Java服务器宕机的解决方法论
1 宕机概要
1.1 定义
向服务器的请求都没有响应或者响应非常慢。
前端界面的崩溃并非宕机。
1.2 分类
进程闪退
- 内部崩溃
- 外部终止
线程锁死或者无限等待
内存溢出
下面分别进行详解
2 进程闪退
2.1 内部崩溃
JVM 发生内部崩溃,必然会生成"hs_err_pid"开头的文件。
下面讲一种常见情况:
无法申请内存,显示commit_memory错误
Current thread (0x00007f3e40013000): JavaThread "Unknown thread" [_thread_in_vm, id=11408, stack(0x00007f3e49983000,0x00007f3e49a84000)] Stack: [0x00007f3e49983000,0x00007f3e49a84000], sp=0x00007f3e49a82360, free space=1020k Native frames: (J=compiled Java code, j=interpreted, Vv=VM code, C=native code) V [libjvm.so+0x9a32da] VMError::report_and_die()+0x2ea V [libjvm.so+0x497f7b] report_vm_out_of_memory(char const*, int, unsigned long, char const*)+0x9b V [libjvm.so+0x81fcce] os::Linux::commit_memory_impl(char*, unsigned long, bool)+0xfe V [libjvm.so+0x820219] os::pd_commit_memory(char*, unsigned long, unsigned long, bool)+0x29 V [libjvm.so+0x819faa] os::commit_memory(char*, unsigned long, unsigned long, bool)+0x2a V [libjvm.so+0x99eae9] VirtualSpace::expand_by(unsigned long, bool)+0x1c9 V [libjvm.so+0x99ec6d] VirtualSpace::initialize(ReservedSpace, unsigned long)+0xcd V [libjvm.so+0x57962f] CardGeneration::CardGeneration(ReservedSpace, unsigned long, int, GenRemSet*)+0x11f V [libjvm.so+0x46ceed] ConcurrentMarkSweepGeneration::ConcurrentMarkSweepGeneration(ReservedSpace, unsigned long, int, CardTableRS*, bool, FreeBlockDictionary<FreeChunk>::DictionaryChoice)+0x5d V [libjvm.so+0x57a906] GenerationSpec::init(ReservedSpace, int, GenRemSet*)+0x106 V [libjvm.so+0x56afe4] GenCollectedHeap::initialize()+0x344 V [libjvm.so+0x9751aa] Universe::initialize_heap()+0xca V [libjvm.so+0x976379] universe_init()+0x79 V [libjvm.so+0x5b1d25] init_globals()+0x65 V [libjvm.so+0x95dc6d] Threads::create_vm(JavaVMInitArgs*, bool*)+0x1ed V [libjvm.so+0x639fe4] JNI_CreateJavaVM+0x74
这一般是因为 Xmx 设置过大,超过系统可用内存,JVM 申请内存失败。
比如服务器总内存32G ,同时运行多个程序,程序 A 配了20GXmx,其他程序也配了20G Xmx ,Linux的交换空间也没有设置,这时候如果其他程序用满20G内存那么服务的可用内存必然低于12G,这时如果Tomcat需要大于12G的内存就很容易发生该错误,直接宕机!
