node.js 基于cheerio的爬虫工具的实现(需要登录权限的爬虫工具)
公司有过一个需求,需要拿一个网页的的表格数据,数据量达到30w左右;为了提高工作效率。
结合自身经验和网上资料。写了一套符合自己需求的nodejs爬虫工具。也许也会适合你的。
先上代码。在做讲解
'use strict';
// 引入模块
const superagent = require('superagent');
const cheerio = require('cheerio');
const Excel = require('exceljs');
var baseUrl = '';
var Cookies = 'PHPSESSID=1c948cafb361cb5dce87122846e649cd'; //伪装的cookie
let pageDatas = [];
let count = 1;
let limit = 3;
for (count; count < limit; count++) {
baseUrl = `http://bxjd.henoo.com/policy/policyList?page=${count}`;
loadPage(baseUrl);
}
function loadPage(baseUrl) {
getPageLoad(baseUrl);
}
async function getPageLoad(baseUrl) {
try {
let body = await superagent.get(baseUrl)
.set("Cookie", Cookies)
var $ = cheerio.load(body.text);
var trList = $("#tableList").children("tr");
for (var i = 0; i < trList.length; i++) {
let item = {};
var tdArr = trList.eq(i).find("td");
var id = tdArr.eq(0).text();
item.sortId = id;
var detailUrl = `http://bxjd.henoo.com/policy/view?id=${id}`;
item.policyId = tdArr.eq(1).text();
item.policyProductName = tdArr.eq(2).text();
item.policyName = tdArr.eq(3).text();
item.policyMoney = tdArr.eq(4).text();
let detailBody = await superagent.get(detailUrl)
.set("Cookie", Cookies);
var $$ = cheerio.load(detailBody.text);
var detailT = $$(".table-view");
//投保人证件号
item.policyIdNum = detailT.find("tr").eq(11).find("td").eq(1).text();
//投保人手机号
item.policyPhone = detailT.find("tr").eq(10).find("td").eq(1).text();
//被保人手机号
