的技术去处理这些问题的时候,事实上是无法直接处理连续模型的,绝大多数的情况下都要转化成一个离散的模型再进行数值的计算.比如计算数值的积分,计算数值的二阶导数(海森矩阵)等等.这里我们所介绍的打格点的算法,正是一种典型的离散化方法.这个对空间做离散化的方法,可以在很大程度上简化运算量.比如在分子动力学模拟中,计算近邻表的时候,如果不采用打格点的方法,那么就要针对
-
Python3.5 Pandas模块之Series用法实例分析
本文实例讲述了Python3.5 Pandas模块之Series用法.分享给大家供大家参考,具体如下: 1.Pandas模块引入与基本数据结构 2.Series的创建 #!/usr/bin/env python # -*- coding:utf-8 -*- # Author:ZhengzhengLiu #模块引入 import numpy as np import pandas as pd from pandas import Series,DataFrame #1.Series通过numpy一
-
Python3使用pandas模块读写excel操作示例
本文实例讲述了Python3使用pandas模块读写excel操作.分享给大家供大家参考,具体如下: 前言 Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具,能使我们快速便捷地处理数据.本文介绍如何用pandas读写excel. 1. 读取excel 读取excel主要通过read_excel函数实现,除了pandas
-
Python3.5 Pandas模块之DataFrame用法实例分析
本文实例讲述了Python3.5 Pandas模块之DataFrame用法.分享给大家供大家参考,具体如下: 1.DataFrame的创建 (1)通过二维数组方式创建 #!/usr/bin/env python # -*- coding:utf-8 -*- # Author:ZhengzhengLiu import numpy as np import pandas as pd from pandas import Series,DataFrame #1.DataFrame通过二维数组创建 pr
-
python3 enum模块的应用实例详解
一.枚举与字典类型 字典类型的缺点: 1.值可变 2.没有防止相同标签的功能 枚举的特点: 1.枚举类的值不可以被外界更改 2.不能存在相同的标签,但允许不同标签存在相同的枚举值,即后者相当于前者的别名 3.枚举值可以是任意类型 4.枚举标签尽量用大写 from enum import Enum #普通类 class dict(): green = 1 green = 2 red = 3 dict.red = 4 print(dict.red) >>> 4 class VIP(Enum)
-
python3代码输出嵌套式对象实例详解
我们都知道如果想让电脑运行更多的程序,就要增加它的配置才能带动.在之前的学习中,我们已经对函数的打印print有所了解,但是遇到更加复杂的对象,比如嵌套式的print的打印功能就不够用了. 有的小伙伴已经在寻找其他的函数,其实针对于这个问题,我们使用更高级的pprint就可以解决了,接下来用代码输出嵌套式对象给大家进行模拟. Python的默认print函数可以满足日常的输出任务,但如果要打印更大的.嵌套式的对象,那么使用默认的print函数打印出来的内容会很丑陋. 这个时候我们就需要pprin