解决方案
- 减少Xmx值使得所有的综合不超过服务器物理内存
- 调整 Xms=Xmx
- 服务器不要运行其他不必要的东西
- 配置一部分swap空间(虚拟内存)
2.2 外部终止
如果找不到"hs_err_pid"开头的文件,那么这个进程的闪退必然是被从外部终止的。
2.2.1 OOMKiller
java长期内存占用过高,系统需要内存使用的时候没有内存,Linux的oomkiller机制会干掉最低优先级的内存
检查 /var/logs/message , /var/logs/dmesg或者对应日期文件,看看有没有类似下面的内容,日志有时间可以判断

2.2.2 SSH注销
检查/var/log/auth.log,/var/log/secure或者对应日期的文件,检查宕机的时间点有没有
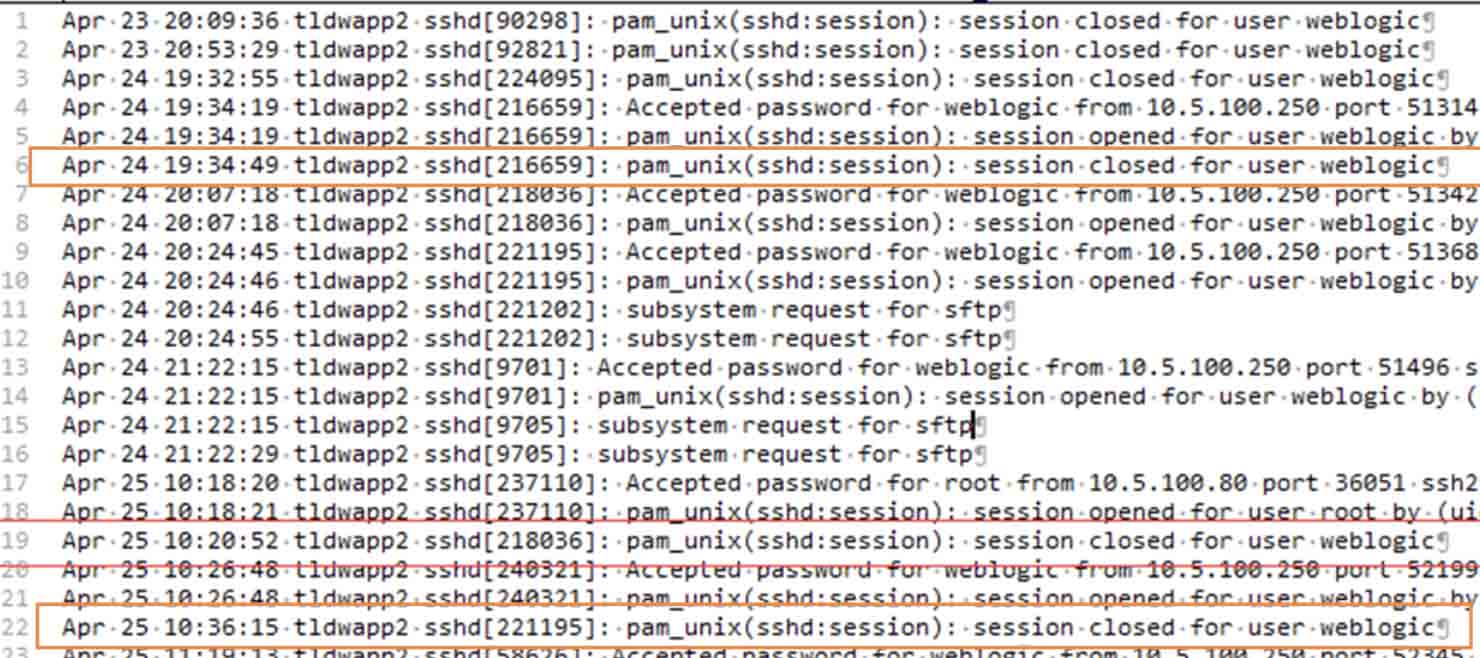
时间吻合,那么宕机原因即可确认。
解决方案
使用nohup命令在后台运行启动程序,检查ssh注销原因
2.2.3 其他人为因素
不是很好判断,需要给shell加上操作记录
3 线程锁死/无限等待
表现
系统无法访问时,当前cpu占用非常低
使用 jstack命令输出线程堆栈即可
jstack pid >> 1.txt or jstack -F pid >> 1.txt
都行,或者用jprofiler工具看堆栈,或者其他任何可以拿到堆栈的工具都可以, java的堆栈就是java方法调用的路径,可以定位一些简单的问题
4 内存溢出
现象
CPU全部占满,内存达到配置Xmx最大值
4.1 CPU占满缘由
并不是 CPU 不够用,而是涉及到JVM的GC 机制,大部分情况来说CPU都是过剩的
JVM 使用GC的方法来回收没有被引用的内存块,在当前的回收机制中,回收器是并发进行的,回收的线程个数有一个公式:
当CPU核心数
小于8
1个核心对应一个gc线程
大于8
gc的线程数= 8 + ((N - 8) * 5/8)
N代表核心的数量,这是默认的gc线程创建公式
threads = N <= 8 ? N : (8 + ((N - 8) * 5/8))
当然也可以通过参数 -XX:ParallelCMSThreads=20 来配置 GC 线程数,就不会使用默认的设置,默认情况下不要调整,因为调了也没什么卵用,最多在宕机的时候cpu占用按照你设定的值来。
当发生内存溢出的时候,或者快要内存溢出的时候,不一定是内存溢出,JVM 发现内存不够了,就会 GC,所有线程开始工作,暂停 JVM 运行,开始回收,如果回收到内存了,ok,jvm可以正确继续执行,
这也就是为什么有时候配置内存溢出的参数没有自动生成dump的原因,因为他能运行,但是比较慢,所以没有OOM,就不会生成dump,
