mysql查询结果实现多列拼接查询
之前遇到过一个问题,mysql数据库中有两个表,一张地址表存放省市区等位置信息,另一张用户表里存在三个字段分别对应地址表中的三个位置信息(很奇怪的表格式),如图:
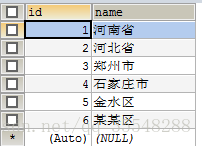
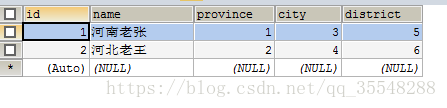
现在需要查询user表中的数据,并根据user表中省市区的值,在地址表中查询到对应的位置信息(name)并显示出来;
本人对sql并不精通,所以捋了一个大致逻辑
首先要得到user表的省市区三个字段的值,我们一般的查询方式是
SELECT province,city,district FROM `user` WHERE id =1;
这个比较简单,得到的结果为一行三列的值,如图:
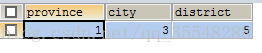
这是正常的写法,之后使用这个结果为查询条件,去查询地址表中的name即可.
当然想法似乎不错,但这个查询出来的结果是分为三段的,并不利于我们后面的查询,总不能取出结果后再进行处理再查询吧,这样太麻烦了,这时候要用到sql的两个函数,CONCAT_WS和CONCAT,两个函数的作用是将结果拼接为一个字符串,具体的用法可以自行百度.这里就不多做介绍了:)
所以我们的查询语句就可以写成SELECT CONCAT_WS(',',province,city,district) AS ids FROM `user` WHERE id =1;得到的结果如图:
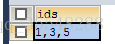
有了这个结果我们基本上可以去查询到地址信息了,同样的在查询地址信息的时候我们也做了相应的拼接,所以最终的sql是这样的
SELECT GROUP_CONCAT(`name`) FROM address WHERE id IN (SELECT CONCAT_WS(',',province,city,district) FROM `user` WHERE id =1);
理想中的结果如图:
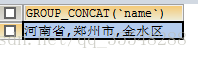
但实际上,这个语句并不能得到我们想要的结果,原因是SELECT CONCAT_WS(',',province,city,district) FROM `user` WHERE id =1查询出的结果是一个字符串,而字符串却不能作为查询条件中In的条件来使用,所以查询的结果并不是我们想要的.
再分析下我们的思路并没有问题,那么怎么才能用这个字符串作为查询条件,并最终得出我们想要的结果呢?根据网上的资料得知,查询条件in的内容只能是数字型的,所以他并不支持字符串的查询,所以这里我们还需要一个函数,instr.说实话这也是我第一次知道这个函数,毕竟对mysql真的只是会一点增删改查的皮毛,哈哈.那么接下来我们来试试这个函数的效果,最终的sql为
SELECT
GROUP_CONCAT(`name`)
FROM
address
WHERE INSTR(
(SELECT
CONCAT_WS(',', province, city, district)
FROM
`user`
WHERE id = 1),
id
) ;
执行后的结果也是我们想要的.当然上边的语句只是实现了查找到地址的结果,具体的可以根据业务需求继续修改,mysql的函数不得不说确实很强大.今后还是要多学习才是;
另:instr函数的使用有很大的局限性,详情可参考:https://www.jb51.net/article/243316.htm
所以,最终的sql为:
SELECT
GROUP_CONCAT(`name`)
FROM
address
WHERE INSTR(
CONCAT(
',',
(SELECT
CONCAT_WS(',', province, city, district)
FROM
`user`
WHERE id = 1),
','
),
CONCAT(',', id, ',')
) ;
到此这篇关于mysql查询结果实现多列拼接查询的文章就介绍到这了,更多相关mysql 多列拼接查询内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
mysql函数拼接查询concat函数的使用方法
如下所示: //查询表managefee_managefee的年year 和 month ,用concat函数拼成year-month.例如将2017和1 拼成2017-01.. select CONCAT(a.year,'-',if(a.month<=9,CONCAT('0',a.month),a.month))as date,a.* from managefee_managefee as a; //查询managefee_managefee中时间段为2017-01到2017-07的数据 se
-
MySql逗号拼接字符串查询的两种方法
下面两个函数的使用和FIND_IN_SET一样,使用时只需要把FIND_IN_SET换成FIND_PART_IN_SET或FIND_ALL_PART_IN_SET 例如某字段里是为1,2,3,4,5 使用方法: 第一种,传入1,3,6 可以查出来 select * from XXX where FIND_PART_IN_SET('1,3,6','1,2,3,4,5') 第二种,传入1,3,6 查不出来 select * from XXX where FIND_ALL_PART_IN_SET(
-
PHP将MySQL的查询结果转换为数组并用where拼接的示例
mysql查询结果转换为PHP数组的几种方法的区别: $result = mysql_fetch_row():这个函数返回的是数组,数组是以数字作为下标的,你只能通过$result[0],$Result[2]这样的形式来引用. $result = mysql_fetch_assoc():这个函数返回是以字段名为下标的数组,只能通过字段名来引用.$result['field1']. $result = mysql_fetch_array():这个函数返回的是一个混合的数组,既可以通过数字下标来引
