Python3.x爬虫下载网页图片的实例讲解
一、选取网址进行爬虫
本次我们选取pixabay图片网站
url=https://pixabay.com/

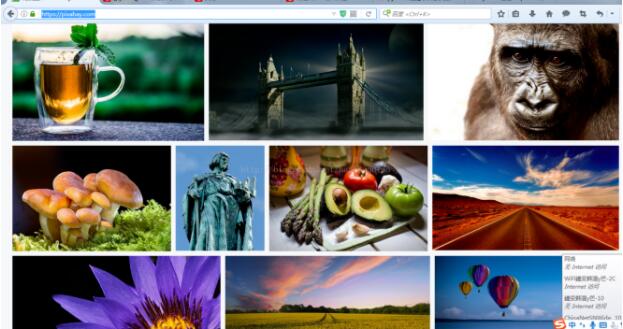
二、选择图片右键选择查看元素来寻找图片链接的规则

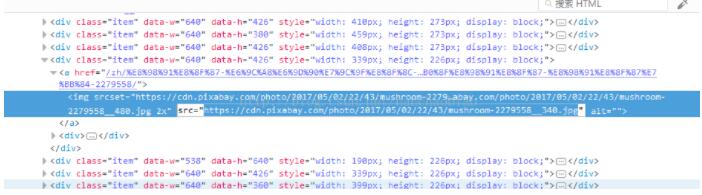
通过查看多个图片路径我们发现取src路径都含有 https://cdn.pixabay.com/photo/ 公共部分且图片格式都为.jpg 因此正则表达式为
re.compile(r'^https://cdn.pixabay.com/photo/.*?jpg$')
通过以上的分析我们可以开始写程序了
#-*- coding:utf-8 -*-
import re
import requests
import os
from bs4 import BeautifulSoup
url = 'https://pixabay.com/'
html = requests.get(url).text #获取网页内容
print(html)
# 这里由于有些图片可能存在网址打不开的情况,加个5秒超时控制。
#data-objurl="http://pic38.nipic.com/20140218/17995031_091821599000_2.jpg"获取这种类型链接
soup = BeautifulSoup(html,'html.parser',from_encoding='utf-8')
#^abc.*?qwe$
pic_url = soup.find_all('img',src=re.compile(r'^https://cdn.pixabay.com/photo/.*?jpg$'))
#pic_url = pic_node.get_text()
#pic_url = re.findall('"https://cdn.pixabay.com/photo/""(.*?)",',html,re.S)
print(pic_url)
i = 0
#判断image文件夹是否存在,不存在则创建
if not os.path.exists('image'):
os.makedirs('image')
for url in pic_url:
img = url['src']
try:
pic = requests.get(img,timeout=5) #超时异常判断 5秒超时
except requests.exceptions.ConnectionError:
print('当前图片无法下载')
continue
file_name = "image/"+str(i)+".jpg" #拼接图片名
print(file_name)
#将图片存入本地
fp = open(file_name,'wb')
fp.write(pic.content) #写入图片
fp.close()
i+=1
代码是不是很简单呢 如果你想修改地址 取爬取别的网站 请注意分析下载图片路径的共性 并设计合理的正则表达式,否则是无法获取到图片路径的
执行过程截图:

以上这篇Python3.x爬虫下载网页图片的实例讲解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 基本上按照文档的流程走一遍就基本会用了. Step1: 在开始爬取之前,必须创建一个新的Scrapy项目. 进入打算存储代码的目录中,运行下列命令: scrapy startproject CrawlMe
-