如果没有回收到什么内存,gc会循环持续执行,这就导致了cpu全部占满的现象,所以说内存溢出的时候,一定伴随cpu占满(按照设置或者公式计算的线程量)
4.2 JVM内存分配机制
在说说JVM怎么分配内存的,大家都知道给客户配置Xmx参数和xms参数,Xmx代表的是最大堆内存,xms代表的是最小堆内存,至于permsize就和这些都没有关系,不能算在内存溢出,遇到抛错outofmemory permsize什么的调大就行了
permsize是一个被jvm也抛弃的参数只存在1.7之前的jdk中,是用来保存java的class等内容的存储空间,1.8被metaspace替代
这个内存怎么不回收的啊,一问都是在任务管理器看的!这个地方是看不到内存回收的,或者说他也会回收,但是可能要等个好几天才会回收一次,可以忽略这种机制的存在
形而上学
WC 论
如果把内存比喻成茅坑,操作系统64g内存就是一共64个茅坑,那么JVM的内存回收相当于茅坑调度系统,每个gc线程相当于调度系统派出去的茅坑检查员,给jvm设置了 Xms=2g, Xmx=32g,那么程序启动,jvm直接占了两个茅坑,任务管理器看到内存占用2g,即使没人上厕所,JVM也不会把坑还给操作系统。
假设一个人上厕所10秒,一开始的时候 20秒有一个人来上厕所,那么 jvm通过茅坑检查员发现哎两个坑总有一个是空的,维持茅坑数量不变,内存的占用一直是2g,过了些时候,来的人开始增多了,变成5秒有一个人来上厕所,茅坑检查员向JVM汇报有人开始有排队了,两个坑位很紧张,不行要多弄几个坑才行,于是,jvm向系统又申请了两个坑,任务管理器可以看到内存占用变成了4个G,这时候又突然发生压力增大,变成了1秒来一个人,4个坑肯定不够啊,于是jvm又把内存扩容到10-11g,现在够用了,任务管理器会看到内存一直维持在10-11g,终于大家都上完厕所了,没人排队了,茅坑都空出来了。
但是,jvm是个霸道总裁,被他占的东西,除非死不然不会吐出来的,所以任务管理器里面看到内存还是10-11g不会降低,除非jvm死了,实际没有任何内存占用(所以不要再说内存不回收的问题,这个内存的回收不回收和宕机是没有直接关系的)
如果这时候突然一下子来了很多很多人,比如一下子来了64个人要上厕所,这时候会怎样了,JVM把他的所有的茅坑检查员都派出去检查啊,然后发现完蛋了茅坑不够用啊,申请到32个都不够用啊,于是jvm的特派茅坑检查员就一个坑一个坑的拍,一个坑一个坑的催,结果呢,检查员在催,大家就拉不出来了,上厕所的时间无限期延长,外面的人要进去,里面的人出不来,BOOM,厕所就不响应了,后面来的人都拉裤子了。
怎么解决?
- 换个茅坑管理员,更好的调度茅坑检查员和分配茅坑,这就有了G1回收器 ,茅坑越多效果越好,目前JDK情况内存大于10G的情况G1的效果好于CMS,低于10G的情况下不如CMS
- 从源头控制人员,不要一下子来这么多人(申请内存),也就是常见的不要让业务查大量数据占内存。
而上面讲的线程锁死的情况要做类比的话,就是32个坑呗32个人占了,还死活不肯出来,导致后面排队的人失去响应了。
没有味道的比喻
解释一下java的面向对象和对象引用:
一栋大楼,10层共1000个工位 (类比物理内存)。
包给一个二房东 中介公司Z (jvm)。
中介公司和大楼物业谈好弹性缴费,租多少出去收多少钱。
Z公司先一下租300个位置 (类比Xms)省钱,
Z公司和物业谈好最多租600个位置(类比Xmx)。
Z公司找到了公司A(200人)来这里 就占用了200个工位 (类比一次数据查询)。
公司A是一个大的对象,每个人类比最小的单元格,每个小团队也是一个对象,个人被小团队引用,小团队又被更上级的比如产品,比如大技术支持大团队引用,大团队又被公司引用,最终公司这个大对象占用了200工位,类比下来200个工位内存不释放的根就是这个公司在这儿上班。
这时候公司A倒闭了,200个工位就空出来了(内存释放)。
- 内存溢出宕机是什么情况呢?
- 找Z公司租工位的公司,总工位超过了600,总不能坐大腿上上班啊,于是物业不会给Z工位的,合同写的好好的,Z公司不满足客户需求,运作不起来破产倒闭。
- 经常遇到的申请内存失败的崩溃是什么情况?
- 物业是个滑头,不止找了Z公司一家中介,还有Y公司也是做中介的(类比两个JVM)。都承诺Z和Y公司都是最多可以租600个位置。初始都租的300个位置,大家相处融洽,随着公司不停入住,矛盾出现了:
- Y公司效益比较好,先找了公司,已经占了600位置;
- 这时候Z公司的效益也上来了,也要增加工位 (类比申请内存),这时候物业根本没有位置能给他。于是Z公司运转不下去,破产倒闭
5 总结
宕机分析的目的就是要找到占用内存的东西,把他找出来,找出他的原因,然后把它改掉。JVM的内存对象分配相当于一颗树,所有的对象都被层层引用,直到GCRoot根节点,如果没有根节点的引用,这个对象是完全可以直接释放掉的,大部分也是因为gcRoot存在的对象过多导致的宕机,当然也不排除可以使用已经回收的对象来分析,由于生成dump的时间不精确,可能他生成的时候 ,对应的大组件已经回收了,但是jvm缓过来还需要一些时间,所以还是处于大量gc的状态,这时候只能通过对于引用的检索找到最多的引用对象来进行分析。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Java游戏服务器系列之Netty相关知识总结
一.简介 Java的底层API逐渐复杂,而开发者面对的开发场景需求也在逐渐增大.如果直接针对底层API进行编程,无疑是耗时耗力的.这时就催生了极多的编程框架,这些框架隐藏了API实现的复杂细节,以最简洁的方式给开发人员提供功能的实现接口.Netty就是一款针对于网络链接的框架,他的出现让服务器开发人员更加的集中关注于更多逻辑的实现,而不为了实现更好更多更稳定的链接而头疼.Netty的核心功能基于NIO实现. 二.Netty的应用场景 几乎适用于所有的长短链接场景,由于Java应用的广泛性,几乎所
-

教你怎么用java实现客户端与服务器一问一答
运行效果 开启多个客户端 服务端效果: 客户端效果: 当一个客户端断开连接: 代码 因为代码中有注释,我就直接贴上来了 服务端: package com.dayrain.server; import java.io.IOException; import java.net.InetSocketAddress; import java.net.ServerSocket; import java.nio.ByteBuffer; import java.nio.channels.*; import j
-
java 服务器接口快速开发之servlet详细教程
Servlet简介 servlet是Server Applet的简称,翻译过来就是服务程序.好吧,这么说你可能还是不太懂,简单的讲,这个servlet是运行在服务器上的一个小程序,用来处理服务器请求的.进一步讲,我们知道,一般的网页程序,是由我们通过浏览器访问来实现的,在这个过程中,我们的浏览器发送访问请求,服务器接收请求,并对浏览器的请求作出相应的处理.这就是我们熟悉的B/S模型(浏览器-服务器模型).而servlet就是对请求作出处理的组件,运行于支持Java的应用服务器中. Servlet
-
Java服务器主机信息监控工具类的示例代码
对接前端后效果展示如图: 1.CPU相关信息实体类 /** * CPU相关信息 * * @author csp */ public class Cpu { /** * 核心数 */ private int cpuNum; /** * CPU总的使用率 */ private double total; /** * CPU系统使用率 */ private double sys; /** * CPU用户使用率 */ private double used; /** * CPU当前等待率 */ priv
-
教你利用JAVA实现可以自行关闭服务器的方法
JAVA实现可以自行关闭的服务器 普通实现的服务器都无法关闭自身,只有依靠操作系统来强行终止服务程序.这种强行终止服务程序的方式尽管简单方便,但会导致服务器中正在执行的任务突然中断.如果服务器处理的任务非常重要,不允许被突然中断,应该由服务器自身在恰当的时刻关闭自己 代码如下: EchoServer类 package ShutdownServer; import java.io.*; import java.net.ServerSocket; import java.net.Socket; im
-
Java模拟服务器解析web数据
目录 一,模拟 服务器 解析浏览器发来的数据 二,CSS选择器 三,练习HTML和CSS –1,创建css文件 –2,修改html文件 四,css的盒子模型 –1, 概述 –2,练习 html代码 css代码 五,JS –1,入门案例 –2,基础语法 总结 一,模拟 服务器 解析浏览器发来的数据 package cn.tedu.test; //模拟 服务器 解析浏览器发来的数据 -- SpringMVC框架 //http://127.0.0.1:8848/cgb2105/stu.html?use
-
Java服务器宕机的解决方法论
1 宕机概要 1.1 定义 向服务器的请求都没有响应或者响应非常慢. 前端界面的崩溃并非宕机. 1.2 分类 进程闪退 内部崩溃 外部终止 线程锁死或者无限等待 内存溢出 下面分别进行详解 2 进程闪退 2.1 内部崩溃 JVM 发生内部崩溃,必然会生成"hs_err_pid"开头的文件. 下面讲一种常见情况: 无法申请内存,显示commit_memory错误 Current thread (0x00007f3e40013000): JavaThread "Unknown t
-
Linux中虚拟机宕机之后解决办法
Linux中虚拟机宕机之后解决办法 问题现象 一次意外操作,导致虚拟机无法启动,重启宿主操作系统也无效. 恢复方法 第一步: 删除原来建立的虚拟机. 第二步: 重新建立新虚拟机. 第三步: 在建立虚拟硬盘步骤,选择"使用已有的虚拟硬盘文件",该文件笔者为G:\vmdisk\Centos.vdi,在第一次建立虚拟机安装虚拟操作系统时时会创建该文件. 界面如下: 第四步: 虚拟机建立完成后,即可正常. 注意事项 1.定期备份G:\vmdisk\Centos.vdi虚拟硬盘文件是一个好习惯,
-
MySQL的一条慢SQL查询导致整个网站宕机的解决方法
直接切入正题吧: 通常来说,我们看到的慢查询一般还不致于导致挂站,顶多就是应用响应变慢 不过这个恰好今天被我撞见了,一个慢查询把整个网站搞挂了 先看看这个SQL张撒样子: # Query_time: 70.472013 Lock_time: 0.000078 Rows_sent: 7915203 Rows_examined: 15984089 Rows_affected: 0 # Bytes_sent: 1258414478 use js_sku; SET timestamp=146585011
-
tomcat服务器宕机解决方案
报错信息: java.lang.Object.wait(Native Method) java.lang.ref.ReferenceQueue.remove(ReferenceQueue.java:143) com.mysql.jdbc.AbandonedConnectionCleanupThread.run(AbandonedConnectionCleanupThread.java:43) 每次出现这个报错都会导致tomcat应用服务器停机,加了下面的java代码后就再也没有停过了. 解决办法
-
Oracle备库宕机启动的完美解决方案
简介 ORA-10458: standby database requires recovery ORA-01196: 文件 1 由于介质恢复会话失败而不一致 ORA-01110: 数据文件 1: 'XXXXXXXXXXXXXXXXXX\XXXXX1.DBF' 一个项目做了Oracle主从数据库同步,通过Dataguard实现,从库服务器宕机,再开机的时候,从库无法启动,报"ORA-01196: 文件 1 由于介质恢复会话失败而不一致"这个错误,具体日志信息如下: ORA-10458:
-
解决java web应用线上系统偶发宕机的情况
前言: 事情是酱紫的,系统上线两个月后,风平浪静.在一个秋天宁静的下午,老衲正喝着茶听着歌敲着代码,顺便欣赏下妹纸,独享这难得的惬意.突然手机响了,一看来电,心中一沉,项目经理来电,必有蹊跷.匆忙接起电话,没有问候,直奔主题,"赶紧看下系统,个别客户反馈系统不能用了,先恢复系统,再排查问题". 老衲撂下电话,一哆嗦,赶紧连上VPN,直奔服务器主机. PS:三台服务器(centos.128G内存.32核CPU),tomcat1.7,jdk1.8,通过F5负载 解决步骤: 1.top命令查
-
记一次springboot服务凌晨无故宕机问题的解决
表述 在一次服务更新后发现每天凌晨0点3秒服务准时挂,开始的时候认为是maven依赖中存在system.exit(3)类似这样的代码,但是我想了下这个代码很多客户都有用到但是只有这一个客户出现了问题,而且另外一个服务没有更新在此前几个月都是没问题的 这几天也是一样无故挂了. 环境 windows服务器 排查 1.初步怀疑是内存泄漏问题,在启动脚本中加入 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=D:\heapdump.log,第二天起来一看
-
Java应用/JVM宕机排查步骤操作
相信大家都遇到过,自己的Java应用运行一段时间就宕机了或者响应请求特别慢.这时候就需要我们了来找出问题所在了.绝大部分都是代码问题导致的. 一.服务宕机 如果是服务宕机,发生致命问题导致进程已经死掉了,那么已经访问不了了,通常都是CPU问题引起的,程序一般会自己生成javacore文件,一般生成位置在/root目录或jar包同目录下.JavaCore文件主要保存的是Java应用各线程在某一时刻的运行的位置,即JVM执行到哪一个类.哪一个方法.哪一个行上. 找到这个文件,执行命令 gdb jav
-
PHP脚本内存泄露导致Apache频繁宕机解决方法
在部署一套内网测试环境时,频繁宕机,开机后不断的吃内存,重启apache之后内存占用会不停的上涨,直到swap用完,直到死机,由于是内网环境,服务器并发和压力都很小. 查看apache错误日志,报大量类似错误: 复制代码 代码如下: [Tue Feb 14 14:49:28 2012] [warn] child process 7751 still did not exit, sending a SIGTERM [Tue Feb 14 14:49:30 2012] [error] child p
-
JAVA实现监测tomcat是否宕机及控制重启的方法
本文实例讲述了JAVA实现监测tomcat是否宕机及控制重启的方法.分享给大家供大家参考.具体如下: Detector.java: import java.net.URL; import java.net.URLConnection; import java.util.Date; /** * * @author james * */ public class Detector { private static void keepTomcatAlive() throws NullPointerEx