springboot 注解方式批量插入数据的实现
目录
- 一.使用场景
- 二.实现方法
- 1.mysql表结构
- 2.domain
- 3.mapper
- 4.测试类
- 5.测试结果
- 三.插入效率对比
- 1.批量插入
- 2.一条一条插入
一.使用场景
一次请求需要往数据库插入多条数据时,可以节省大量时间,mysql操作在连接和断开时的开销超过本次操作总开销的40%。
二.实现方法
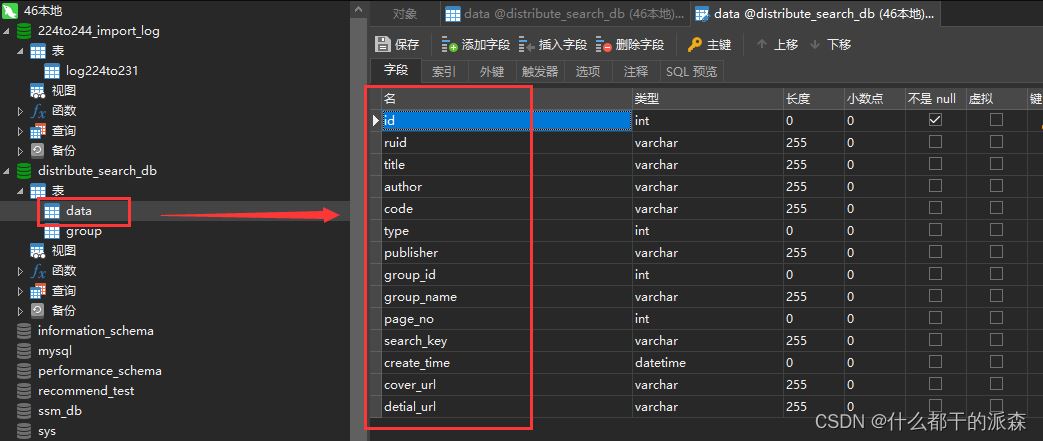
1.mysql表结构
2.domain
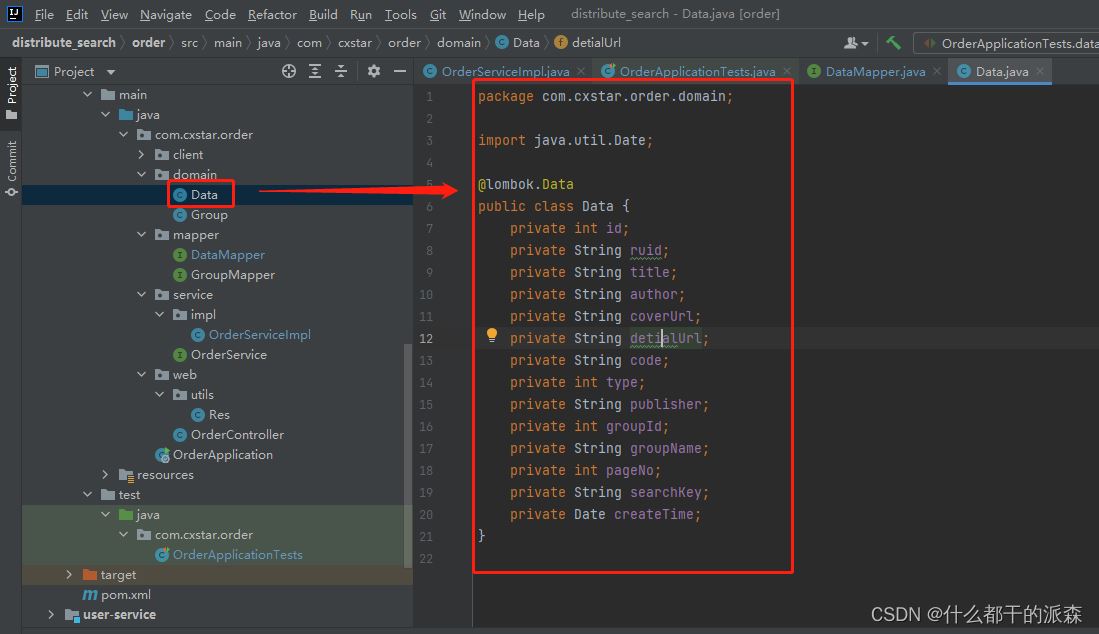
package com.cxstar.order.domain;
import java.util.Date;
@lombok.Data
public class Data {
private int id;
private String ruid;
private String title;
private String author;
private String coverUrl;
private String detialUrl;
private String code;
private int type;
private String publisher;
private int groupId;
private String groupName;
private int pageNo;
private String searchKey;
private Date createTime;
}
3.mapper
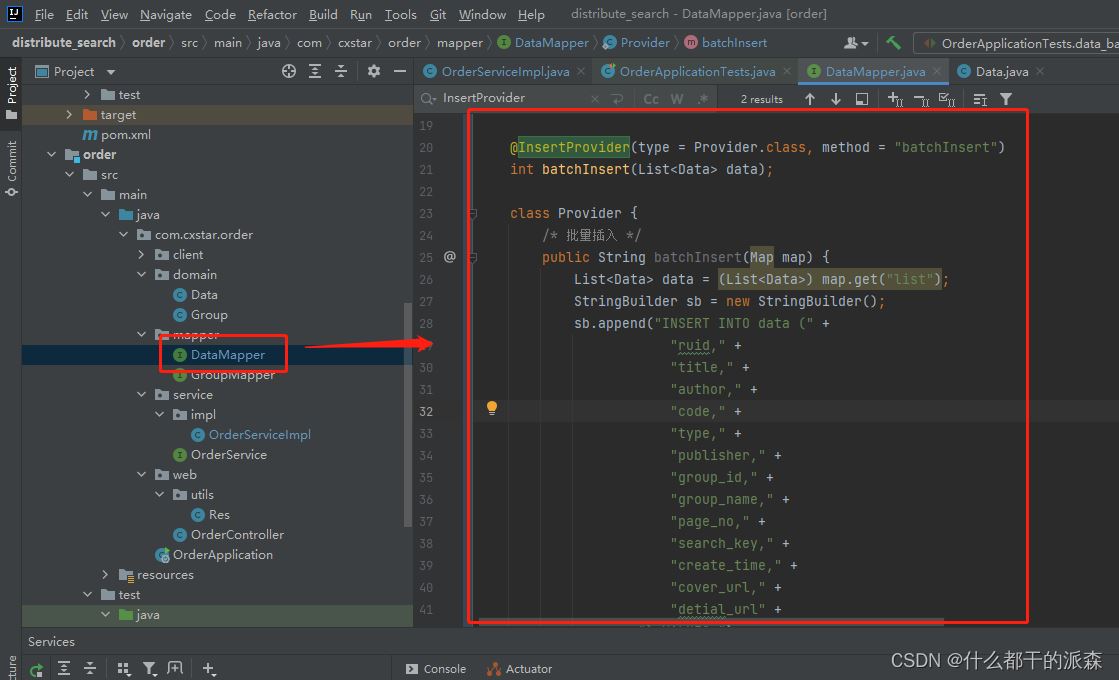
package com.cxstar.order.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.cxstar.order.domain.Data;
import org.apache.ibatis.annotations.InsertProvider;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;
import java.text.MessageFormat;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@Mapper
public interface DataMapper extends BaseMapper<Data> {
@InsertProvider(type = Provider.class, method = "batchInsert")
int batchInsert(List<Data> data);
class Provider {
/* 批量插入 */
public String batchInsert(Map map) {
List<Data> data = (List<Data>) map.get("list");
StringBuilder sb = new StringBuilder();
sb.append("INSERT INTO data (" +
"ruid," +
"title," +
"author," +
"code," +
"type," +
"publisher," +
"group_id," +
"group_name," +
"page_no," +
"search_key," +
"create_time," +
"cover_url," +
"detial_url" +
") VALUES ");
MessageFormat mf = new MessageFormat(
"(" +
"#'{'list[{0}].ruid}, " +
"#'{'list[{0}].title}, " +
"#'{'list[{0}].author}, " +
"#'{'list[{0}].code}, " +
"#'{'list[{0}].type}, " +
"#'{'list[{0}].publisher}, " +
"#'{'list[{0}].groupId}, " +
"#'{'list[{0}].groupName}, " +
"#'{'list[{0}].pageNo}, " +
"#'{'list[{0}].searchKey}, " +
"#'{'list[{0}].createTime}, " +
"#'{'list[{0}].coverUrl}, " +
"#'{'list[{0}].detialUrl}" +
")"
);
for (int i = 0; i < data.size(); i++) {
sb.append(mf.format(new Object[] {i}));
if (i < data.size() - 1)
