零基础写Java知乎爬虫之获取知乎编辑推荐内容
知乎是一个真实的网络问答社区,社区氛围友好、理性、认真,连接各行各业的精英。他们分享着彼此的专业知识、经验和见解,为中文互联网源源不断地提供高质量的信息。
首先花个三五分钟设计一个Logo=。=作为一个程序员我一直有一颗做美工的心!

好吧做的有点小凑合,就先凑合着用咯。
接下来呢,我们开始制作知乎的爬虫。
首先,确定第一个目标:编辑推荐。
网页链接:http://www.zhihu.com/explore/recommendations
我们对上次的代码稍作修改,先实现能够获取该页面内容:
import java.io.*;import java.net.*;import java.util.regex.*;public class Main { static String SendGet(String url) { // 定义一个字符串用来存储网页内容 String result = ""; // 定义一个缓冲字符输入流 BufferedReader in = null; try { // 将string转成url对象 URL realUrl = new URL(url); // 初始化一个链接到那个url的连接 URLConnection connection = realUrl.openConnection(); // 开始实际的连接 connection.connect(); // 初始化 BufferedReader输入流来读取URL的响应 in = new BufferedReader(new InputStreamReader( connection.getInputStream())); // 用来临时存储抓取到的每一行的数据 String line; while ((line = in.readLine()) != null) { // 遍历抓取到的每一行并将其存储到result里面 result += line; } } catch (Exception e) { System.out.println("发送GET请求出现异常!" + e); e.printStackTrace(); } // 使用finally来关闭输入流 finally { try { if (in != null) { in.close(); } } catch (Exception e2) { e2.printStackTrace(); } } return result; } static String RegexString(String targetStr, String patternStr) { // 定义一个样式模板,此中使用正则表达式,括号中是要抓的内容 // 相当于埋好了陷阱匹配的地方就会掉下去 Pattern pattern = Pattern.compile(patternStr); // 定义一个matcher用来做匹配 Matcher matcher = pattern.matcher(targetStr); // 如果找到了 if (matcher.find()) { // 打印出结果 return matcher.group(1); } return "Nothing"; } public static void main(String[] args) { // 定义即将访问的链接 String url = "http://www.zhihu.com/explore/recommendations"; // 访问链接并获取页面内容 String result = SendGet(url); // 使用正则匹配图片的src内容 //String imgSrc = RegexString(result, "src=\"(.+?)\""); // 打印结果 System.out.println(result); }}
运行一下木有问题,接下来就是一个正则匹配的问题了。
首先我们先来获取该页面的所有的问题。
右击标题,审查元素:
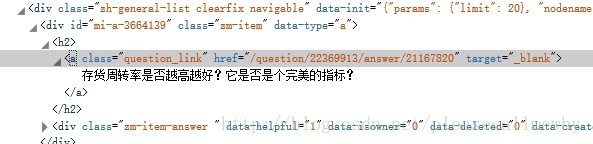
啊哈,可以看到标题其实是一个a标签,也就是一个超链接,而其中能够和其他超链接区分开的,应该就是那个class了,也就是类选择器。
于是我们的正则语句就出来了:question_link.+?href=\"(.+?)\"
调用RegexString函数,并给它传参:
public static void main(String[] args) { // 定义即将访问的链接 String url = "http://www.zhihu.com/explore/recommendations"; // 访问链接并获取页面内容 String result = SendGet(url); // 使用正则匹配图片的src内容 String imgSrc = RegexString(result, "question_link.+?>(.+?)<"); // 打印结果 System.out.println(imgSrc); }
啊哈,可以看到我们成功抓到了一个标题(注意,只是一个):

等一下啊这一大堆的乱七八糟的是什么玩意?!
别紧张=。=它只是字符乱码而已。
编码问题可以参见:HTML字符集
一般来说,对中文支持较好的主流编码是UTF-8,GB2312和GBK编码。
网页可以通过meta标签的charset来设置网页编码,譬如:
<meta charset="utf-8" />
我们右击,查看页面源代码:
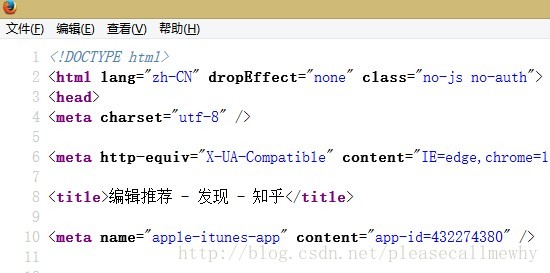
可以看到,知乎采用的是UTF-8编码。
在这里和大家解释一下查看页面源代码和审查元素的区别。
查看页面源代码是显示整个页面的所有代码,没有按照HTML的标签进行排版,相当于是直接查看源码,这种方式对于查看整个网页的信息,比如meta比较有用。
审查元素,或者有的浏览器叫查看元素,是针对你右击的元素进行查看,比如一个div或者img,比较适用于单独查看某个对象的属性和标签。
好的,我们现在知道了问题出在了编码上,接下来就是对抓取到的内容进行编码转换了。
在java中实现很简单,只需要在InputStreamReader里面指定编码方式就行:
// 初始化 BufferedReader输入流来读取URL的响应 in = new BufferedReader(new InputStreamReader( connection.getInputStream(),"UTF-8"));
此时再运行程序,便会发现可以正常显示标题了:
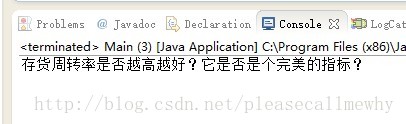
好的!非常好!
但是现在才只有一个标题,我们需要的是所有的标题。
我们将正则稍加修改,把搜索到的结果存储到一个ArrayList里面:
import java.io.*;import java.net.*;import java.util.ArrayList;import java.util.regex.*;public class Main { static String SendGet(String url) { // 定义一个字符串用来存储网页内容 String result = ""; // 定义一个缓冲字符输入流 BufferedReader in = null; try { // 将string转成url对象 URL realUrl = new URL(url); // 初始化一个链接到那个url的连接 URLConnection connection = realUrl.openConnection(); // 开始实际的连接 connection.connect(); // 初始化 BufferedReader输入流来读取URL的响应 in = new BufferedReader(new InputStreamReader( connection.getInputStream(), "UTF-8")); // 用来临时存储抓取到的每一行的数据 String line; while ((line = in.readLine()) != null) { // 遍历抓取到的每一行并将其存储到result里面 result += line; } } catch (Exception e) { System.out.println("发送GET请求出现异常!" + e); e.printStackTrace(); } // 使用finally来关闭输入流 finally { try { if (in != null) { in.close(); } } catch (Exception e2) { e2.printStackTrace(); } } return result; } static ArrayList<String> RegexString(String targetStr, String patternStr) { // 预定义一个ArrayList来存储结果 ArrayList<String> results = new ArrayList<String>(); // 定义一个样式模板,此中使用正则表达式,括号中是要抓的内容 Pattern pattern = Pattern.compile(patternStr); // 定义一个matcher用来做匹配 Matcher matcher = pattern.matcher(targetStr); // 如果找到了 boolean isFind = matcher.find(); // 使用循环将句子里所有的kelvin找出并替换再将内容加到sb里 while (isFind) { //添加成功匹配的结果 results.add(matcher.group(1)); // 继续查找下一个匹配对象 isFind = matcher.find(); } return results; } public static void main(String[] args) { // 定义即将访问的链接 String url = "http://www.zhihu.com/explore/recommendations"; // 访问链接并获取页面内容 String result = SendGet(url); // 使用正则匹配图片的src内容 ArrayList<String> imgSrc = RegexString(result, "question_link.+?>(.+?)<"); // 打印结果 System.out.println(imgSrc); }}
这样就能匹配到所有的结果了(因为直接打印了ArrayList所以会有一些中括号和逗号):

OK,这样就算是完成了知乎爬虫的第一步。
但是我们可以看出来,用这样的方式是没有办法抓到所有的问题和回答的。
我们需要设计一个Zhihu封装类,来存储所有抓取到的对象。
Zhihu.java源码:
import java.util.ArrayList;public class Zhihu { public String question;// 问题 public String zhihuUrl;// 网页链接 public ArrayList<String> answers;// 存储所有回答的数组 // 构造方法初始化数据 public Zhihu() { question = ""; zhihuUrl = ""; answers = new ArrayList<String>(); } @Override public String toString() { return "问题:" + question + "\n链接:" + zhihuUrl + "\n回答:" + answers + "\n"; }}
再新建一个Spider类来存放一些爬虫常用的函数。
Spider.java源码:
import java.io.BufferedReader;import java.io.InputStreamReader;import java.net.URL;import java.net.URLConnection;import java.util.ArrayList;import java.util.regex.Matcher;import java.util.regex.Pattern;public class Spider { static String SendGet(String url) { // 定义一个字符串用来存储网页内容 String result = ""; // 定义一个缓冲字符输入流 BufferedReader in = null; try { // 将string转成url对象 URL realUrl = new URL(url); // 初始化一个链接到那个url的连接 URLConnection connection = realUrl.openConnection(); // 开始实际的连接 connection.connect(); // 初始化 BufferedReader输入流来读取URL的响应 in = new BufferedReader(new InputStreamReader( connection.getInputStream(), "UTF-8")); // 用来临时存储抓取到的每一行的数据 String line; while ((line = in.readLine()) != null) { // 遍历抓取到的每一行并将其存储到result里面 result += line; } } catch (Exception e) { System.out.println("发送GET请求出现异常!" + e); e.printStackTrace(); } // 使用finally来关闭输入流 finally { try { if (in != null) { in.close(); } } catch (Exception e2) { e2.printStackTrace(); } } return result; } static ArrayList<Zhihu> GetZhihu(String content) { // 预定义一个ArrayList来存储结果 ArrayList<Zhihu> results = new ArrayList<Zhihu>(); // 用来匹配标题 Pattern questionPattern = Pattern.compile("question_link.+?>(.+?)<"); Matcher questionMatcher = questionPattern.matcher(content); // 用来匹配url,也就是问题的链接 Pattern urlPattern = Pattern.compile("question_link.+?href=\"(.+?)\""); Matcher urlMatcher = urlPattern.matcher(content); // 问题和链接要均能匹配到 boolean isFind = questionMatcher.find() && urlMatcher.find(); while (isFind) { // 定义一个知乎对象来存储抓取到的信息 Zhihu zhuhuTemp = new Zhihu(); zhuhuTemp.question = questionMatcher.group(1); zhuhuTemp.zhihuUrl = "http://www.zhihu.com" + urlMatcher.group(1); // 添加成功匹配的结果 results.add(zhuhuTemp); // 继续查找下一个匹配对象 isFind = questionMatcher.find() && urlMatcher.find(); } return results; }}
最后一个main方法负责调用。
import java.util.ArrayList;public class Main { public static void main(String[] args) { // 定义即将访问的链接 String url = "http://www.zhihu.com/explore/recommendations"; // 访问链接并获取页面内容 String content = Spider.SendGet(url); // 获取该页面的所有的知乎对象 ArrayList<Zhihu> myZhihu = Spider.GetZhihu(content); // 打印结果 System.out.println(myZhihu); }}
Ok这样就算搞定了。运行一下看看结果:

好的效果不错。
接下来就是访问链接然后获取到所有的答案了。
下一回我们再介绍。
好了,以上就是简单的介绍了如何使用java来抓取知乎的编辑推荐的内容的全部过程了,非常详尽,也很简单易懂,对吧,有需要的小伙伴可以参考下,自由扩展也没问题哈
相关推荐
-
JavaWeb开发之模仿知乎首页完整代码
闲来无事,就根据知乎的首页,参考了一些资料模拟写了下,包含了动态的背景,以及登录和注册功能 登录这里使用的是spring security 注册是ajax发送的 具体代码很简单,一看就知道,包含了数据的检查等 <%@ page language="java" import="java.util.*" pageEncoding="utf-8"%> <%@ taglib uri="http://java.sun.com/j
-

java实现爬取知乎用户基本信息
本文实例为大家分享了一个基于JAVA的知乎爬虫,抓取知乎用户基本信息,基于HttpClient 4.5,供大家参考,具体内容如下 详细内容: 抓取90W+用户信息(基本上活跃的用户都在里面) 大致思路: 1.首先模拟登录知乎,登录成功后将Cookie序列化到磁盘,不用以后每次都登录(如果不模拟登录,可以直接从浏览器塞入Cookie也是可以的). 2.创建两个线程池和一个Storage.一个抓取网页线程池,负责执行request请求,并返回网页内容,存到Storage中.另一个是解析网页线程池,负
-
零基础写Java知乎爬虫之准备工作
开篇我们还是和原来一样,讲一讲做爬虫的思路以及需要准备的知识吧,高手们请直接忽略. 首先我们来缕一缕思绪,想想到底要做什么,列个简单的需求. 需求如下: 1.模拟访问知乎官网(http://www.zhihu.com/) 2.下载指定的页面内容,包括:今日最热,本月最热,编辑推荐 3.下载指定分类中的所有问答,比如:投资,编程,挂科 4.下载指定回答者的所有回答 5.最好有个一键点赞的变态功能(这样我就可以一下子给雷伦的所有回答都点赞了我真是太机智了!) 那么需要解决的技术问题简单罗列如下: 1
-
零基础写Java知乎爬虫之抓取知乎答案
前期我们抓取标题是在该链接下: http://www.zhihu.com/explore/recommendations 但是显然这个页面是无法获取答案的. 一个完整问题的页面应该是这样的链接: http://www.zhihu.com/question/22355264 仔细一看,啊哈我们的封装类还需要进一步包装下,至少需要个questionDescription来存储问题描述: import java.util.ArrayList;public class Zhihu { public St
-
零基础写Java知乎爬虫之进阶篇
说到爬虫,使用Java本身自带的URLConnection可以实现一些基本的抓取页面的功能,但是对于一些比较高级的功能,比如重定向的处理,HTML标记的去除,仅仅使用URLConnection还是不够的. 在这里我们可以使用HttpClient这个第三方jar包. 接下来我们使用HttpClient简单的写一个爬去百度的Demo: import java.io.FileOutputStream;import java.io.InputStream;import java.io.OutputStr
-
零基础写Java知乎爬虫之先拿百度首页练练手
上一集中我们说到需要用Java来制作一个知乎爬虫,那么这一次,我们就来研究一下如何使用代码获取到网页的内容. 首先,没有HTML和CSS和JS和AJAX经验的建议先去W3C(点我点我)小小的了解一下. 说到HTML,这里就涉及到一个GET访问和POST访问的问题. 如果对这个方面缺乏了解可以阅读W3C的这篇:<GET对比POST>. 啊哈,在此不再赘述. 然后咧,接下来我们需要用Java来爬取一个网页的内容. 这时候,我们的百度就要派上用场了. 没错,他不再是那个默默无闻的网速测试器了,他即将
-
零基础写Java知乎爬虫之将抓取的内容存储到本地
说到Java的本地存储,肯定使用IO流进行操作. 首先,我们需要一个创建文件的函数createNewFile: 复制代码 代码如下: public static boolean createNewFile(String filePath) { boolean isSuccess = true; // 如有则将"\\"转为"/",没有则不产生任何变化 String filePathTurn = filePath.r
-
零基础写Java知乎爬虫之获取知乎编辑推荐内容
知乎是一个真实的网络问答社区,社区氛围友好.理性.认真,连接各行各业的精英.他们分享着彼此的专业知识.经验和见解,为中文互联网源源不断地提供高质量的信息. 首先花个三五分钟设计一个Logo=.=作为一个程序员我一直有一颗做美工的心! 好吧做的有点小凑合,就先凑合着用咯. 接下来呢,我们开始制作知乎的爬虫. 首先,确定第一个目标:编辑推荐. 网页链接:http://www.zhihu.com/explore/recommendations 我们对上次的代码稍作修改,先实现能够获取该页面内容: im
-
零基础学Java:Java开发工具 Eclipse 安装过程创建第一个Java项目及Eclipse的一些基础使用技巧
一.下载https://www.eclipse.org/downloads/download.php?file=/oomph/epp/2020-06/R/eclipse-inst-win64.exe&mirror_id=1142 二.安装Eclipse 三.开始使用Eclipse,并创建第一个Java项目 src 鼠标右键 -- New --Class 四.一些基础操作 1.字体大小修改(咋一看感觉这字体太小了,看起来不舒服) Window -- Preferences 2.项目运行 3.当一些
-
零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便.使用Scrapy可以很方便的完成网上数据的采集工作,它为我们完成了大量的工作,而不需要自己费大力气去开发. 首先先要回答一个问题. 问:把网站装进爬虫里,总共分几步? 答案很简单,四步: 新建项目 (Project):新建一个新的爬虫项目 明确目标(Item
-
零基础写python爬虫之神器正则表达式
接下来准备用糗百做一个爬虫的小例子. 但是在这之前,先详细的整理一下Python中的正则表达式的相关内容. 正则表达式在Python爬虫中的作用就像是老师点名时用的花名册一样,是必不可少的神兵利器. 一. 正则表达式基础 1.1.概念介绍 正则表达式是用于处理字符串的强大工具,它并不是Python的一部分. 其他编程语言中也有正则表达式的概念,区别只在于不同的编程语言实现支持的语法数量不同. 它拥有自己独特的语法以及一个独立的处理引擎,在提供了正则表达式的语言里,正则表达式的语法都是一样的. 下
-
零基础写python爬虫之抓取百度贴吧并存储到本地txt文件改进版
百度贴吧的爬虫制作和糗百的爬虫制作原理基本相同,都是通过查看源码扣出关键数据,然后将其存储到本地txt文件. 项目内容: 用Python写的百度贴吧的网络爬虫. 使用方法: 新建一个BugBaidu.py文件,然后将代码复制到里面后,双击运行. 程序功能: 将贴吧中楼主发布的内容打包txt存储到本地. 原理解释: 首先,先浏览一下某一条贴吧,点击只看楼主并点击第二页之后url发生了一点变化,变成了: http://tieba.baidu.com/p/2296712428?see_lz=1&pn=