item.bePoliciedPhone = detailT.find("tr").eq(16).find("td").eq(1).text();
//被保人姓名
item.bePoliciedName = detailT.find("tr").eq(13).find("td").eq(1).text();
console.log(item.bePoliciedName)
//被保人证件号
item.bePoliciedIdNum = detailT.find("tr").eq(17).find("td").eq(1).text();
pageDatas = [...pageDatas,item];
}
if (pageDatas.length / 15 == (count - 1)) {
writeXLS(pageDatas)
}
} catch (error) {
}
}
function writeXLS(pageDatas) {
const workbook = new Excel.Workbook();
const sheet = workbook.addWorksheet('My Sheet');
const reColumns=[
{header:'序号',key:'sortId'},
{header:'投保单号',key:'policyId'},
{header: '产品名称', key: 'policyProductName'},
{header: '投保人姓名', key: 'policyName' },
{header: '投保人手机号', key: 'policyPhone' },
{header: '投保人证件号', key: 'policyIdNum'},
{header: '被保人姓名', key: 'bePoliciedName' },
{header: '被保人手机号', key: 'bePoliciedPhone' },
{header: '被保人证件号', key: 'bePoliciedIdNum' },
{header:'保费',key:'policyMoney'},
];
sheet.columns = reColumns;
for(let trData of pageDatas){
sheet.addRow(trData);
}
const filename = './projects.xlsx';
workbook.xlsx.writeFile(filename)
.then(function() {
console.log('ok');
}).catch(function (error) {
console.error(error);
});
}
代码使用方式
一、npm install 相关的依赖二、代码修改
1、修改为自己的baseUrl
2、如果不需要携带cookie时将set("Cookie", Cookies)代码去掉
3、修改自己的业务代码
三、运行 node index四、部分代码说明
所有代码不过90行不到,操作了表格数据获取和单条数据详情的获取
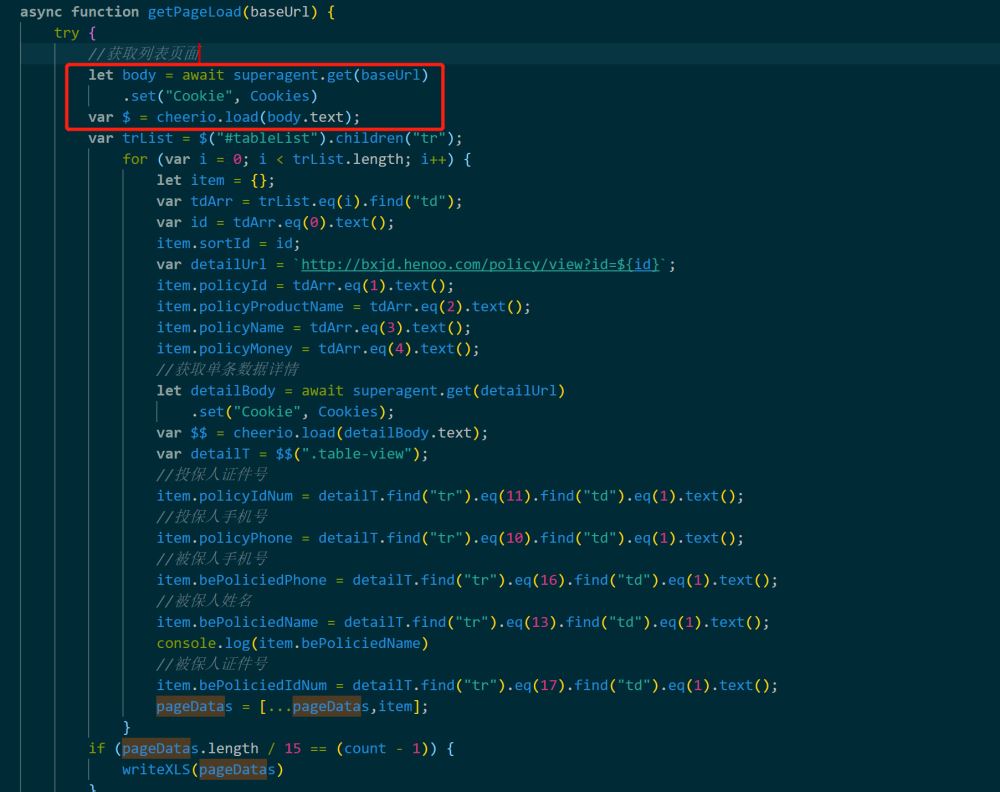
接口请求的框架使用superagent的原因是拼接伪装的cookie的操作比较简单。因为有的时候我们需要获取登录后的页面数据。
这个时候可能需要请求是携带登录cookie信息。返回后的body对象通过cheerio.load之后就能拿到一个类似jquery的文档对象。