Python使用爬虫抓取美女图片并保存到本地的方法【测试可用】
本文实例讲述了Python使用爬虫抓取美女图片并保存到本地的方法.分享给大家供大家参考,具体如下: 图片资源来自于www.qiubaichengren.com 代码基于Python 3.5.2 友情提醒:血气方刚的骚年.请 谨慎阅图! 谨慎阅图!! 谨慎阅图!!! code: #!/usr/bin/env python # -*- coding: utf-8 -*- import os import urllib import urllib.request import re from urll
-
Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
Python爬取知乎图片代码实现解析
首先,需要获取任意知乎的问题,只需要你输入问题的ID,就可以获取相关的页面信息,比如最重要的合计有多少人回答问题. 问题ID为如下标红数字 编写代码,下面的代码用来检测用户输入的是否是正确的ID,并且通过拼接URL去获取该问题下面合计有多少答案. import requests import re import pymongo import time DATABASE_IP = '127.0.0.1' DATABASE_PORT = 27017 DATABASE_NAME = 'sun' cli
-
Python爬虫 12306抢票开源代码过程详解
今天就和大家一起来讨论一下python实现12306余票查询(pycharm+python3.7),一起来感受一下python爬虫的简单实践 我们说先在浏览器中打开开发者工具(F12),尝试一次余票的查询,通过开发者工具查看发出请求的包 可以看到红框框中的URL就是我们向12306服务器发出的请求,那么具体是什么呢?我们来看看 https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2019-01-21&leftT
-
Python使用爬虫爬取静态网页图片的方法详解
本文实例讲述了Python使用爬虫爬取静态网页图片的方法.分享给大家供大家参考,具体如下: 爬虫理论基础 其实爬虫没有大家想象的那么复杂,有时候也就是几行代码的事儿,千万不要把自己吓倒了.这篇就清晰地讲解一下利用Python爬虫的理论基础. 首先说明爬虫分为三个步骤,也就需要用到三个工具. ① 利用网页下载器将网页的源码等资源下载. ② 利用URL管理器管理下载下来的URL ③ 利用网页解析器解析需要的URL,进而进行匹配. 网页下载器 网页下载器常用的有两个.一个是Python自带的urlli
-
Python爬虫实现百度图片自动下载
制作爬虫的步骤 制作一个爬虫一般分以下几个步骤: 分析需求分析网页源代码,配合开发者工具编写正则表达式或者XPath表达式正式编写 python 爬虫代码 效果预览 运行效果如下: 存放图片的文件夹: 需求分析 我们的爬虫至少要实现两个功能:一是搜索图片,二是自动下载. 搜索图片:最容易想到的是爬百度图片的结果,我们就上百度图片看看: 随便搜索几个关键字,可以看到已经搜索出来很多张图片: 分析网页 我们点击右键,查看源代码: 打开源代码之后,发现一堆源代码比较难找出我们想要的资源. 这个时候,就
-
Python3.x爬虫下载网页图片的实例讲解
一.选取网址进行爬虫 本次我们选取pixabay图片网站 url=https://pixabay.com/ 二.选择图片右键选择查看元素来寻找图片链接的规则 通过查看多个图片路径我们发现取src路径都含有 https://cdn.pixabay.com/photo/ 公共部分且图片格式都为.jpg 因此正则表达式为 re.compile(r'^https://cdn.pixabay.com/photo/.*?jpg$') 通过以上的分析我们可以开始写程序了 #-*- coding:utf-8 -
-
Python3简单爬虫抓取网页图片代码实例
现在网上有很多python2写的爬虫抓取网页图片的实例,但不适用新手(新手都使用python3环境,不兼容python2), 所以我用Python3的语法写了一个简单抓取网页图片的实例,希望能够帮助到大家,并希望大家批评指正. import urllib.request import re import os import urllib #根据给定的网址来获取网页详细信息,得到的html就是网页的源代码 def getHtml(url): page = urllib.request.urlope
-
java实现爬虫爬网站图片的实例代码
第一步,实现 LinkQueue,对url进行过滤和存储的操作 import java.util.ArrayList; import java.util.Collections; import java.util.HashSet; import java.util.List; import java.util.Set; public class LinkQueue { // 已访问的 url 集合 private static Set<String> visitedUrl = Collecti
-
Python爬虫之网页图片抓取的方法
一.引入 这段时间一直在学习Python的东西,以前就听说Python爬虫多厉害,正好现在学到这里,跟着小甲鱼的Python视频写了一个爬虫程序,能实现简单的网页图片下载. 二.代码 __author__ = "JentZhang" import urllib.request import os import random import re def url_open(url): ''' 打开网页 :param url: :return: ''' req = urllib.reques
-
python3爬虫中引用Queue的实例讲解
我们去一个受欢迎的地方买东西,难免会需要排队等待.如果有多个窗口的话,就会有不同队列的产生,当然每个队伍的人数也会出现参差不齐的现象.我们今天所要说的Queue就可以理解成生活中的排队现象.那么结合我们所要用的爬虫知识,应该怎么在Queue中应用呢?接下来就开始今天的内容学习: 队列这种东西大家应该都知道,就是一个先进先出的数据结构,而Python的标准库中提供了一个线程安全的队列,也就是说该模块是适用于多线程编程的先进先出(first-in,first-out,FIFO)数据结构,可以用来在生
-
PyTorch读取Cifar数据集并显示图片的实例讲解
首先了解一下需要的几个类所在的package from torchvision import transforms, datasets as ds from torch.utils.data import DataLoader import matplotlib.pyplot as plt import numpy as np #transform = transforms.Compose是把一系列图片操作组合起来,比如减去像素均值等. #DataLoader读入的数据类型是PIL.Image
-
Python简单爬虫导出CSV文件的实例讲解
流程:模拟登录→获取Html页面→正则解析所有符合条件的行→逐一将符合条件的行的所有列存入到CSVData[]临时变量中→写入到CSV文件中 核心代码: ####写入Csv文件中 with open(self.CsvFileName, 'wb') as csvfile: spamwriter = csv.writer(csvfile, dialect='excel') #设置标题 spamwriter.writerow(["游戏账号","用户类型","游戏
-
js图片放大镜实例讲解(必看篇)
1.图片放大镜的思路: 当打开页面时只有图片 首先,说一下基本效果和调理,图片放大镜,也就是当你鼠标移入当前的商品图片时,会出现一个小灰色的观察移动框,有点会出现一个对应部位的放大的图片. 然后当鼠标移动时,右边的放大镜会出现对应部位的放大图片 最后当鼠标移开后,小的观察框和放大的图片都会消失. 2.有了基本思路就看代码 <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <ti
-
ubutu 16.04环境下,PHP与mysql数据库,网页登录验证实例讲解
正好最近的域名备案通过了,兴起就突然想做一个网页,虽然之前去备案域名也是有这个目的. 问过几个人,说用linux上用PHP搭建网站很简单,就试着做了一个,这里主要说一下登录验证相关的部分: 首相准备几个文件,主要是index.php.conn.php.data.php以及login.php; login.php 主要是登录过程中的数据对比部分:其中include ('conn.php')内容在下面有说. <?php if(!isset($_POST['submit'])){ exit('logi
-
对Python3+gdal 读取tiff格式数据的实例讲解
1.遇到的问题:numpy版本 im_data = dataset.ReadAsArray(0,0,im_width,im_height)#获取数据 这句报错 升级numpy:pip install -U numpy 但是提示已经是最新版本 解决:卸载numpy 重新安装 2.直接从压缩包中读取tiff图像 参考:http://gdal.org/gdal_virtual_file_systems.html#gdal_virtual_file_systems_vsizip 当前情况是2层压缩: /