sb.append(",");
}
return sb.toString();
}
}
}
4.测试类
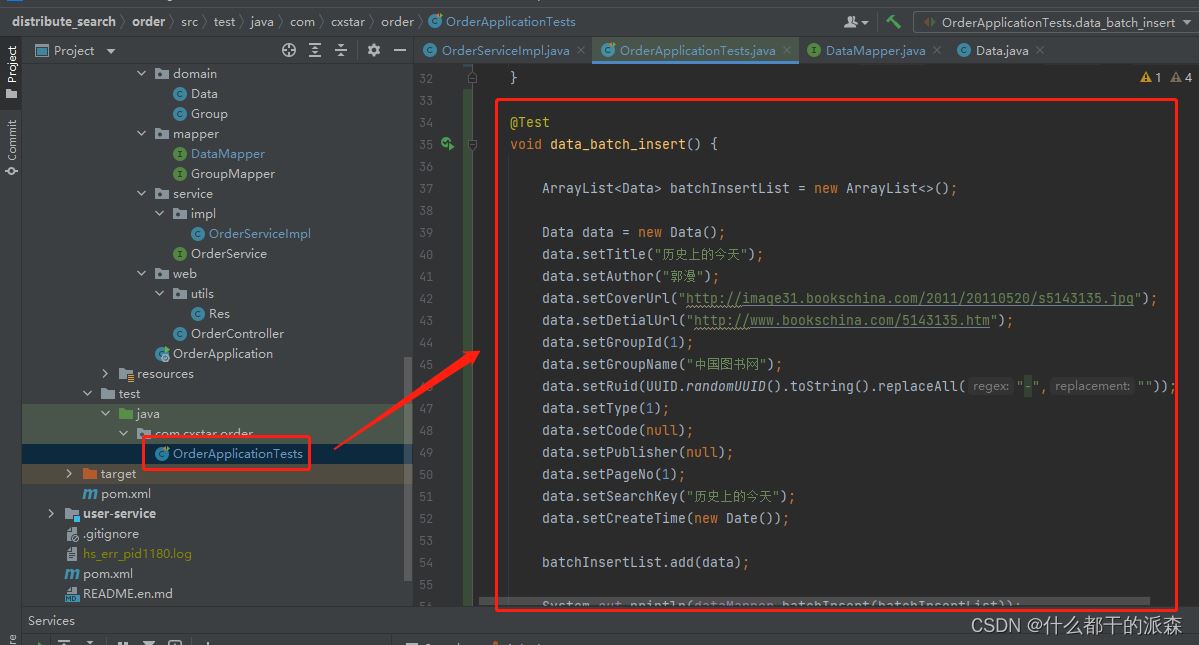
package com.cxstar.order;
import com.alibaba.fastjson.JSONObject;
import com.cxstar.order.domain.Data;
import com.cxstar.order.mapper.DataMapper;
//import com.cxstar.order.service.OrderService;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.ArrayList;
import java.util.Date;
import java.util.UUID;
@SpringBootTest
class OrderApplicationTests {
@Autowired
DataMapper dataMapper;
@Test
void data_batch_insert() {
ArrayList<Data> batchInsertList = new ArrayList<>();
Data data = new Data();
data.setTitle("历史上的今天");
data.setAuthor("郭漫");
data.setCoverUrl("http://image31.bookschina.com/2011/20110520/s5143135.jpg");
data.setDetialUrl("http://www.bookschina.com/5143135.htm");
data.setGroupId(1);
data.setGroupName("中国图书网");
data.setRuid(UUID.randomUUID().toString().replaceAll("-",""));
data.setType(1);
data.setCode(null);
data.setPublisher(null);
data.setPageNo(1);
data.setSearchKey("历史上的今天");
data.setCreateTime(new Date());
batchInsertList.add(data);