后面就可以很方便的使用jquery的dom操作方式去拿到页面内自己想要的数据了。
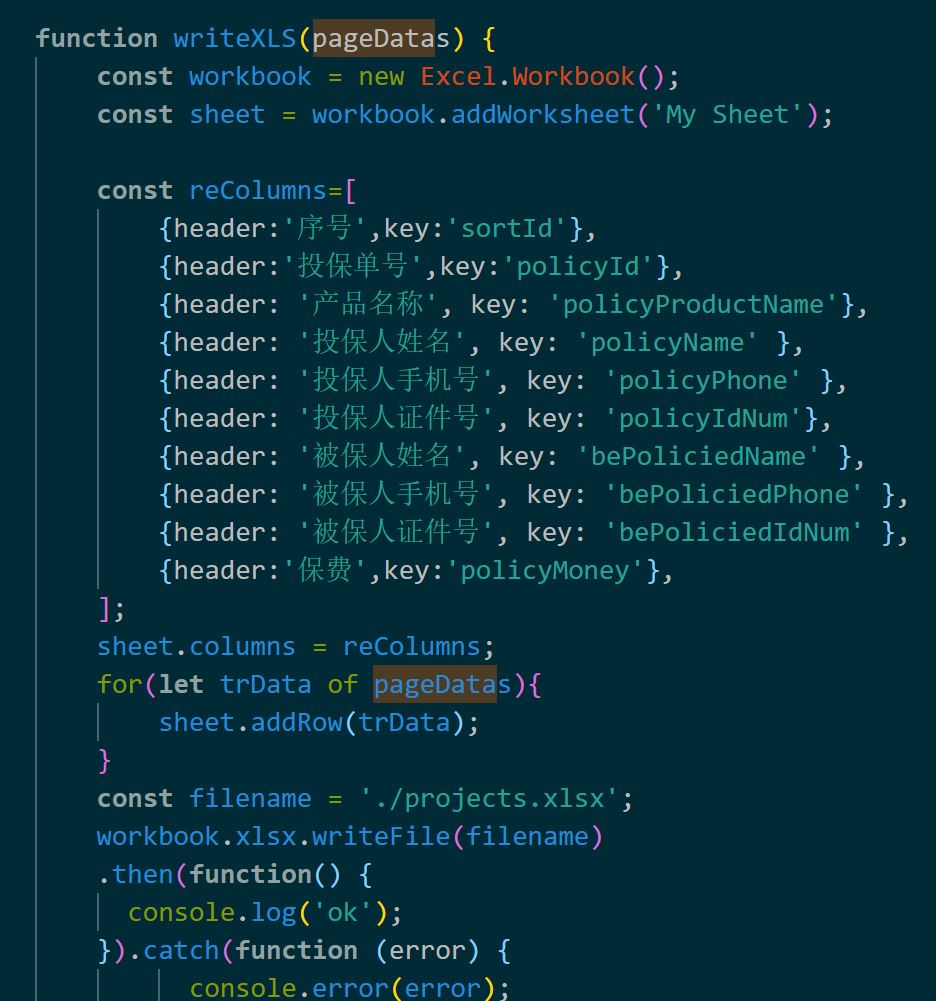
数据写入到excel中。
五、结果
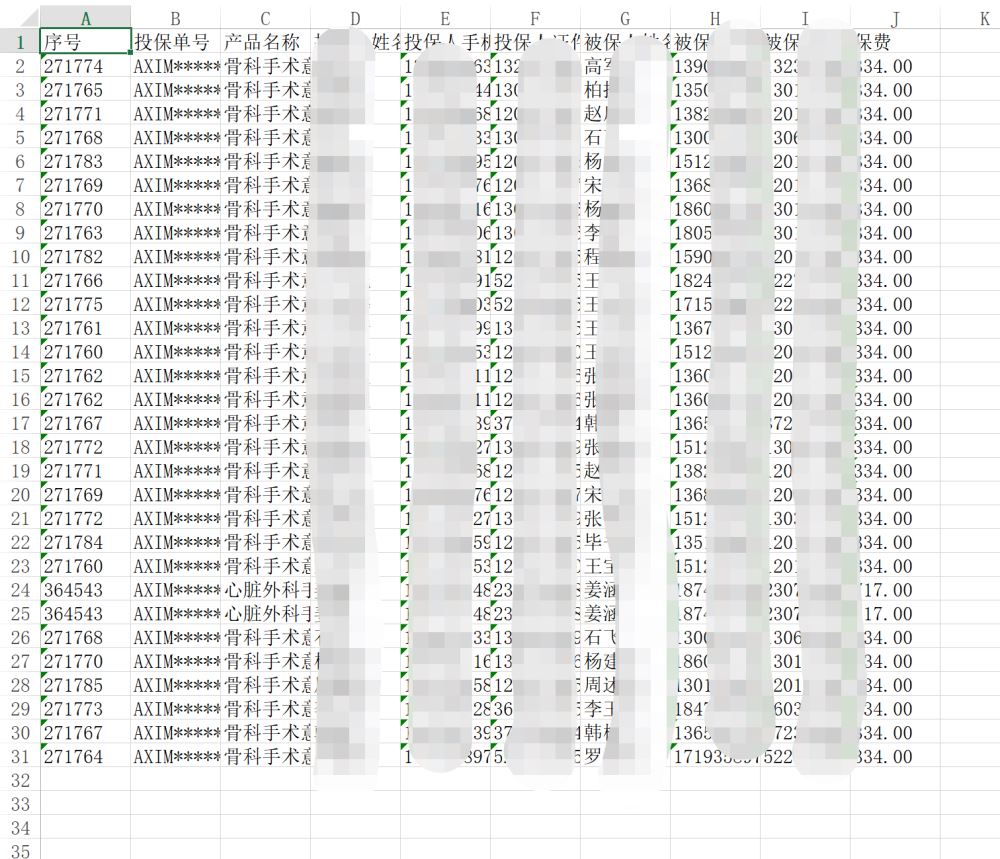
总结
相关推荐
-
node.js 基于cheerio的爬虫工具的实现(需要登录权限的爬虫工具)
公司有过一个需求,需要拿一个网页的的表格数据,数据量达到30w左右:为了提高工作效率. 结合自身经验和网上资料.写了一套符合自己需求的nodejs爬虫工具.也许也会适合你的. 先上代码.在做讲解 'use strict'; // 引入模块 const superagent = require('superagent'); const cheerio = require('cheerio'); const Excel = require('exceljs'); var baseUrl = '';
-
Node.js 利用cheerio制作简单的网页爬虫示例
本文介绍了Node.js 利用cheerio制作简单的网页爬虫示例,分享给大家,具有如下: 1. 目标 完成对网站的标题信息获取 将获取到的信息输出在一个新文件 工具: cheerio,使用npm下载npm install cheerio cheerio的API使用方法和jQuery的使用方法基本一致 如果熟练使用jQuery,那么cheerio将会很快上手 2. 代码部分 介绍: 获取segment fault页面的列表标题,将获取到的标题列表编号,最终输出到pageTitle.txt文件里
-
node.js基于express使用websocket的方法
本文实例讲述了node.js基于express使用websocket的方法.分享给大家供大家参考,具体如下: 这个效果我也是翻了好长时间的资料,测试才成功的,反正成功,大家看看吧 首先你需要安装socket.io模块 npm install socket.io --save 然后打开express的app.js将模块引入,在12行左右的 var app = express(); 下面添加两行 var server = require('http').Server(app); var io = r
-
node.js基于fs模块对系统文件及目录进行读写操作的方法详解
本文实例讲述了node.js基于fs模块对系统文件及目录进行读写操作的方法.分享给大家供大家参考,具体如下: 如果要用这个模块,首先需要引入,fs已经属于node.js自带的模块,所以直接引入即可 var fs = require('fs'); 1.读取文件readFile方法使用 fs.readFile(filename,[option],callback) 方法读取文件. 参数说明: filename String 文件名 option Object encoding String |n
-
node.js基于dgram数据报模块创建UDP服务器和客户端操作示例
本文实例讲述了node.js基于dgram数据报模块创建UDP服务器和客户端操作.分享给大家供大家参考,具体如下: node.js中 dgram 模块提供了udp数据包的socket实现,可以方便的创建udp服务器和客户端. 一.创建UDP服务器和客户端 服务端: const dgram = require('dgram'); //创建upd套接字 //参数一表示套接字类型,'udp4' 或 'udp6' //参数二表示事件监听函数,'message' 事件监听器 let server = dg