-

mysql查询结果实现多列拼接查询
之前遇到过一个问题,mysql数据库中有两个表,一张地址表存放省市区等位置信息,另一张用户表里存在三个字段分别对应地址表中的三个位置信息(很奇怪的表格式),如图: 现在需要查询user表中的数据,并根据user表中省市区的值,在地址表中查询到对应的位置信息(name)并显示出来; 本人对sql并不精通,所以捋了一个大致逻辑 首先要得到user表的省市区三个字段的值,我们一般的查询方式是 SELECT province,city,district FROM `user` WHERE id =1;
-
sql查询结果列拼接成逗号分隔的字符串方法
背景:做SQL查询时会经常需要,把查询的结果拼接成一个字符串. 解决方法: 通过group_concat函数 拼接的结果很长,导致拼接结果显示不全,可以通过以下方法解决. 在每次查询前执行SET SESSION group_concat_max_len = 10240; 或者SET GLOBALgroup_concat_max_len = 10240; 使得查询结果值变大. 补充:SQL server 的 拼接SQL如下: selectstuff(( select ','+ requestid
-
MySQL中基本的多表连接查询教程
一.多表连接类型 1. 笛卡尔积(交叉连接) 在MySQL中可以为CROSS JOIN或者省略CROSS即JOIN,或者使用',' 如: 由于其返回的结果为被连接的两个数据表的乘积,因此当有WHERE, ON或USING条件的时候一般不建议使用,因为当数据表项目太多的时候,会非常慢.一般使用LEFT [OUTER] JOIN或者RIGHT [OUTER] JOIN 2. 内连接INNER JOIN 在MySQL中把I SELECT * FROM table1 CROSS JOIN tabl
-
mysql explain的用法(使用explain优化查询语句)
首先我来给一个简单的例子,然后再来解释explain列的信息. 表一:catefory 文章分类表: CREATE TABLE IF NOT EXISTS `category` ( `id` smallint(5) unsigned NOT NULL AUTO_INCREMENT, `name` varchar(50) NOT NULL DEFAULT '', PRIMARY KEY (`id`) ) ENGINE=MyISAM INSERT INTO `test`.`category` VAL
-
mysql处理海量数据时的一些优化查询速度方法
由于在参与的实际项目中发现当mysql表的数据量达到百万级时,普通SQL查询效率呈直线下降,而且如果where中的查询条件较多时,其查询速度简直无法容忍.曾经测试对一个包含400多万条记录(有索引)的表执行一条条件查询,其查询时间竟然高达40几秒,相信这么高的查询延时,任何用户都会抓狂.因此如何提高sql语句查询效率,显得十分重要.以下是网上流传比较广泛的30种SQL查询语句优化方法: 1.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描. 2.对查询
-
MySQL实现树状所有子节点查询的方法
本文实例讲述了MySQL实现树状所有子节点查询的方法.分享给大家供大家参考,具体如下: 在Oracle 中我们知道有一个 Hierarchical Queries 通过CONNECT BY 我们可以方便的查了所有当前节点下的所有子节点.但很遗憾,在MySQL的目前版本中还没有对应的功能. 在MySQL中如果是有限的层次,比如我们事先如果可以确定这个树的最大深度是4, 那么所有节点为根的树的深度均不会超过4,则我们可以直接通过left join 来实现. 但很多时候我们无法控制树的深度.这时就需要
-
MySQL使用命令创建、删除、查询索引的介绍
MySQL数据库表可以创建.查看.重建和删除索引,索引可以提供查询速度.索引根据分类,分为普通索引和唯一索引:有新建索引.修改索引和删除.但是索引不是到处都可以创建,需要根据具体的条件.下面利用实例说明索引创建到销毁的过程,操作如下: 熟悉使用MySQL命令可以方便灵活地执行各种数据库操作:本文主要是对如何使用命令操作MySQL索引,包括创建索引.重建索引.查询索引.删除索引的操作.以下所列示例中的 `table_name` 表示数据表名,`index_name` 表示索引名,column li
-
浅谈MySQL使用笛卡尔积原理进行多表查询
MySQL的多表查询(笛卡尔积原理) 先确定数据要用到哪些表. 将多个表先通过笛卡尔积变成一个表. 然后去除不符合逻辑的数据(根据两个表的关系去掉). 最后当做是一个虚拟表一样来加上条件即可. 注意:列名最好使用表别名来区别. 笛卡尔积 Demo: 左,右连接,内,外连接 l 内连接: 要点:返回的是所有匹配的记录. select * from a,b where a.x = b.x ////内连接 l 外连接有左连接和右连接两种. 要点:返回的是所有匹配的记录 外加 每行主表外键值为null的
-
浅析MySQL 主键使用数字还是uuid查询快
在实际开发中mysql的主键不能重复,可能会采用主键自增,为了防止主键重复也可能会采取雪花算法之类的算法保证,这两种主键保存的都是number类型 但是实际开发中可能会生成uuid作为主键那么疑问来了,到底哪种主键的效率高呢? 下面由测试来验证: 1.首先我们先创建一个表,用存储过程生成100w条数据然后分析: 创建表: CREATE TABLE `my_tables` ( `id` VARCHAR(32) NOT NULL , `name` varchar(32) DEFAULT NULL,