System.out.println(dataMapper.batchInsert(batchInsertList));
}
}
5.测试结果

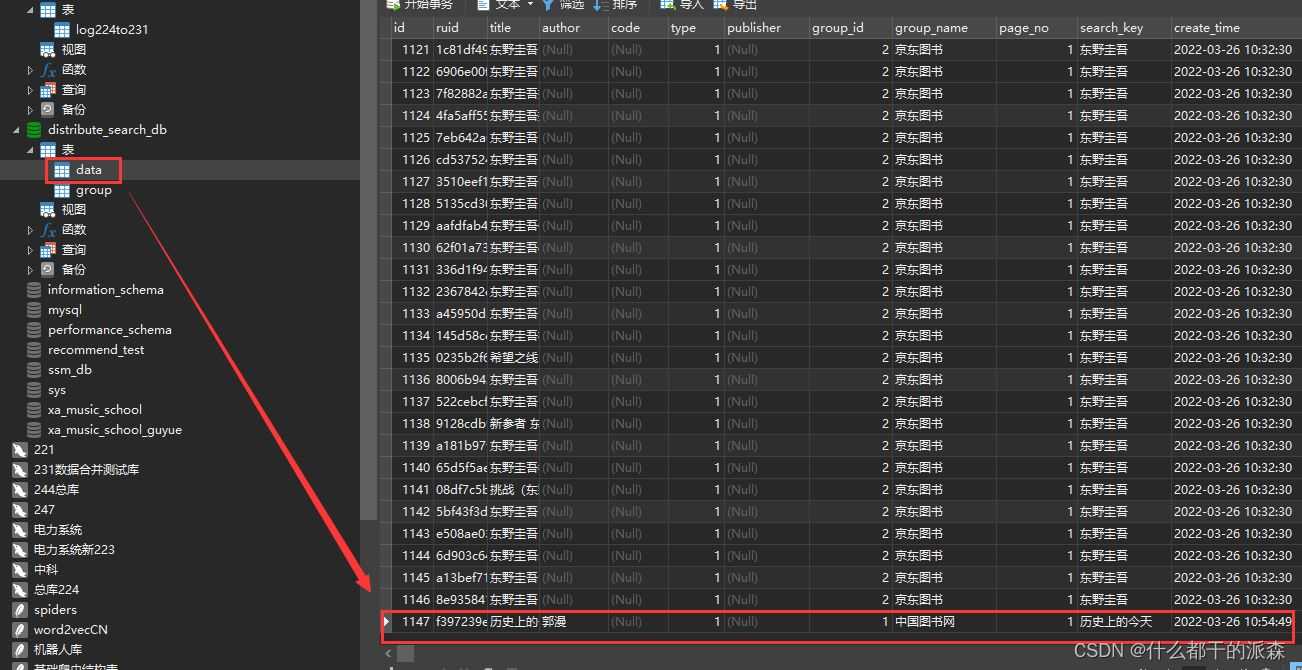
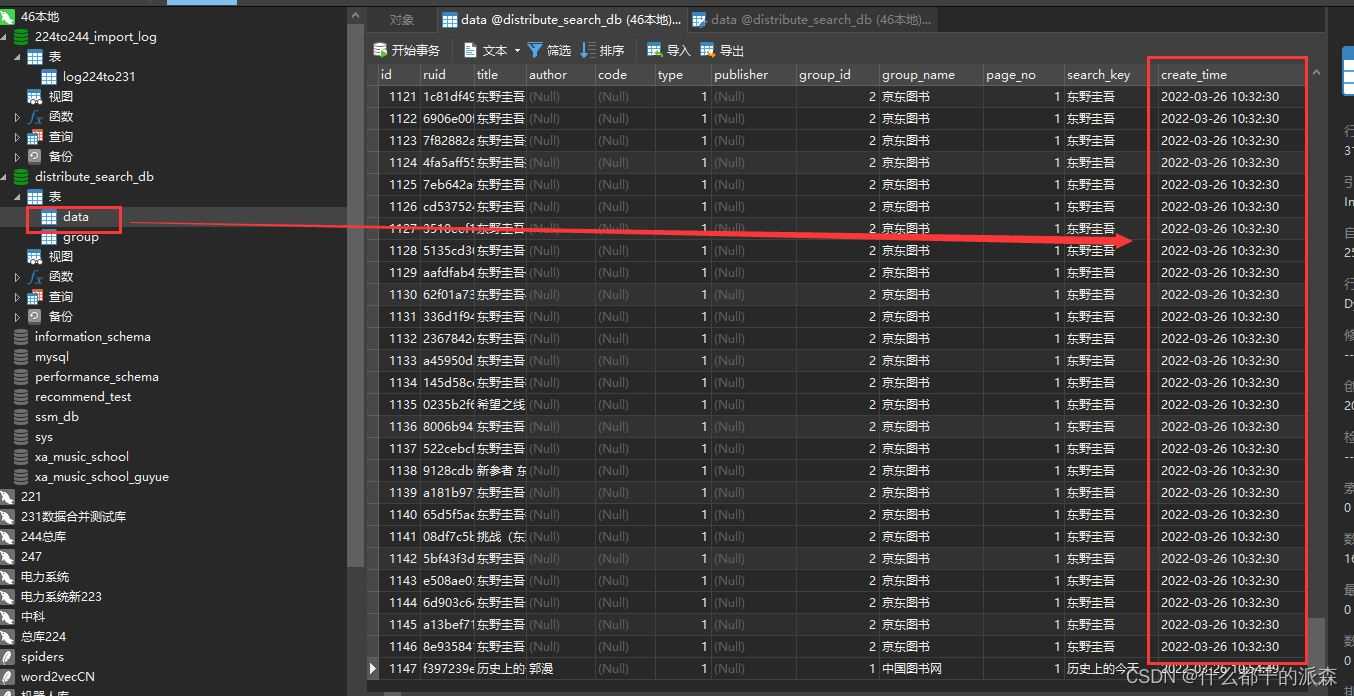
三.插入效率对比
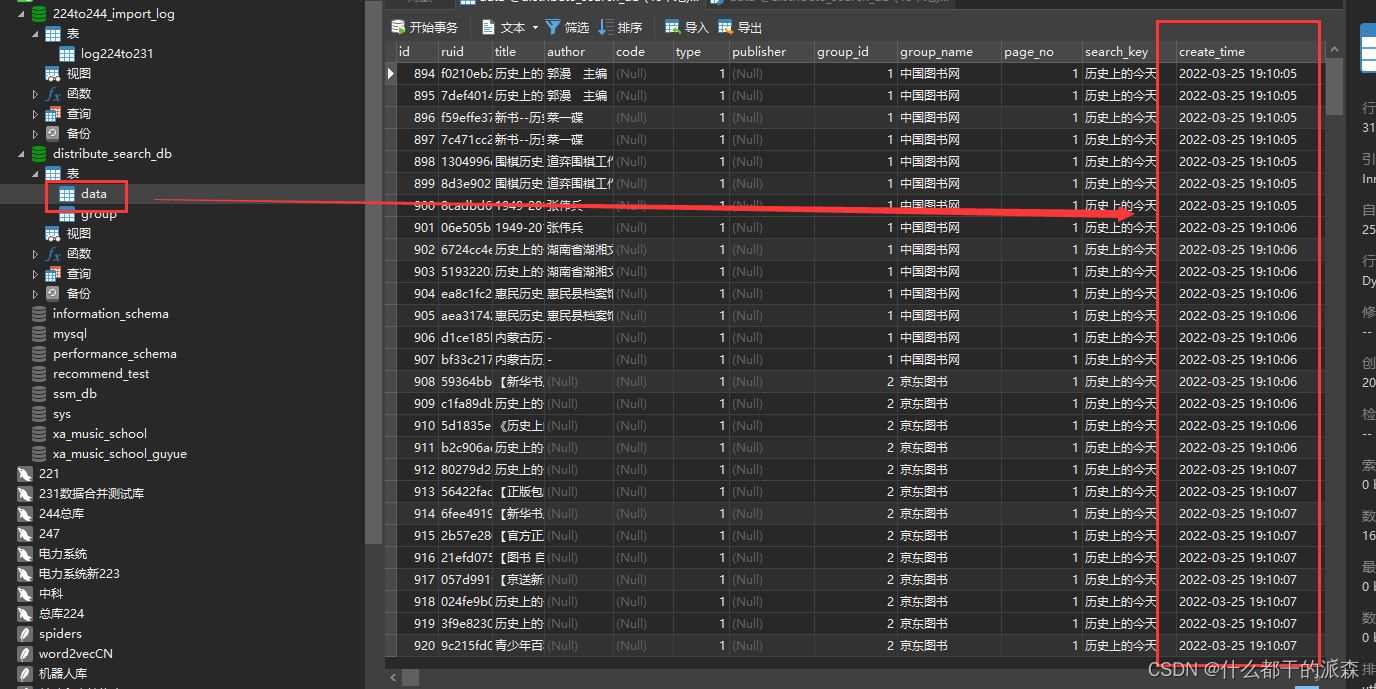
1.批量插入
2.一条一条插入
到此这篇关于springboot 注解方式批量插入数据的文章就介绍到这了,更多相关springboot 注解方式批量插入数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
SpringBoot JdbcTemplate批量操作的示例代码
前言 在我们做后端服务Dao层开发,特别是大数据批量插入的时候,这时候普通的ORM框架(Mybatis.hibernate.JPA)就无法满足程序对性能的要求了.当然我们又不可能使用原生的JDBC进行操作,那样尽管效率会高,但是复杂度会上升. 综合考虑我们使用Spring中的JdbcTemplate和具名参数namedParameterJdbcTemplate来进行批量操作. 改造前 在开始讲解之前,我们首先来看下之前的JPA是如何批量操作的. 实体类User: public class App
-

SpringBoot+SpringBatch+Quartz整合定时批量任务方式
目录 一.引言 二.代码具体实现 1.pom文件 2.application.yaml文件 3.Service实现类 4.SpringBatch配置类 5.Processor,处理每条数据 6.封装数据库返回数据的实体Bean 7.启动类上要加上注解 三.小结一下 spring-batch与quartz集成过程中遇到的问题 问题 原因 解决 一.引言 最近一周,被借调到其他部门,赶一个紧急需求,需求内容如下: PC网页触发一条设备升级记录(下图),后台要定时批量设备更新.这里定时要用到Quart
-
SpringBoot Redis批量存取数据的操作
SpringBoot Redis批量存取数据 springboot中的redisTemplate封装了redis批处理数据的接口,我们使用redisTemplate可以直接进行批量数据的get和set. package com.huateng.applacation.service; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.beans.factory.ann
-
SpringBoot2 Jpa 批量删除功能的实现
前台处理 首先前台先要获取所有的要删除数据的ID,并将ID拼接成字符串 例如: 2,3,4,5,然后通过GET请求返送到后台. 后台处理 控制器接收 /** * @function 批量删除 * @param stu_id * @return */ @GetMapping("/del_stu") @ResponseBody public Msg batch_del_stu(@RequestParam("stu_id") String stu_id){ // 接收包含
-
Spring Boot实战解决高并发数据入库之 Redis 缓存+MySQL 批量入库问题
目录 前言 架构设计 代码实现 测试 总结 前言 最近在做阅读类的业务,需要记录用户的PV,UV: 项目状况:前期尝试业务阶段: 特点: 快速实现(不需要做太重,满足初期推广运营即可)快速投入市场去运营 收集用户的原始数据,三要素: 谁在什么时间阅读哪篇文章 提到PV,UV脑海中首先浮现特点: 需要考虑性能(每个客户每打开一篇文章进行记录)允许数据有较小误差(少部分数据丢失) 架构设计 架构图: 时序图 记录基础数据MySQL表结构 CREATE TABLE `zh_article_count`
-
springboot+spring data jpa实现新增及批量新增方式
目录 springboot+spring data jpa实现新增及批量新增 springdatajpa 新增操作注意 springboot+spring data jpa实现新增及批量新增 spring data jpa (以下简称jpa).这个orm其实和mybatis还是差不多的.但是相对于mybatis来说,省去很多方法,毕竟jpa来说,官方文档给的说法是编写者只需要书写接口.剩下的事就交由jpa来完成.当时,洒家还是不信的.当你用过一次后,你就会发现.真的是这样.只能用两个字来形容,即
-
springboot 2.x整合mybatis实现增删查和批量处理方式
目录 springboot 2.x整合mybatis实现增删查和批量处理 1.添加依赖 2.添加配置文件 3.Application.class添加扫描 4.创建Mapper 5.创建provider实现类 Springboot整合mybatis(注解而且能看明白版本) 1.环境配置 2.整合Mybatis springboot 2.x整合mybatis实现增删查和批量处理 话不多说,直接上代码: 1.添加依赖 <!--mybatis数据库整合--> <dependency> &l
-
SpringBoot实现Excel文件批量上传导入数据库
Spring boot + Spring data jpa + Thymeleaf 批量插入 + POI读取 + 文件上传 pom.xml: <!-- https://mvnrepository.com/artifact/org.apache.poi/poi --> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <versi
-
springboot 注解方式批量插入数据的实现
目录 一.使用场景 二.实现方法 1.mysql表结构 2.domain 3.mapper 4.测试类 5.测试结果 三.插入效率对比 1.批量插入 2.一条一条插入 一.使用场景 一次请求需要往数据库插入多条数据时,可以节省大量时间,mysql操作在连接和断开时的开销超过本次操作总开销的40%. 二.实现方法 1.mysql表结构 2.domain package com.cxstar.order.domain; import java.util.Date; @lombok.Data publ
-
MyBatis批量插入数据到Oracle数据库中的两种方式(实例代码)
一.mybatis批量插入数据到Oracle中的两种方式: 第一种: <insert id="addList" parameterType="java.util.List" useGeneratedKeys="false"> INSERT ALL <foreach item="item" index="index" collection="list"> INTO
-
C#批量插入数据到Sqlserver中的三种方式
本篇,我将来讲解一下在Sqlserver中批量插入数据. 先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的是GUID,表中没有创建任何索引.GUID必然是比自增长要快的,因为你生成一个GUID算法所花的时间肯定比你从数据表中重新查询上一条记录的ID的值然后再进行加1运算要少.而如果存在索引的情况下,每次插入记录都会进行索引重建,这是非常耗性能的.如果表中无可避免的存在索引,我们可以通过先删除索引,然后批量插入,最后再重建索引的方式来提高效率. create database C
-
详解C#批量插入数据到Sqlserver中的四种方式
本篇,我将来讲解一下在Sqlserver中批量插入数据. 先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的是GUID,表中没有创建任何索引.GUID必然是比自增长要快的,因为你生成一个GUID算法所花的时间肯定比你从数据表中重新查询上一条记录的ID的值然后再进行加1运算要少.而如果存在索引的情况下,每次插入记录都会进行索引重建,这是非常耗性能的.如果表中无可避免的存在索引,我们可以通过先删除索引,然后批量插入,最后再重建索引的方式来提高效率. create database C
-
Oracle批量插入数据的三种方式【推荐】
第一种: begin insert into tableName(column1, column2, column3...) values(value1,value2,value3...); insert into tableName(column1, column2, column3...) values(value1,value2,value3...); insert into tableName(column1, column2, column3...) values(value1,val
-
SQLServer批量插入数据的三种方式及性能对比
昨天下午快下班的时候,无意中听到公司两位同事在探讨批量向数据库插入数据的性能优化问题,顿时来了兴趣,把自己的想法向两位同事说了一下,于是有了本文. 公司技术背景:数据库访问类(xxx.DataBase.Dll)调用存储过程实现数据库的访问. 技术方案一: 压缩时间下程序员写出的第一个版本,仅仅为了完成任务,没有从程序上做任何优化,实现方式是利用数据库访问类调用存储过程,利用循环逐条插入.很明显,这种方式效率并不高,于是有了前面的两位同事讨论效率低的问题. 技术方案二: 由于是考虑到大数据量的批量
-
Springboot 手动分页查询分批批量插入数据的实现流程
目录 前言 业务场景是什么? 正文 前言 业务场景是什么? 就是数据库的一批数据,量不少,需要执行同步插入到别的地方. 简单点肯定是一次性查出来,然后循环一个个插入,完事. 考虑点: ① 数据量大,一次性查出来操作,很爆炸. ② 循环里面一次一次地去插入,如果非业务场景必要,基本是不会在循环里面使用sql操作的. 所以该篇作为抛砖引玉(还有很多需要考虑的点),给出一种解决上面场景的代码编写方案, 手动分页,查询后批量插入. 正文 实现的流程简图: 看看最终实现的效果,通过代码日志记录了这个实现后
-
Java实现mybatis批量插入数据到Oracle
最近项目中遇到一个问题:导入数据到后台并将数据插入到数据库中,导入的数据量有上万条数据,考虑采用批量插入数据的方式: 结合网上资料,写了个小demo,文章末尾附上demo下载地址 1.新建项目:项目目录结构如下图所示,添加相应的jar包 2.新建数据库表:ACCOUNT_INFO CREATE TABLE ACCOUNT_INFO ( "ID" NUMBER(12) NOT NULL , "USERNAME" VARCHAR2(64 BYTE) NULL , &q
-
MYSQL开发性能研究之批量插入数据的优化方法
一.我们遇到了什么问题 在标准SQL里面,我们通常会写下如下的SQL insert语句. INSERT INTO TBL_TEST (id) VALUES(1); 很显然,在MYSQL中,这样的方式也是可行的.但是当我们需要批量插入数据的时候,这样的语句却会出现性能问题.例如说,如果有需要插入100000条数据,那么就需要有100000条insert语句,每一句都需要提交到关系引擎那里去解析,优化,然后才能够到达存储引擎做真的插入工作. 正是由于性能的瓶颈问题,MYSQL官方文档也就提到了使用批
-
Django 批量插入数据的实现方法
项目需求:浏览器中访问django后端某一条url(如:127.0.0.1:8080/get_book/),实时朝数据库中生成一千条数据并将生成的数据查询出来,并展示到前端页面 views.py from django.shortcuts import render, HttpResponse, redirect from app01 import models def get_book(request): # for循环插入1000条数据 for i in range(1000): model