-
node.js 基于 STMP 协议和 EWS 协议发送邮件
本文主要介绍 node.js 发送基于 STMP 协议和 MS Exchange Web Service(EWS) 协议的邮件的方法.文中所有参考代码均以 TypeScript 编码示例. 1 基于 STMP 协议的 node.js 发送邮件方法 提到使用 node.js 发送邮件,基本都会提到大名鼎鼎的 Nodemailer 模块,它是当前使用 STMP 方式发送邮件的首选. 基于 NodeMailer 发送 STMP 协议邮件的文章网上已非常多,官方文档介绍也比较详细,在此仅列举示例代码以供
-

利用node.js写一个爬取知乎妹纸图的小爬虫
前言 说起写node爬虫的原因,真是羞羞呀.一天,和往常一样,晚上吃过饭便刷起知乎来,首页便是推荐的你见过最漂亮的女生长什么样?,点进去各种漂亮的妹纸爆照啊!!!,看的我好想把这些好看的妹纸照片都存下来啊!一张张点击保存,就在第18张得时候,突然想起.我特么不是程序员么,这种手动草做的事,怎么能做,不行我不能丢程序员的脸了,于是便开始这次爬虫之旅. 原理 初入爬虫的坑,没有太多深奥的理论知识,要获取知乎上帖子中的一张图片,我把它归结为以下几步. 准备一个url(当然是诸如你见过最漂亮的女生长什么
-
node.js基于socket.io快速实现一个实时通讯应用
随着web技术的发展,使用场景和需求也越来越复杂,客户端不再满足于简单的请求得到状态的需求.实时通讯越来越多应用于各个领域. HTTP是最常用的客户端与服务端的通信技术,但是HTTP通信只能由客户端发起,无法及时获取服务端的数据改变.只能依靠定期轮询来获取最新的状态.时效性无法保证,同时更多的请求也会增加服务器的负担. WebSocket技术应运而生. WebSocket概念 不同于HTTP半双工协议,WebSocket是基于TCP 连接的全双工协议,支持客户端服务端双向通信. WebSocke
-
解析Node.js基于模块和包的代码部署方式
模块路径解析规则 有经验的 C 程序员在编写一个新程序时首先从 make 文件写起.同样的,使用 NodeJS 编写程序前,为了有个良好的开端,首先需要准备好代码的目录结构和部署方式,就如同修房子要先搭脚手架.本章将介绍与之相关的各种知识. 模块路径解析规则 我们已经知道,require函数支持斜杠(/)或盘符(C:)开头的绝对路径,也支持./开头的相对路径.但这两种路径在模块之间建立了强耦合关系,一旦某个模块文件的存放位置需要变更,使用该模块的其它模块的代码也需要跟着调整,变得牵一发动全身.因
-
node.js基于mongodb的搜索分页示例
mongodb模糊查询并分页 1.建立数据库 代码如下: var mongoose = require('mongoose'); var shortid = require('shortid'); var Schema = mongoose.Schema; var IndexDataSchema = new Schema({ _id: { type: String, unique: true, 'default': shortid.generate }, type: String, city: